来自:blog.csdn.net/weixin_42942532/article/details/88951915一、生产者
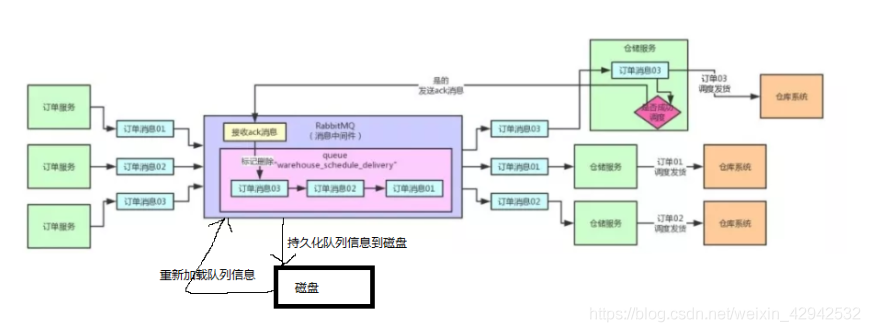
此时已经可以保证消费者出现宕机,可以保证消息不丢失.Q: 当订单服务发送一条消息到rabbitMQ, rabbitMQ成功接收到了消息并保存在内存中, 但是在仓储服务没有拿走此消息之前, rabbitMQ宕机了. 怎么办?A:此问题需要考虑消息持久化(durable机制), 通过设置队列的durable参数为true, 则当rabbitMQ重启之后, 会恢复之前的队列. 它的工作原理是rabbitMQ会把队列的相关信息持久化到磁盘. 代码如下:/**
* queue : 当前操作的队列. 设置队列名称即可
* durable: 当前队列是否开启持久化. 如果为true.当前mq服务重启之后,队列仍然存在
* exclusive: 当前队列是否独占此连接
* autoDelete: 当前队列是否自动删除
* arguments: 队列参数
*/
channel.queueDeclare(QUEUE,true,false,false,null);
此时当rabbitMQ重启,则会恢复之前的存在的队列.A: 虽然队列可以恢复,但是按照当前的设置,队列中未消费的消息是不会恢复的. 如果也要一并恢复消息,则需要设置队列中的消息持久化. 代码如下:/**
* exchange: 交换机. 对于当前操作使用默认交换机 ""
* routingKey: 路由key. 如果当前使用默认交换机, routingKey的值就是当前队列的名称
* props: 参数
* body: 消息体
*/
String message = "hello rabbitmq";
channel.basicPublish("",QUEUE, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
通过第三个参数的设置,可以对发送出去的消息进行持久化设置. 工作方式是将消息写入到磁盘.当rabbitMQ重启,则在恢复队列的同时也会一并恢复队列中之前未被消费的消息.此时需要注意: 对于此种方式是不能保证消息的百分百不丢失的. 因为rabbitMQ有可能在没有来得及写入磁盘的时候, 服务器就宕机了. 此时消息一样也会丢失. 如果要完全100%保证写入RabbitMQ的数据必须落地磁盘,不会丢失,需要依靠其他的机制。二、消费者
1. 业务场景定义
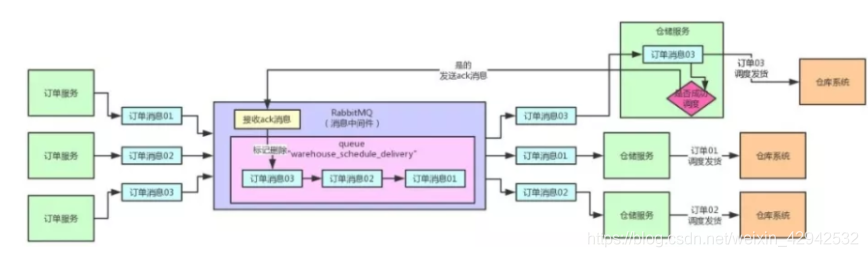
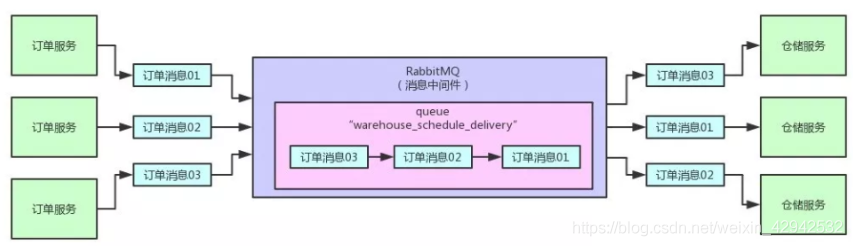
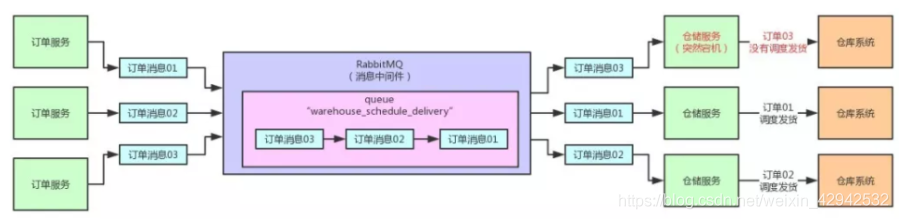
如上图,正常的消息队列的工作方式, 是可以通过rabbitMQ的workQueues或者routing或者topics进行实现的. 对于消息生产者采用集群部署,用于进行高可用, 消费方部署集群保证保证高可用的同时,也可以提高系统的TPS与QPS. 这也是最基础的使用2. 问题场景描述
2.1 消费者服务宕机
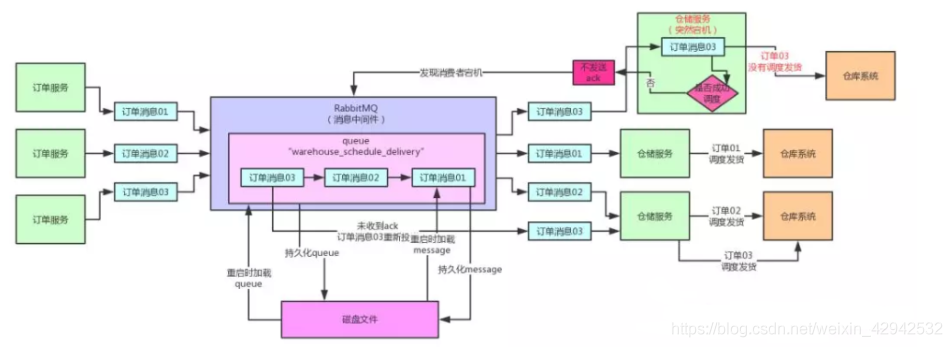
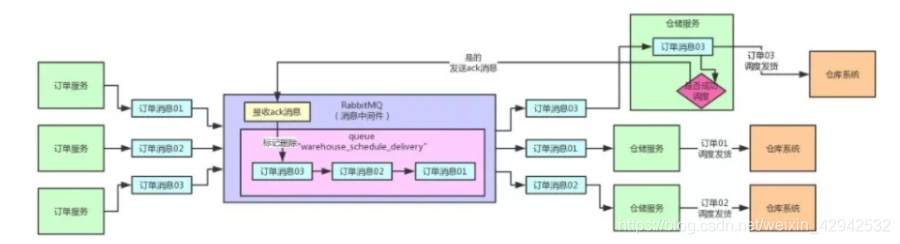
Q: 仓储服务在接收到一条订单消息之后, 并对此条消息没有处理完之前,突然宕机了. 换句话说, 仓储服务在接收到订单消息之后, 仓储服务调用发货系统之前, 仓储服务宕机了. 这个时候应该怎么办?A: rabbitMQ默认操作是当消费者成功接收到消息之后,rabbitMQ则会自动的在队列中将此条消息删除. 这种操作称为自动ACK(自动回复). 代码设置如下:/**
* queue : 队列名称
* autoAck: 是否自动应答
*callback: 消费者
*/
channel.basicConsume(QUEUE_INFORM_EMAIL,true,consumer);
在此段代码中, 第二个参数:autoAck.则为设置自动应答方式. 如果为true.则会当消费者接收到消息后,自动删除消息队列中的这条消息. 代表这条消息已经投递完毕了.但是此时,如果按照这种工作方式, 当消费者(仓储服务)接收到消息(订单消息),消息队列自动把这条消息(订单消息)删除了, 但是仓储服务在还没有调用发货系统之前宕机了. 那很明显,这条消息(订单消息)就丢失了. 这是绝对不可以忍受的!!!!!!!举例: 用户在前端系统下了一个订单, 这条订单基于订单服务保存成功,提示用户已经下单成功,用户就等着收货, 等了好几天都不发货. 因为什么? 因为仓储服务在接收到订单消息之后, 突然宕机了. 那么消息队列中没有了这个订单消息, 仓储服务也没有去调用发货系统. 所以这个订单就卡这了.
那此时我们要对这个问题进行解决. 核心痛点就在于autoAck这个参数. 需要将此参数设置为false. 当此参数设置为false. 那么当消费者接收到这个消息之后,消息队列也不会马上删除这条消息. 对于我们开发人员要做的就是只有仓储服务执行完毕并调用成功发货之后才会向消息对返回一条确认消息,当消息队列接收到这条消息之后才删除订单消息. 核心代码如下:DefaultConsumer consumer = new DefaultConsumer(finalChannel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String value = new String(body,"utf-8");
System.out.println("开始调用发货功能!!!!!");
System.out.println("根据发货功能结果进行判断");
if (true){
//发货成功
//通知消息队列删除此消息
finalChannel.basicAck(envelope.getDeliveryTag(),false);
}
}
};
channel.basicConsume(QUEUE,false,consumer);
按照这个流程改造了之后, 可以确保仓储服务在成功调用了发货功能之后才会通知消息队列删除这条订单消息, 从而确保了不会因为上述描述的问题而导致订单消息丢失.Q:如果一旦消费者宕机了, 那么这个订单消息不就卡在消息队列了么?A: 对于当前的架构设计. 仓储服务是以集群方式部署. 会存在多个仓储服务的实例. 对于rabbitMQ来说, 如果一旦发现某个仓储服务宕机了. 那么就会将这个订单消息发送给其他的仓储服务实例去使用这条消息.Q:如果其他仓储实例调用完了此订单消息,但是刚才的仓储服务又重新启动了,那因为它刚才已经接收到了消息,它又去根据这个订单消息去调用发货功能,但是其他仓储服务已经用完了这个订单消息, 怎么办?A: 此问题无需考虑. 因为仓储服务只是一个消费者, 它只会去持续监听消息队列,拿消息进行使用.而不会对消息进行存储.所以该问题不会发生.A: 消费者实例已经注册到了rabbitMQ, 所以rabbitMQ与消费者实例是存在联系的,当消费者实例宕机,rabbitMQ必然会知道Q:当rabbitMQ感知到某一个消费者实例宕机,它是如何进行消息重发的?DefaultConsumer consumer = new DefaultConsumer(finalChannel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String value = new String(body,"utf-8");
try{
//调用发货
}
catch(Exception e){
//异常处理
}
finally{
//通知消息队列删除此消息
finalChannel.basicAck(envelope.getDeliveryTag(),false);
}
}
};
channel.basicConsume(QUEUE,false,consumer);
当消费者实例在处理消息的过程中, 出现了异常怎么办? 这个时候是一定不能通知MQ服务消息消费成功了, 否则消息不是就又丢了么!!. 在catch中,需要做的是通知MQ服务此条消息没有处理成功,让MQ将这个消息交给其他消费者实例进行处理. 具体实现如下:DefaultConsumer consumer = new DefaultConsumer(finalChannel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String value = new String(body,"utf-8");
try{
//调用发货
}
catch(Exception e){
//异常处理
//第一个参数: 消息表示信息
//第二个参数:通知MQ服务当前消费者实例没有处理成功,让MQ服务将这个消息重新投递给其他消费者实例
//如果设置为了false,会导致就算MQ服务知道当前消费者实例没有处理成功, 但是依旧会删除这个消息.
channel.basicNack(envelope.getDeliveryTag(),true)
}
finally{
//通知消息队列删除此消息
finalChannel.basicAck(envelope.getDeliveryTag(),false);
}
}
};
channel.basicConsume(QUEUE,false,consumer);
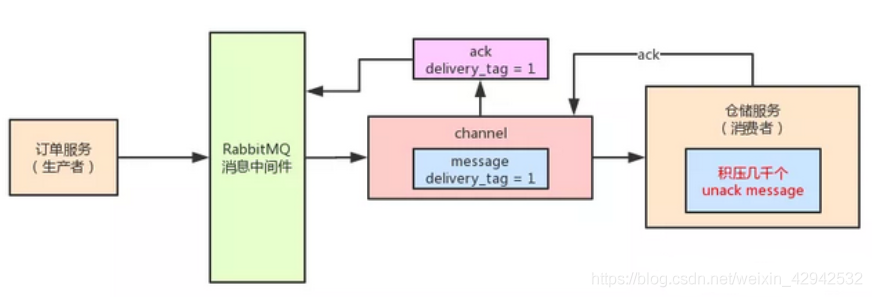
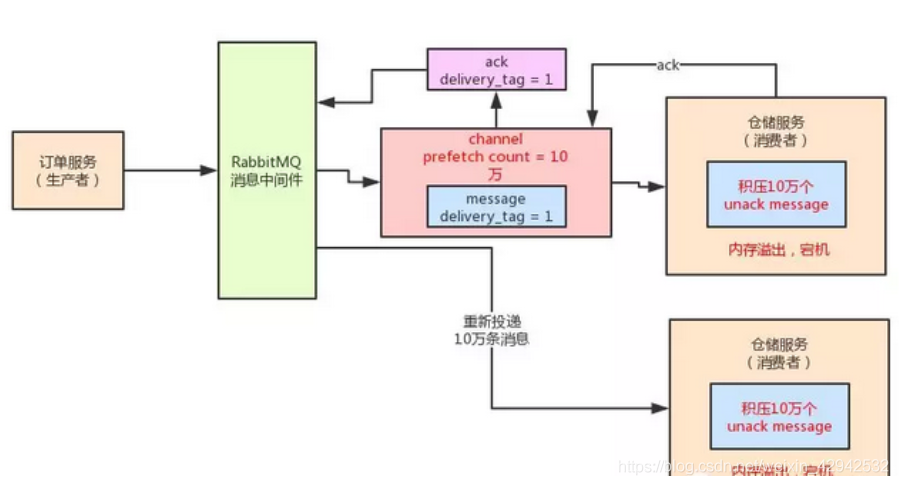
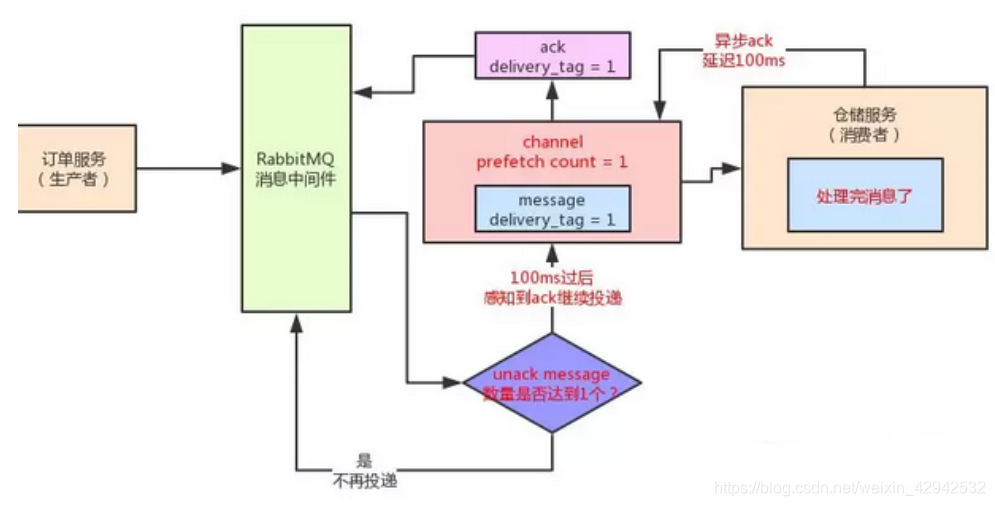
Q:基于ack机制,结合高并发场景会出现什么问题?A: 对于当前的操作, 每一个channel都会存在若干的unack消息(未确认消息). 比方说, rabbitMQ正在发送的消息 、 消费者实例接收到消息之后但没有处理完 、 执行了ack但是因为ack是异步的也不会马上变为ack信息 、 开始批量ack延迟时间会更长.对于这些场景,都会存在unack的消息. 此时如果rabbitMQ无限制的过多过快的向消费者实例发送消息,就会导致庞大的unack消息积压在消费者实例的内存中,如果继续保持发与积压的状态,最终会导致消费者实例的oom!!.此时需要考虑消费者实例的处理能力以及如何解决unack消息积压的问题.rabbitMQ基于 prefetch count(预抓取总数)控制每一个channel的unack消息的数量,代码如下:channel.basicQos(10)//设置预抓取消息总数为10
这个方法一旦执行,相当于设置当前的channel里,对于unack消息总数不能超过10条.( rabbitMQ正在发送的消息 、 消费者实例接收到消息之后但没有处理完 、 执行了ack但是因为ack是异步的也不会马上变为ack信息 、 开始批量ack延迟时间会更长等等这类unack消息的总数) , 当一个channel中的unack消息超过十条之后, rabbitMQ则会停止向这个消费者实例投递消息, 等待unack消息总数小于10 或者 将消息转发给其他的消费者实例.此时需要结合高并发场景考虑prefetch count的值设置多大合适.当前的这个值设置过大或者过小都会出问题. 过大可能导致系统雪崩, 过小导致系统吞吐量过低,响应速度低.过大: 在高并发场景下, 可能每秒都会几千上万条消息. 如果仍旧把prefetch count 设置过大超出了消费者实例内存的处理能力, 消费者实例可能瞬间就崩溃, 然后rabbitMQ感知到当前消费者实例宕机,则会将这些消息交给其他消费者实例,然后后面的消费者实例也崩溃, 最终导致系统雪崩.举个例子. 你给当前消费者实例的prefetch count设置为10W. 那么在消费者实例中就可以存在10W条unack的消息,超出了消费者实例的内存容量, 直接OOM. 最终所有消费者实例全部OOM过小: 如果设置过小,会导致系统的消息吞吐量降低,影响系统性能. 因为执行ack方法是异步的 . 举例. 将prefetch count 设置为1. 则rabbitMQ最终投递给消费者实例一条unack消息. 当消费者实例消费者这条信息,并执行了ack方法, 因为该方法需要异步执行. 比方说需耗时300ms才能成功通知到rabbitMQ. 那么当经过了300ms之后, rabbitMQ才会再发出另外一条消息. 速度可想而知的慢!!! 这种操作可能导致当前系统消息吞吐量下降千倍都是有可能的.对于上述问题. 官网给出的建议是设置在100~300之间. 但是在实际生产环境下, 具体环境需要具体确定.推荐阅读:
通过 Java 技术手段,获取女朋友定位地址 ...
Tomcat 组成与工作原理
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点个「在看」,点击上方小卡片,进入公众号后回复「面试题」领取,更多内容陆续奉上。朕已阅