
CTO 说了,如果发现谁用 SELECT * 查询直接开除
共 3225字,需浏览 7分钟
·
2021-03-16 21:15
点击上方蓝色字体,选择“设置星标”
优质文章,第一时间送达

来源:blog.csdn.net/qq_39390545/article/details/106766965
面试官:“小陈,说一下你常用的SQL优化方式吧。”
陈小哈:“那很多啊,比如不要用SELECT *,查询效率低。巴拉巴拉...”面试官:“为什么不要用SELECT * ?它在哪些情况下效率低呢?”
陈小哈:“SELECT * 它好像比写指定列名多一次全表查询吧,还多查了一些无用的字段。”面试官:“嗯...”
陈小哈:“emmm~ 没了”陈小哈:“....??(几个意思)”
面试官:“嗯...好,那你还有什么要问我的么?”
陈小哈:“我问你个锤子,把老子简历还我!”
无论在工作还是面试中,关于SQL中不要用“SELECT *”,都是大家听烂了的问题,虽说听烂了,但普遍理解还是在很浅的层面,并没有多少人去追根究底,探究其原理。
废话不多说,本文带你深入了解一下"SELECT * "效率低的原因及场景。
本文很干!请自备茶水,没时间看记得先收藏 -- 来自一位被技术经理毒打多年的程序员的忠告
目录
一、效率低的原因
1. 不需要的列会增加数据传输时间和网络开销
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
二、索引知识延申
● 联合索引 (a,b,c)
● 联合索引的优势
1) 减少开销
2)覆盖索引
3)效率高
● 索引是建的越多越好吗
三、心得体会
一、效率低的原因
先看一下最新《阿里java开发手册(泰山版)文末有本书的下载链接》中 MySQL 部分描述:
4 - 1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:
增加查询分析器解析成本。
增减字段容易与 resultMap 配置不一致。
无用字段增加网络 消耗,尤其是 text 类型的字段。
开发手册中比较概括的提到了几点原因,让我们深入一些看看:
1. 不需要的列会增加数据传输时间和网络开销
用“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
增大网络开销;* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。如果DB和应用程序不在同一台机器,这种开销非常明显
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
例如,有一个表为t(a,b,c,d,e,f),其中,a为主键,b列有索引。
那么,在磁盘上有两棵 B+ 树,即聚集索引和辅助索引(包括单列索引、联合索引),分别保存(a,b,c,d,e,f)和(a,b),如果查询条件中where条件可以通过b列的索引过滤掉一部分记录,查询就会先走辅助索引,如果用户只需要a列和b列的数据,直接通过辅助索引就可以知道用户查询的数据。
如果用户使用select *,获取了不需要的数据,则首先通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询,速度必然会慢很多。
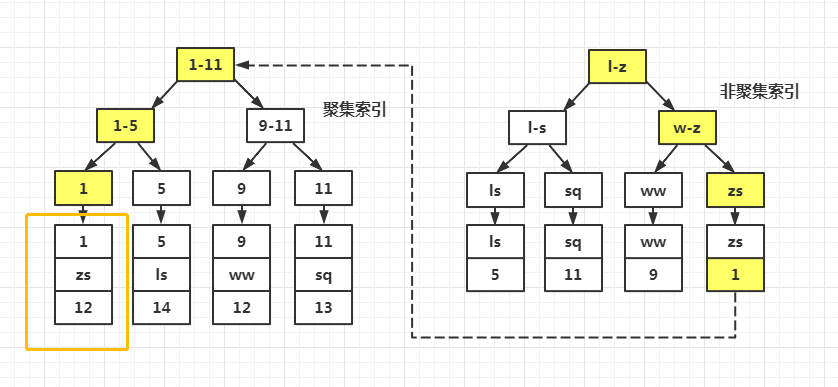
由于辅助索引的数据比聚集索引少很多,很多情况下,通过辅助索引进行覆盖索引(通过索引就能获取用户需要的所有列),都不需要读磁盘,直接从内存取,而聚集索引很可能数据在磁盘(外存)中(取决于buffer pool的大小和命中率),这种情况下,一个是内存读,一个是磁盘读,速度差异就很显著了,几乎是数量级的差异。

二、索引知识延申
上面提到了辅助索引,在MySQL中辅助索引包括单列索引、联合索引(多列联合),单列索引就不再赘述了,这里提一下联合索引的作用
联合索引 (a,b,c)
联合索引 (a,b,c) 实际建立了 (a)、(a,b)、(a,b,c) 三个索引
我们可以将组合索引想成书的一级目录、二级目录、三级目录,如index(a,b,c),相当于a是一级目录,b是一级目录下的二级目录,c是二级目录下的三级目录。要使用某一目录,必须先使用其上级目录,一级目录除外。
如下:

联合索引的优势
1) 减少开销
建一个联合索引 (a,b,c) ,实际相当于建了 (a)、(a,b)、(a,b,c) 三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2)覆盖索引
对联合索引 (a,b,c),如果有如下 sql 的,
SELECT a,b,c from table where a='xx' and b = 'xx';
那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 io 操作。减少 io 操作,特别是随机 io 其实是 DBA 主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3)效率高
索引列多,通过联合索引筛选出的数据越少。比如有 1000W 条数据的表,有如下SQL:
select col1,col2,col3 from table where col1=1 and col2=2 and col3=3;
假设:假设每个条件可以筛选出 10% 的数据。
A. 如果只有单列索引,那么通过该索引能筛选出 1000W10%=100w 条数据,然后再回表从 100w 条数据中找到符合 col2=2 and col3= 3 的数据,然后再排序,再分页,以此类推(递归);
B. 如果是(col1,col2,col3)联合索引,通过三列索引筛选出 1000w10% 10% *10%=1w,效率提升可想而知!
索引是建的越多越好吗
答案自然是否定的
数据量小的表不需要建立索引,建立会增加额外的索引开销
不经常引用的列不要建立索引,因为不常用,即使建立了索引也没有多大意义
经常频繁更新的列不要建立索引,因为肯定会影响插入或更新的效率
数据重复且分布平均的字段,因此他建立索引就没有太大的效果(例如性别字段,只有男女,不适合建立索引)
数据变更需要维护索引,意味着索引越多维护成本越高。
更多的索引也需要更多的存储空间
三、心得体会
相信能看到这里这老铁要么是对MySQL有着一腔热血的,要么就是喜欢滚鼠标的。来了就是缘分,如果从本文学到了东西,请不要吝啬手中的赞哦,拒绝白嫖~
有朋友问我,你对SQL规范那么上心,平时你写代码不会用SELECT * 吧?
咋可能啊,天天用。。代码里也在用(一脸羞愧),其实我们的项目普遍很小,数据量也上不去,性能上还没有遇到瓶颈,所以比较放纵。
写本篇文章主要是这个知识点网上总结的很少很散,也不规范,算是给自己也是给大家总结一份比较详细的,值得记一下的。以后给面试官说完让他没法找你茬。
顺便吹波牛B,谢谢各位。
