
重参系列 | 轻量化模型+重参技术是不是可以起飞?
1、开篇小记
1.1、知识点1
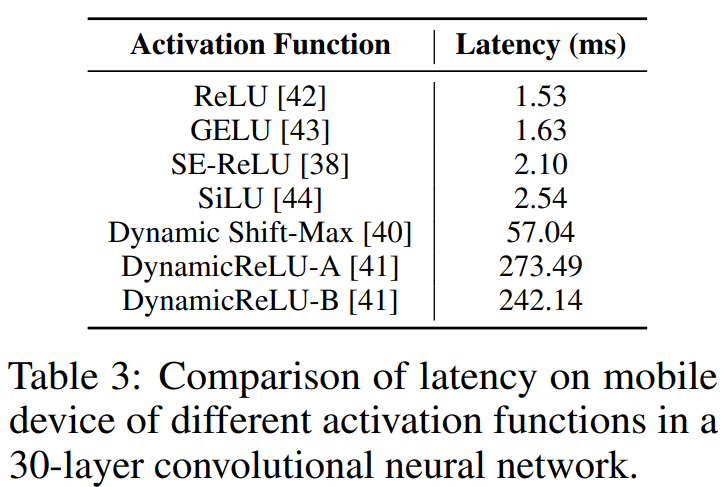
相同的架构,不同激活函数带来的延迟差异极大。这里Mobileone选择的是使用ReLU。
1.2、知识点2
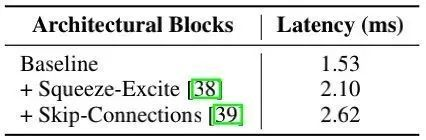
当采用单分支结构时,模型具有更快的速度。这个在RepVGG时就已经知道了,这里读者可以参考RepVGG笔记。
2、MobileOne 简述
MobileOne 的核心模块基于 MobileNetV1 而设计,同时吸收了重参数思想,得到上图所示的结构。注:这里的重参数机制还存在一个超参k用于控制重参数分支的数量(实验表明:对于小模型来说,该变种收益更大)。
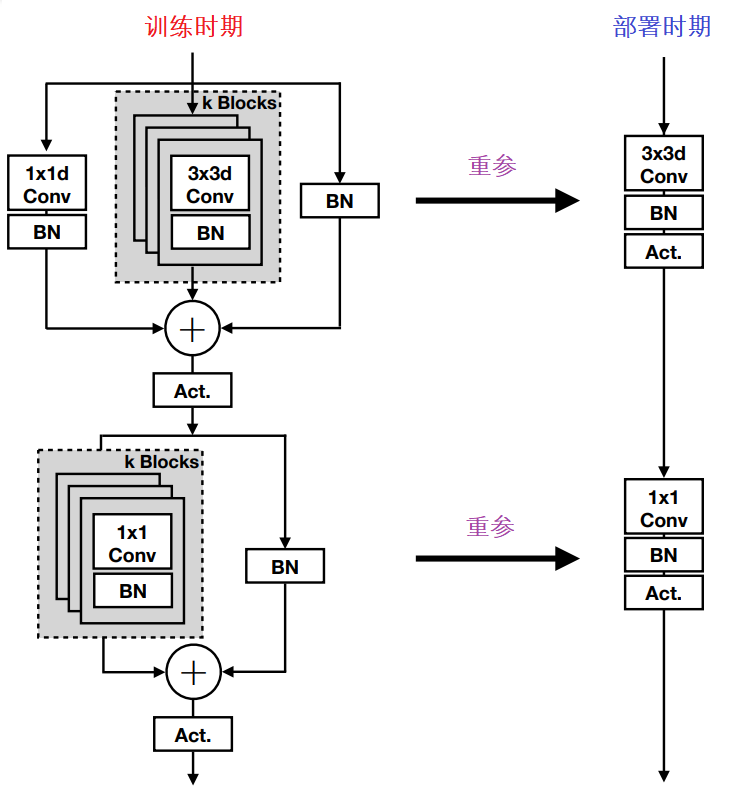
通过上图,如果你愿意,其实就是DBB+RepVGG的结合,而分支数你可以随意的扩宽,重参的化直接进行weight与bias的合并即可。
3、MobileOne 的实现
以下是 MobileOne 的Pytorch实现:
from typing import Optional, List, Tuple
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
class MobileOneBlock(nn.Module):
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
inference_mode: bool = False,
use_se: bool = False,
num_conv_branches: int = 3) -> None:
super(MobileOneBlock, self).__init__()
self.inference_mode = inference_mode
self.groups = groups
self.stride = stride
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.num_conv_branches = num_conv_branches
# Check if SE-ReLU is requested
self.se = nn.Identity()
self.activation = nn.ReLU()
if inference_mode:
self.reparam_conv = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True)
else:
# skip connection
self.rbr_skip = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
# 3x3 conv branches
rbr_conv = list()
for _ in range(self.num_conv_branches):
rbr_conv.append(self._conv_bn(kernel_size=kernel_size, padding=padding))
self.rbr_conv = nn.ModuleList(rbr_conv)
# 1x1 conv branch(scale branch)
self.rbr_scale = None
if kernel_size > 1:
self.rbr_scale = self._conv_bn(kernel_size=1, padding=0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
if self.inference_mode:
return self.activation(self.se(self.reparam_conv(x)))
identity_out = 0
if self.rbr_skip is not None:
identity_out = self.rbr_skip(x)
# Scale branch output
scale_out = 0
if self.rbr_scale is not None:
scale_out = self.rbr_scale(x)
# Other branches
out = scale_out + identity_out
for ix in range(self.num_conv_branches):
out += self.rbr_conv[ix](x)
return self.activation(self.se(out))
def reparameterize(self):
if self.inference_mode:
return
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(in_channels=self.rbr_conv[0].conv.in_channels,
out_channels=self.rbr_conv[0].conv.out_channels,
kernel_size=self.rbr_conv[0].conv.kernel_size,
stride=self.rbr_conv[0].conv.stride,
padding=self.rbr_conv[0].conv.padding,
dilation=self.rbr_conv[0].conv.dilation,
groups=self.rbr_conv[0].conv.groups,
bias=True)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_conv')
self.__delattr__('rbr_scale')
if hasattr(self, 'rbr_skip'):
self.__delattr__('rbr_skip')
self.inference_mode = True
def _get_kernel_bias(self) -> Tuple[torch.Tensor, torch.Tensor]:
# 获取scale分支的卷积核bias
kernel_scale = 0
bias_scale = 0
if self.rbr_scale is not None:
kernel_scale, bias_scale = self._fuse_bn_tensor(self.rbr_scale)
# 将scale分支Pad为卷积分支
pad = self.kernel_size // 2
kernel_scale = torch.nn.functional.pad(kernel_scale, [pad, pad, pad, pad])
# 获取 skip 分支的权重
kernel_identity = 0
bias_identity = 0
if self.rbr_skip is not None:
kernel_identity, bias_identity = self._fuse_bn_tensor(self.rbr_skip)
# 获取卷积分支的权重
kernel_conv = 0
bias_conv = 0
for ix in range(self.num_conv_branches):
_kernel, _bias = self._fuse_bn_tensor(self.rbr_conv[ix])
kernel_conv += _kernel
bias_conv += _bias
kernel_final = kernel_conv + kernel_scale + kernel_identity
bias_final = bias_conv + bias_scale + bias_identity
return kernel_final, bias_final
def _fuse_bn_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = torch.zeros((self.in_channels,
input_dim,
self.kernel_size,
self.kernel_size),
dtype=branch.weight.dtype,
device=branch.weight.device)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, self.kernel_size // 2, self.kernel_size // 2] = 1
self.id_tensor = kernel_value
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _conv_bn(self, kernel_size: int, padding: int) -> nn.Sequential:
mod_list = nn.Sequential()
mod_list.add_module('conv', nn.Conv2d(in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=kernel_size,
stride=self.stride,
padding=padding,
groups=self.groups,
bias=False))
mod_list.add_module('bn', nn.BatchNorm2d(num_features=self.out_channels))
return mod_list
if __name__ == '__main__':
model = MobileOneBlock(16, 16, 3, padding=1, num_conv_branches=1)
x = torch.ones(1, 16, 9, 9)
y = model(x)
torch.onnx.export(model,
(x,),
'mobileone_raw.onnx',
opset_version=12,
input_names=['input'],
output_names=['output'])
model.reparameterize()
torch.onnx.export(model,
(x,),
'mobileone_rep.onnx',
opset_version=12,
input_names=['input'],
output_names=['output'])
话不多说,直接对比ONNX的输出,就问你香不香!!!
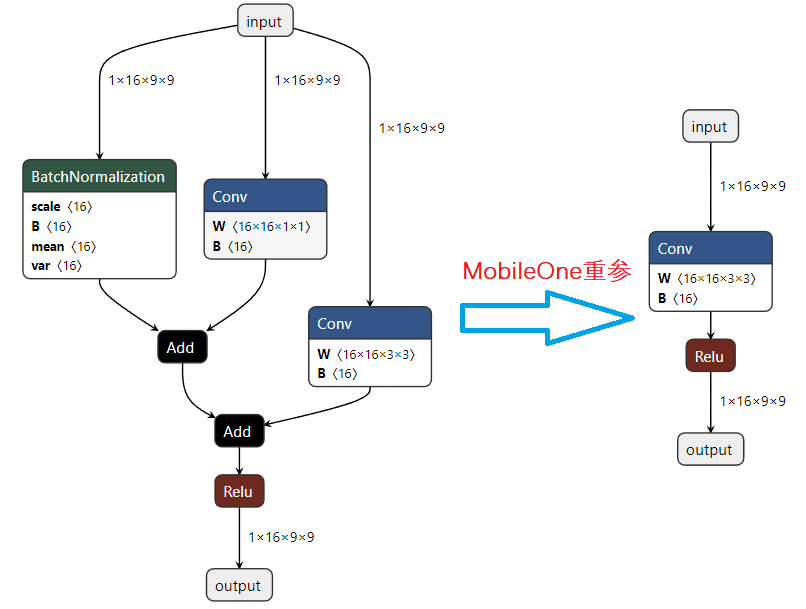
4、参考
[1].https://github.com/apple/ml-mobileone
[2].An Improved One millisecond Mobile Backbone
评论