
万字长文,20-50K前端工程师部分面试题集锦 - 附答案(收藏!)
现在20-50K的招聘,我们先看看是什么要求?
蚂蚁金服招聘要求:

虾皮招聘:
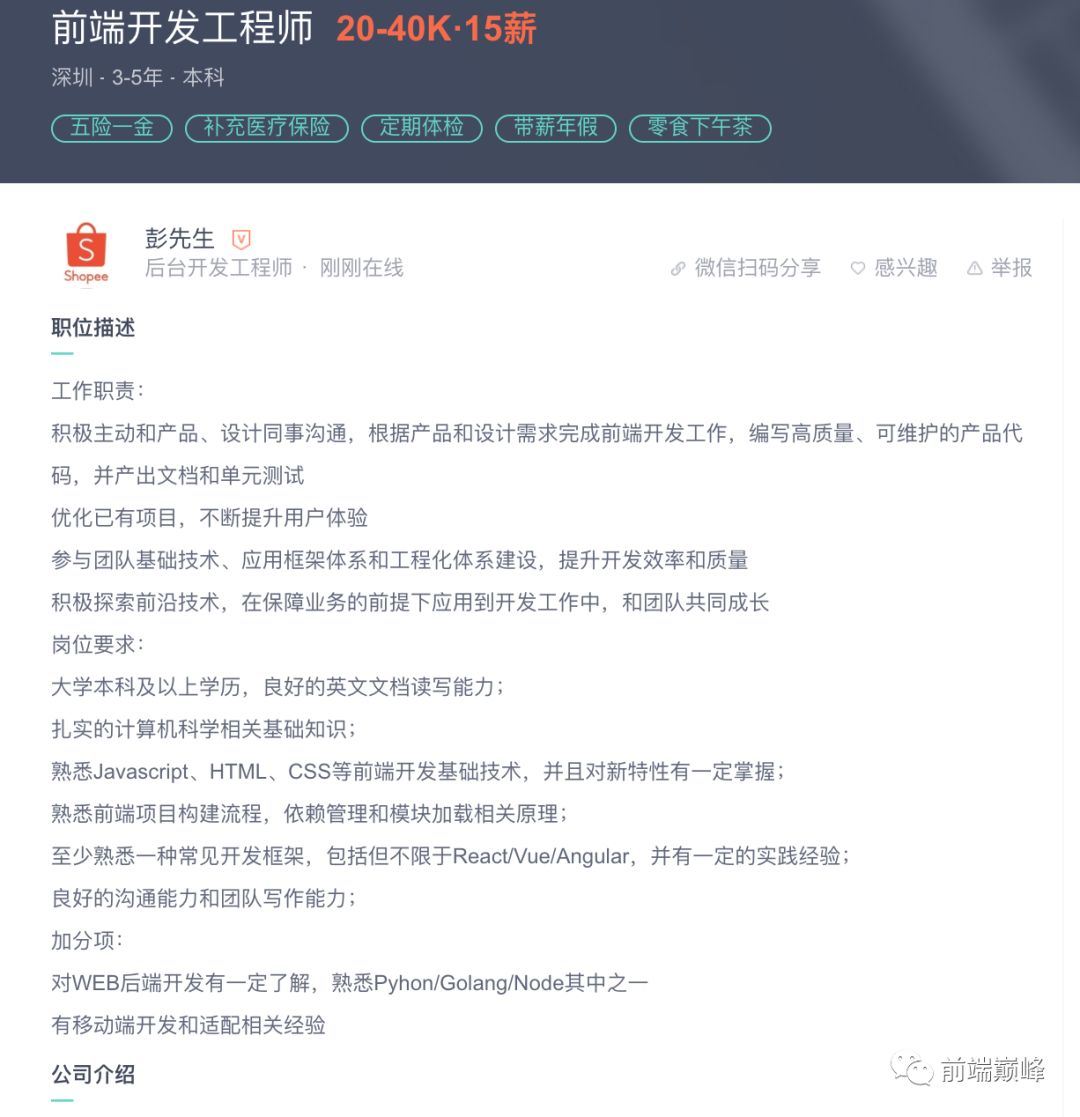
腾讯:
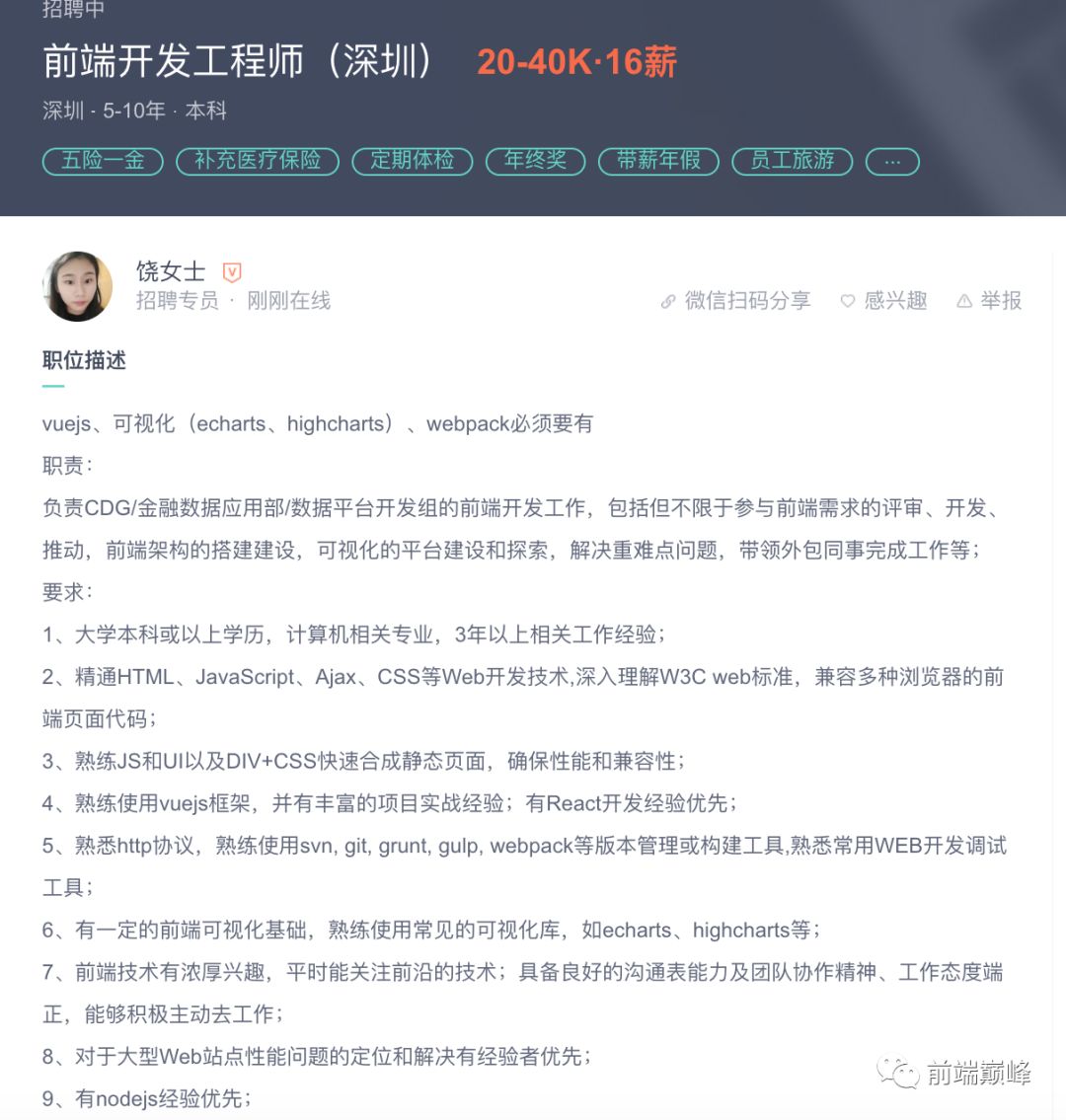
明源云:

毫无疑问,这些公司都是招聘的大前端技术栈的职位,之前文章提到过2020年大前端最理想的技术栈,其实真的弄得很明白那些,出去面试基本上不会有什么问题。
小提示:如果发现小公司面试套你的技术和架构,迅速结束,开出天价薪资走人
下面正式公布部分面试题,以及答案
出于对各个公司的尊重,不公布是哪家公司的面试题,以及面试技巧。只公布部分面试题和答案,以及分析问题的角度,学习方向,面试中考察的不仅仅技术深度,还有广度,每个人不可能技术面面俱到,前端学习的东西太多,忘掉一部分也是正常。记住核心就是关键,这些都是一些基础面试题,比较通用。
一般面试都会要做题,据我经验看,一般都是6页,三张纸。考察的大部分是前端技术栈,原生Javascript的内容,当然,有的外企的面试体验更棒,技术一面规定是半个小时,国内公司可能有5轮,甚至6、7轮。
面试题我会归纳成原生JavaScript、Node.js、React、Vue、通信协议、运维部署、CI自动化部署、Docker、性能优化、前端架构设计、后端常见的架构等来分开写
原生JavaScript篇
以下代码跟我写的有点不一样,但是大致差不多,最终都是在纸上手写实现
手写一个深拷贝:
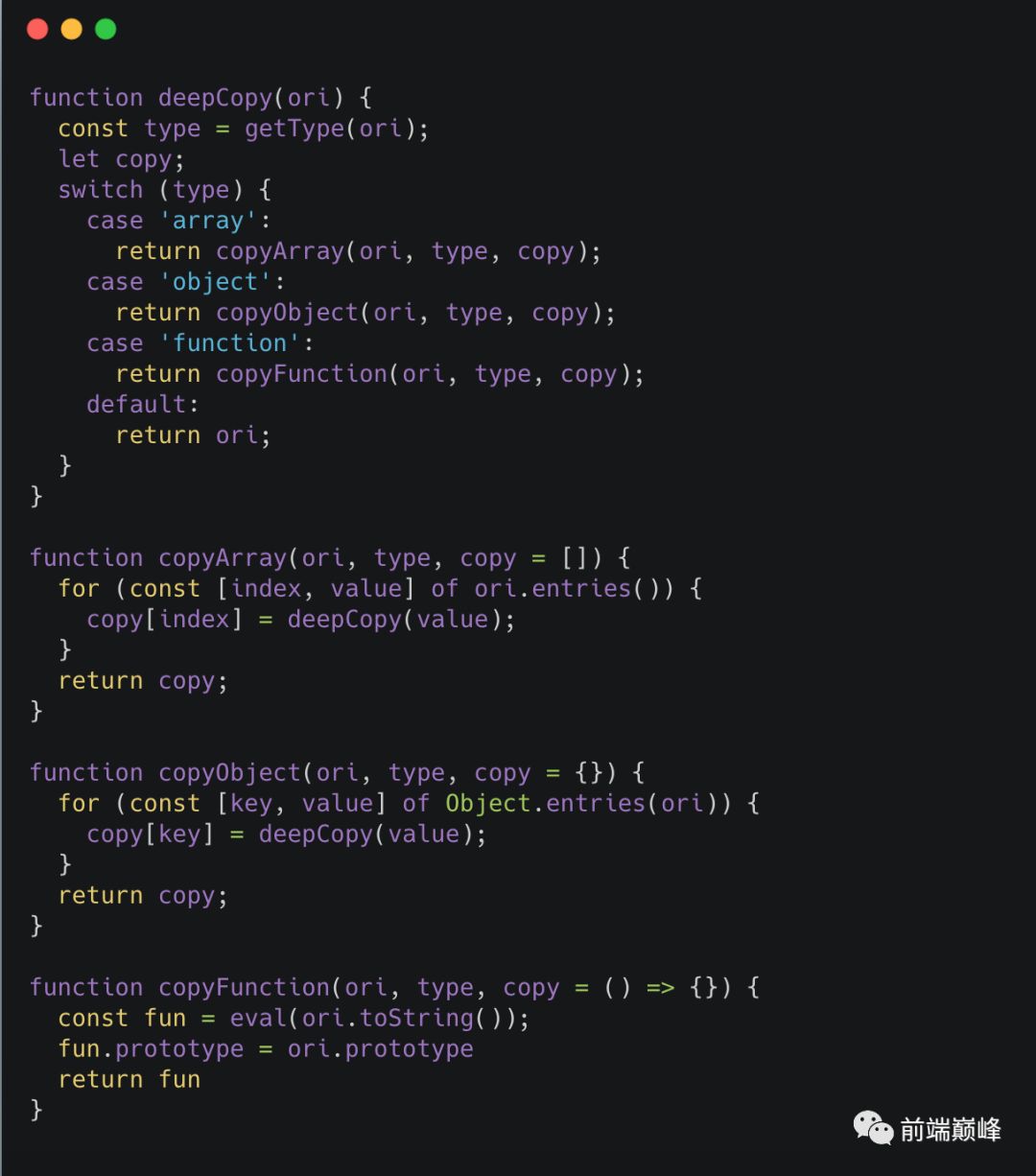
此处省略了一些其他类型的处理,可以在题目旁注释、
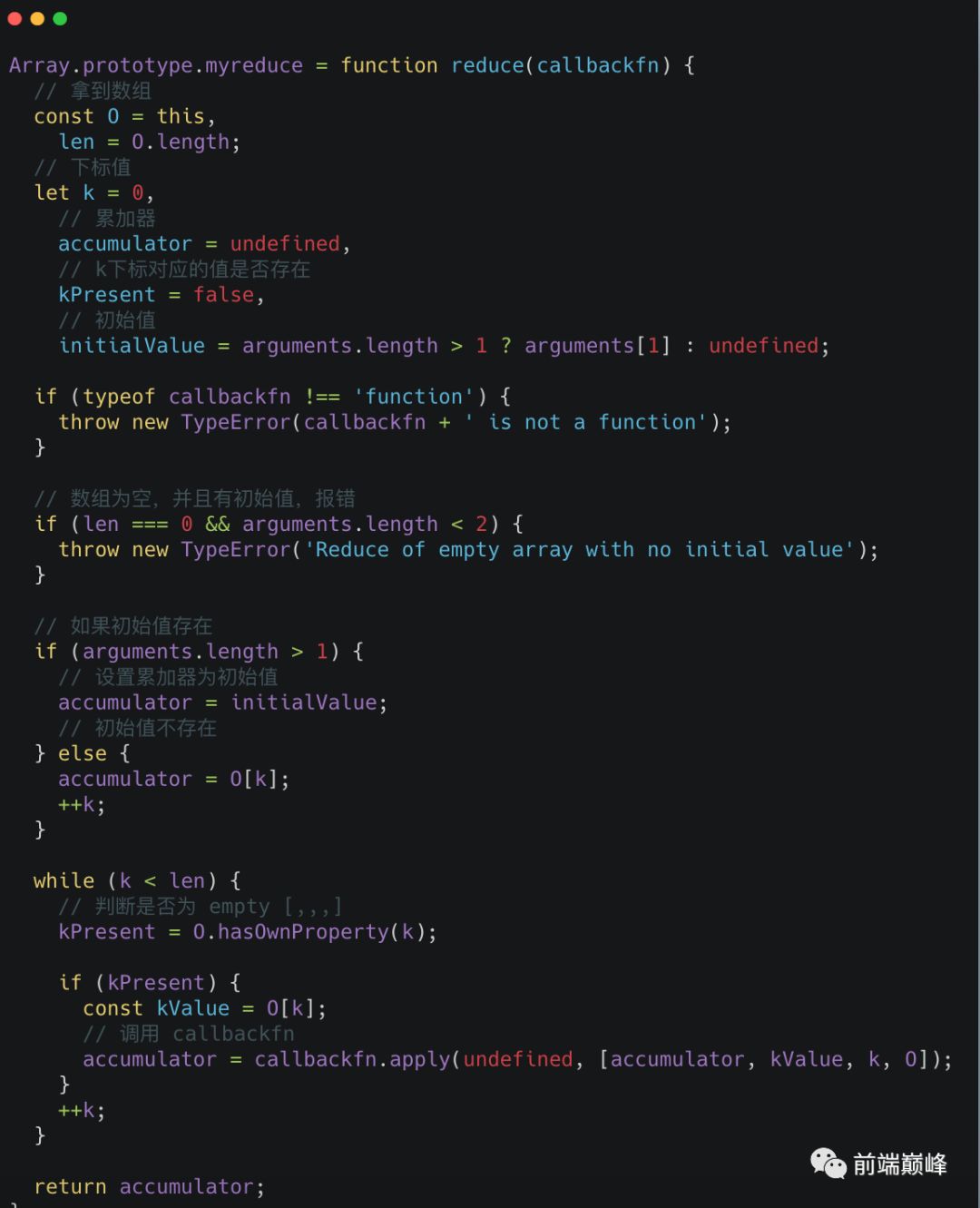
手写一个reduce:
Array.isArray的原理:

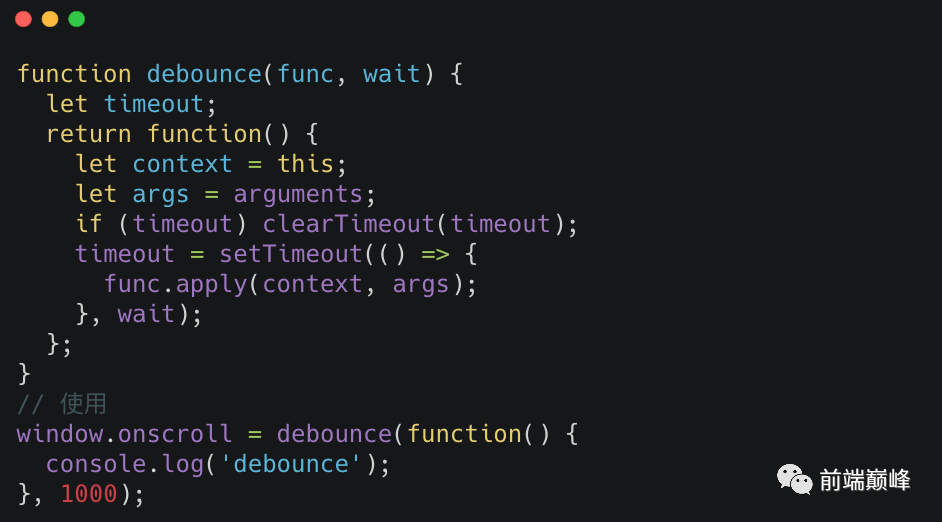
手写一个的防抖函数:
手写一个Promise:
const PENDING = "pending";const FULFILLED = "fulfilled";const REJECTED = "rejected";function MyPromise(fn) {const self = this;self.value = null;self.error = null;self.status = PENDING;self.onFulfilledCallbacks = [];self.onRejectedCallbacks = [];function resolve(value) {if (value instanceof MyPromise) {return value.then(resolve, reject);}if (self.status === PENDING) {setTimeout(() => {self.status = FULFILLED;self.value = value;self.onFulfilledCallbacks.forEach((callback) => callback(self.value));}, 0)}}function reject(error) {if (self.status === PENDING) {setTimeout(function() {self.status = REJECTED;self.error = error;self.onRejectedCallbacks.forEach((callback) => callback(self.error));}, 0)}}try {fn(resolve, reject);} catch (e) {reject(e);}}function resolvePromise(bridgepromise, x, resolve, reject) {if (bridgepromise === x) {return reject(new TypeError('Circular reference'));}let called = false;if (x instanceof MyPromise) {if (x.status === PENDING) {x.then(y => {resolvePromise(bridgepromise, y, resolve, reject);}, error => {reject(error);});} else {x.then(resolve, reject);}} else if (x != null && ((typeof x === 'object') || (typeof x === 'function'))) {try {let then = x.then;if (typeof then === 'function') {then.call(x, y => {if (called) return;called = true;resolvePromise(bridgepromise, y, resolve, reject);}, error => {if (called) return;called = true;reject(error);})} else {resolve(x);}} catch (e) {if (called) return;called = true;reject(e);}} else {resolve(x);}}MyPromise.prototype.then = function(onFulfilled, onRejected) {const self = this;let bridgePromise;onFulfilled = typeof onFulfilled === "function" ? onFulfilled : value => value;onRejected = typeof onRejected === "function" ? onRejected : error => { throw error };if (self.status === FULFILLED) {return bridgePromise = new MyPromise((resolve, reject) => {setTimeout(() => {try {let x = onFulfilled(self.value);resolvePromise(bridgePromise, x, resolve, reject);} catch (e) {reject(e);}}, 0);})}if (self.status === REJECTED) {return bridgePromise = new MyPromise((resolve, reject) => {setTimeout(() => {try {let x = onRejected(self.error);resolvePromise(bridgePromise, x, resolve, reject);} catch (e) {reject(e);}}, 0);});}if (self.status === PENDING) {return bridgePromise = new MyPromise((resolve, reject) => {self.onFulfilledCallbacks.push((value) => {try {let x = onFulfilled(value);resolvePromise(bridgePromise, x, resolve, reject);} catch (e) {reject(e);}});self.onRejectedCallbacks.push((error) => {try {let x = onRejected(error);resolvePromise(bridgePromise, x, resolve, reject);} catch (e) {reject(e);}});});}}MyPromise.prototype.catch = function(onRejected) {return this.then(null, onRejected);}MyPromise.deferred = function() {let defer = {};defer.promise = new MyPromise((resolve, reject) => {defer.resolve = resolve;defer.reject = reject;});return defer;}try {module.exports = MyPromise} catch (e) {}
promisify原理:
promisify = function(fn) {return function() {var args = Array.from(arguments);return new MyPromise(function(resolve, reject) {fn.apply(null,args.concat(function(err) {err ? reject(err) : resolve(arguments[1]);}));});};};
Redux核心源码解析:
bindActionCreator源码解析:
export default function bindActionCreator(actions, dispatch) {let newActions = {};for (let key in actions) {newActions[key] = () => dispatch(actions[key].apply(null, arguments));}return newActions;}
核心:将多个action和dispatch传入,合并成一个全新的actions对象
combineReducers源码:
export default combineReducers = reducers => (state = {}, action) => Object.keys(reducers).reduce((currentState, key) => {currentState[key] = reducers[key](state[key], action);return currentState;}, {});
核心:跟上面有点类似,遍历生成一个全新的state,将多个state合并成一个state
createStore源码结合applyMiddleware讲述如何实现处理多个中间件:
export default function createStore(reducer, enhancer) {if (typeof enhancer !== 'undefined') {return enhancer(createStore)(reducer)}let state = nullconst listeners = []const subscribe = (listener) => {listeners.push(listener)}const getState = () => stateconst dispatch = (action) => {state = reducer(state, action)listeners.forEach((listener) => listener())}dispatch({})return { getState, dispatch, subscribe }}
applyMiddleware:
export default function applyMiddleware(...middlewares) {return (createStore) => (reducer) => {const store = createStore(reducer)let dispatch = store.dispatchlet chain = []const middlewareAPI = {getState: store.getState,dispatch: (action) => dispatch(action)}chain = middlewares.map(middleware => middleware(middlewareAPI))dispatch = compose(...chain)(store.dispatch)return {...store,dispatch}}}
核心:当发现传入createStore的第二个或者第三个参数存在时候(这里没有像原生redux支持SSR代码注水,不支持第二个参数initState),就去返回它的调用结果
整个Redux这里是最绕的,这里不做过分的源码讲解,其实核心就是一点:
实现多个中间件原理,就是将dispatch当作最后一个函数传入,利用compose这个工具函数,最终实现多个中间件同时起作用,当你源码看得比较多的时候会发现,大多数的源码是跟redux相似
compose工具函数实现:
export default function compose(...funcs) {return funcs.reduce((a, b) => (...args) => a(b(...args)));}
核心:其实就是一个reduce函数实现,每次返回一个新的函数,再将新的参数传入
redux下次会专门出个文章讲解,它的源码太重要了~
原生JavaScript考察点比较多,这里只列出一部分,还有像结合TypeScript一起问的,组合继承,对象创建模式、设计模式等,但是那些本次不做讲解
Node.js篇幅:
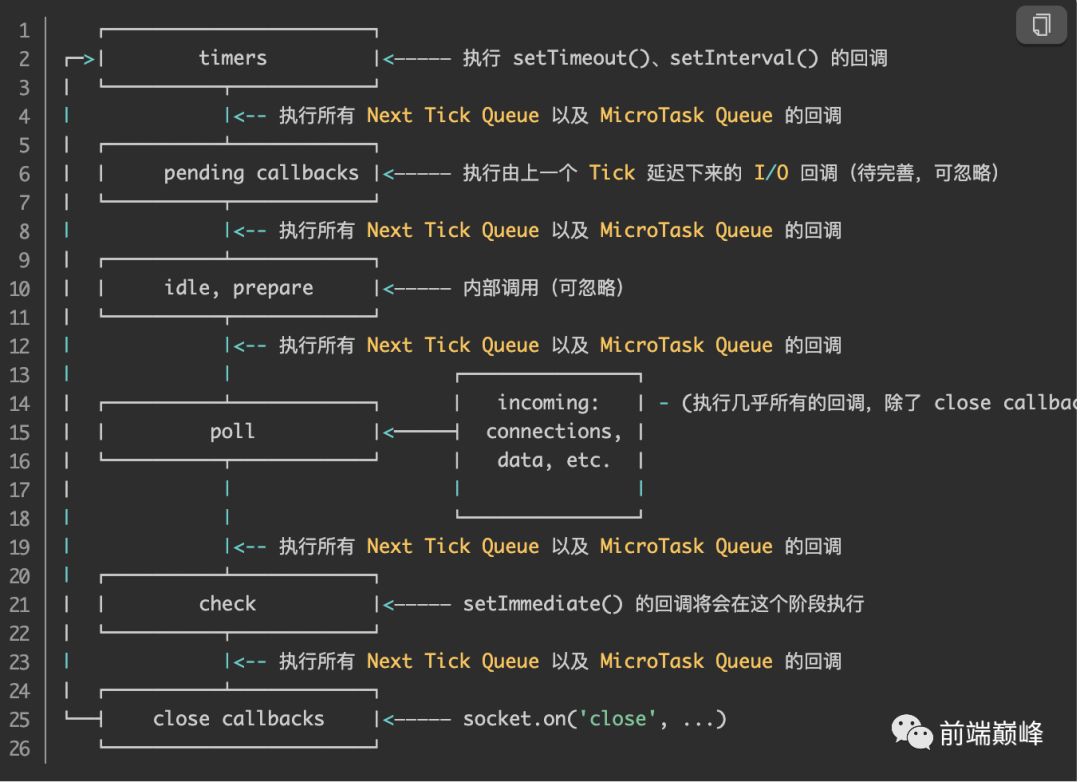
简述Node.js的EventLoop:
现场出题,项目里有下面这段代码,输出是什么,稳定吗,说明原因:
setTimeout(() => {console.log(1);});//----若干代码逻辑new Promise((resolve, reject) => {resolve();}).then(() => {console.log(2);});
答案:先输出2,再输出1,但是不稳定。因为定时器的执行时间不确定,node.js的轮询相当于一个定时器,一直从上往下6个阶段轮询,此时如果中间代码比较耗时,还没运行到Promise时候,已经轮询到第一阶段,定时器的回调就会被触发。
Node.js为什么处理异步IO快?
答:Node 底层采用线程池的原理管理异步 IO,所以我们通常所的 单线程是指 Node 中 JavaScript 的执行是单线程的,但 Node 本身是多线程的。Node.js 中异步 IO 是通过事件循环的方式实现的,异步 IO 事件主要来源于网络请求和文件 IO。但是正因为如此,Node.js处理很多计算密集型的任务,就比较吃力,当然有多进程方式可以解决这个问题。(自己给自己挖坑)
以前听过一个很形象的回答:Java是一百个服务员对应一百个用餐客人,Node是一个服务员对应一百个用餐客人(因为客人不需要分分钟服务,可能只要三分钟----好像,东哥?)
Node.js有cluster、fork两种模式多进程,那么这两种情况下,主进程负责TCP通信,怎样才可以让子进程共享用户的Socket对象?
答案:cluster模式,多实例、自动共享端口链接、自动实现负载均衡。fork模式实现的多进程,单实例、多进程,可以通过手动分发socket对象给不同子进程进行定制化处理、实现负载均衡
Node.js多进程维护,以及通信方式:
答案:原生的cluster和fork模式都有API封装好的进行通信。如果是execfile这样形式调起第三方插件形式,想要与第三方插件进行通信,可以自己封装一个类似promisyfy形式进行通信,维护这块,子进程可以监听到异常,一旦发现异常,立刻通知主进程,杀死这个异常的子进程,然后重新开启一个子进程~
简单谈谈,Node.js搭建TCP、restful、websocket、UDP服务器,遇到过哪些问题,怎么解决的
答案:这里涉及的问题比较多,考察全方位的通信协议知识,需要出个专题后期进行编写
看你简历上写,对koa源码系统学习过,请简述核心洋葱圈的实现:
答案:洋葱圈的实现,有点类似Promise中的then实现,每次通过use方法定义中间件函数时候,就会把这个函数存入一个队列中,全局维护一个ctx对象,每次调用next(),就会调用队列的下一个任务函数。伪代码实现~:
use (fn) {// this.fn = fn 改成:this.middlewares.push(fn) // 每次use,把当前回调函数存进数组}compose(middlewares, ctx){ // 简化版的compose,接收中间件数组、ctx对象作为参数function dispatch(index){ // 利用递归函数将各中间件串联起来依次调用if(index === middlewares.length) return // 最后一次next不能执行,不然会报错let middleware = middlewares[index] // 取当前应该被调用的函数middleware(ctx, () => dispatch(index + 1)) // 调用并传入ctx和下一个将被调用的函数,用户next()时执行该函数}dispatch(0)}
所以这里说,源码看多了会发现,其实大都差不多,都是你抄我的,我抄你的,轮子上搭积木
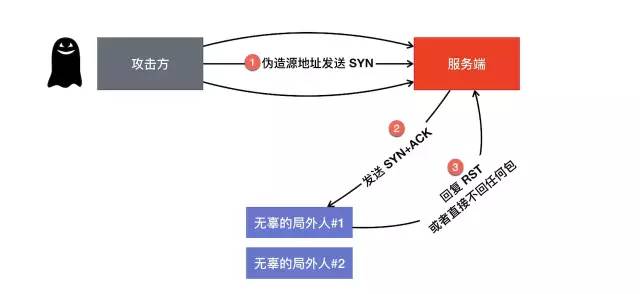
你对TCP系统学习过,请你简述下SYN flood攻击:
小提示:我的TCP是跟张师傅学习的,在某金的小册上有卖。~推荐购买
答案:攻击方伪造源地址发送SYN报文,服务端此时回复syn+ack,但是真正的IP地址收到这个包之后,有可能直接回复了RST包,但是如果不回复RST包,那就更严重了,可能服务端会在几十秒后才关闭这个socket链接(时间根据每个系统不一样)
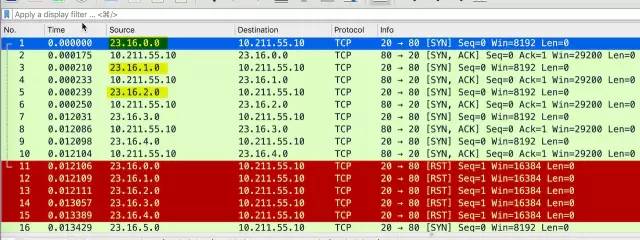
抓包可见~:
TCP可以快速握手吗?
答案:可以 -- 内容来自 张师傅的小册

TCP链接和UDP的区别,什么时候选择使用UDP链接?
http://www.xiuchuang.com/question/4019.html
总结就是:TCP面向链接,UDP面向消息,TCP的ACK作用是确认已经收到上一个包,UDP只管发送,一些无人机的操作,就用UDP链接,每个无人机就是一个服务器,跟地面通讯。
通信协议还是要系统学习,通信这里也问了大概半个小时,包括密钥交换等
看你简历上有写自己实现了一个mini-react,请简述实现原理,以及diff算法实现
仓库地址:https://github.com/JinJieTan/mini-react答案:利用了babel,将虚拟dom转换成了我想要的对象格式,然后实现了异步setState、component diff 、 element diff 、props 更新等。类似PReact的将真实dom和虚拟dom对比的方式进行diff,这里结合代码讲了大概半个小时~ 大家可以看源码,这个对于学习React是非常好的资料,当时我花了半个多月学习
看你对Vue的源码有系统学习过,请简述下Vue2.x版本的数据绑定:
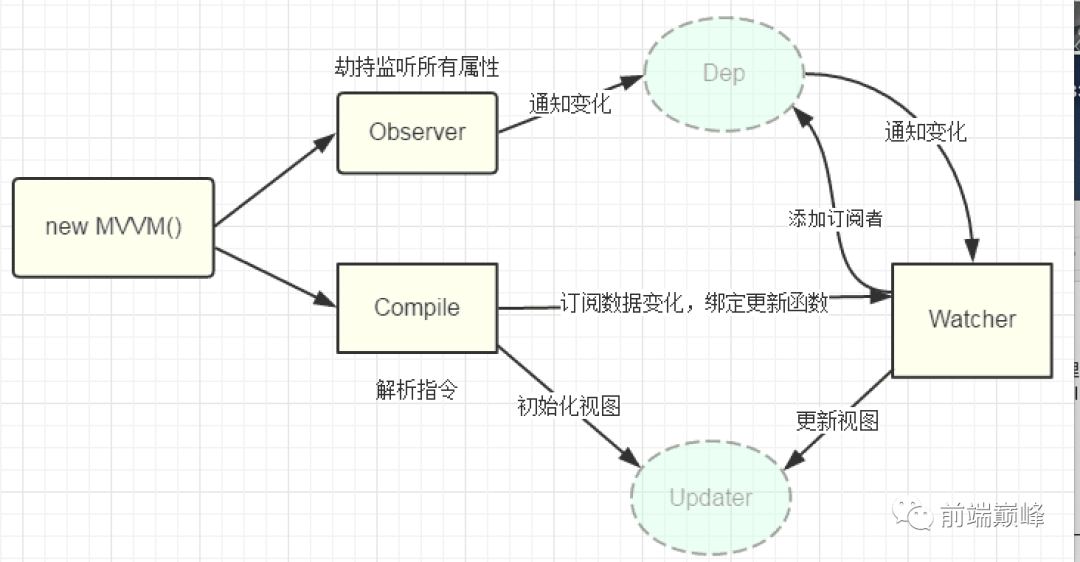
答案:Vue里面的{{}}写法, 会用正则匹配后,拿到数据跟data里的做对比-解析指令,观察数据变化是利用defineProperty来实现,因为监听不到数组的变化,所以尤大大只重写了6个数组API。源码解析,后面就是拼细节,主要讲一些核心点的实现。
为什么Vue的nextTick不稳定?
答案:Vue的nextTick原理是:
优雅降级:
首选promise.then
然后是setImmediate
然后是一个浏览器目前支持不好的API
最后是setTimeout
dom真正更新渲染好的时间,不能真正确定,不论是框架还是原生,都存在这个问题。所以用nextTick并不能保证拿到最新的dom
谈谈你对微前端的看法,以及实践:
答案:将Vue和React一起开发,其实一点都不难,只要自己能造出Redux这样的轮子,熟悉两个框架原理,就能一起开发,难的是将这些在一个合适的场景中使用。之前看到网上有微前端的实践,但是并不是那么完美,当然,类似Electron这样的应用,混合开发很正常,微前端并不是只单单多个框架混合开发,更多是多个框架引入后解决了什么问题、带来的问题怎么解决?毕竟5G还没完全普及,数据传输还是不那么快。过大的包容易带来客户端的过长白屏时间(自己给自己挖坑)
你有提到白屏时间,有什么办法可以减少吗?都是什么原理
答案: GZIP,SSR同构、PWA应用、预渲染、localStorage缓存js文件等、
下面就是细分拆解答案,无限的连带问题,这里非常耗时,这些内容大都网上能搜到,我这里就不详细说
其中有问到PWA的原理,我的回答是:
Service Worker 有一套自己的声明周期,当安装并且处于激活状态时候,网站在https或者localhost的协议时候,可以拦截过滤发出的请求,会先把请求克隆一份(请求是流,消费就没有了),然后判断请求的资源是否在 Service Worker 缓存中,如果存在那么可以直接从 Service Worker 缓存中取出,如果不存在,那么就真正的发出这个请求。
看你的技术栈对Electron比较熟悉,有使用过React-native,请你谈谈使用的感受?
答案:React-native的坑还是比较多,但是目前也算拥有成熟的生态了,开发简单的APP可以使用它。但是复杂的应用还是原生比较好,Electron目前非常受欢迎,它基本上可以完成桌面应用的大部分需求,重型应用开发也是完全没问题的,可以配合大量C# C++插件等。
Node.js的消息队列应用场景是什么?原理是什么
答案:我们公司之前用的kafka,消息队列的核心概念,异步,提供者,消费者。例如IM应用,每天都会有高峰期,但是我们不可能为了高峰期配置那么多服务器,那样就是浪费,所以使用消息队列,在多长时间内流量达到多少,就控制消费频率,例如客户端是流的提供者,有一个中间件消费队列,我们的服务器是消费者,每次消费一个任务就回复一个ACK给消费队列,消费频率由我们控制,这样任务不会丢失,服务器也不会挂。 还有一个异步问题,一个用户下单购买一件商品,可能要更新库存,已购数量,支付,下单等任务。不可能同步进行,这时候需要异步并行,事务方式处理。这样既不耽误时间,也能确保所有的任务成功才算成功,不然没有支付成功,但是已购数量增长了就有问题。
此处省略、、、一万字
用户就是要上传10个G的文件,服务器存储允许的情况下,你会怎么处理保证整体架构顺畅,不影响其他用户?
答案:我会准备两个服务器上传接口,前端或者原生客户端上传文件可以拿到文件大小,根据文件大小,分发不同的对应服务器接口处理上传,大文件可以进行断点续传,原理是md5生成唯一的hash值,将分片的hash数组先上传到后端,然后将文件分片上传,对比hash值,相同的则丢弃。不一致的话,根据数组内容进行buffer拼接生成文件。
关于服务器性能,大文件上传的服务器允许被阻塞,小文件的服务器不会被阻塞。
谈谈你对前端、客户端架构的认识?
答案:前端的架构,首先明确项目的兼容性,面向浏览器编程,是否做成PC、移动端的响应式布局。根据项目规模、后期可能迭代的需求制定技术方案,如果比较重型的应用应该选用原生开发,尽量少使用第三方库。
客户端架构:是否跨平台,明确兼容系统,例如是否兼容XP ,如果兼容XP就选择nw.js,再然后根据项目复杂度招聘相应技术梯度人员,安排系统学习相关内容,招聘人员或者购买定制开发相关原生插件内容。
虽然说只是谈谈,但是感觉面试的职位越高级、轮数越往后,越考验你的架构能力,前面考察基础,后面考察你的技术广度以及逻辑思维,能否在复杂的应用中保持清醒头脑,定位性能这类型的细节能力。很多人基础面试面得很好,但是拿不到offer,原因就是没有这种架构能力,只能自己写代码,不能带领大家学习、写代码。这也是我在面试时偶然听到某个大公司HR之间的对话,原话是:他面试还可以,看起来是很老实(某个之前的面试者),但是他对之前项目整体流程并不是那么清楚,连自己做的项目,前后端流程都不清楚,感觉不合适。
介绍一下Redis,为什么快,怎么做持久化存储,什么叫缓存击穿?
答案:Redis将数据存储在内存中,key-value形式存储,所以获取也快。支持的key格式相对于memorycache更多,而且支持RDB快照形式、AOF
1.RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。RDB是Redis默认的持久化方式,会在对应的目录下生产一个dump.rdb文件,重启会通过加载dump.rdb文件恢复数据。
2、优点
1)只有一个文件dump.rdb,方便持久化;
2) 容灾性好,一个文件可以保存到安全的磁盘;
3) 性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是IO最大化(使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能) ;
4)如果数据集偏大,RDB的启动效率会比AOF更高。
1)数据安全性低。(RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不是特别严格的时候)
2)由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
AOF持久化是以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,文件中可以看到详细的操作记录。她的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
2、优点
1)数据安全性更高,AOF持久化可以配置appendfsync属性,其中always,每进行一次命令操作就记录到AOF文件中一次。
2)通过append模式写文件,即使中途服务器宕机,可以通过redis-check-aof工具解决数据一致性问题。
3)AOF机制的rewrite模式。(AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall))
3、缺点
1)AOF文件比RDB文件大,且恢复速度慢;数据集大的时候,比rdb启动效率低。
2)根据同步策略的不同,AOF在运行效率上往往会慢于RDB。
具体可看、
https://baijiahao.baidu.com/s?id=1631700601579800845&wfr=spider&for=pcRedis可以配合session等做服务端持久化存储、还介绍了下session的场景,
介绍下缓存击穿和穿透:
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
介绍下你会用的自动化构建的方式:
答案
Jenkins自动化构建
自己搭建Node.js服务器,实现Jenkins
Docker配合Travis CI实现自动化构建
细化答案:
Jenkins自动化构建:
配置,自动同步某个分支代码,打包构建。
自己搭建Node.js服务器,实现Jenkins:
自己搭建Node.js的服务器,在GitLab上指定webhook地址,分支代码更新触发事件,服务器接受到post请求,里面附带分支的信息,执行自己的shell脚本命令,指定文件夹,构建打包。
服务器上使用Docker-compose指定镜像,每次代码推送到gitHub,通过自己编写的yml和dockerfile文件构建打包,服务器自动拉取最新镜像并且发布到正式环境
代码实现:
.travis.yml
language: node_jsnode_js:- '12'services:- dockerbefore_install:- npm install- npm install -g parcel-bundlerscript:- parcel build ./index.js- echo "$DOCKER_PASSWORD" | docker login -u "$DOCKER_USERNAME" --password-stdin- docker build -t jinjietan/mini-react:latest .- docker push jinjietan/mini-react:latest
dockerfile:
FROM nginxCOPY ./index.html /usr/share/nginx/html/COPY ./dist /usr/share/nginx/html/distEXPOSE 80
问完Redis,肯定会问数据库,mysql mongodb sqlite都问了,这里就暂时不写了
数据库需要系统的学习,特别是mysql,我这里就不班门弄斧了,推荐某金上面的小孩子的小册。零蛋学mysql(本文没有收取任何广告费,自己买了看完才推荐给大家)
附带的一些问题:
Linux常见操作
云端部署
等。
当然有人会问20-50K的问题怎么这么简单,因为每个问题都是串起来的,需要你的知识面足够广,才能一路面下去,直到拿到offer。而且每个问题都是有坑,例如pm2 start 如果不指定参数到底会启动多少个进程? 在云端和自己的电脑上是不一样的,这些都需要你去有实际操作经验才能应对。
本文的初衷,不为了面试而背面试题,只是让大家知道应该学习什么方向。纯粹为了面试去背诵面试题,是很容易被识破,只有不断积累学习,你才会轻易拿下offer。
座右铭:你想要在外人看来毫不费力,那你就要平时不断努力~
最后
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
欢迎加我微信「qianyu443033099」拉你进技术群,长期交流学习...
关注公众号「前端下午茶」,持续为你推送精选好文,也可以加我为好友,随时聊骚。
