
有了链路日志增强,排查Bug小意思啦!
欢迎关注公众号【Ccww技术博客】,原创技术文章第一时间推出
越努力,越幸运,
本文已收藏在GitHub中JavaCommunity, 里面有面试分享、源码分析系列文章,欢迎收藏,点赞
https://github.com/Ccww-lx/JavaCommunity
在工作中,相信大家最怕的一件事就是听到有人在工作群艾特你:某某功能报错啦。。。
然后你就得屁颠屁颠的去服务器看日志,日志量少还好点,多的话找起来太麻烦了。不太容易直接定位到关键地方。
东找找西找找,好不容易找到了报错的信息,却不知道当时的参数信息是什么,也不太好复现,太难了。。
改完还得写故障报告,美好的一天又没了。
要解决这类的痛点需要做下面几件事情:
- 日志收集
- 异常告警
- 日志增加链路
- API 响应增加 traceId
- 异常时打印当前报错方法的参数
- 支持调试模式
日志收集
要解决的第一个问题就是日志的集中管理,不然报错了你得去多台服务上找错误信息,效率太低了。当然也可以用 ansible 这种工具来做,最好的还是日志统计收集起来,通过 Web 页面就可以搜索查看。
日志收集的标杆就是 ELK 啦,不做过多讲解。像我们是用的云服务,收集起来更方便,直接页面上点点就搞定了。
日志增加链路
日志增加链路跟踪功能分为两个步骤,首先系统要有链路跟踪,然后将链路信息集成到日志中就可以了。
我用的是 Spring Cloud Sleuth,主要是 Sleuth 对很多开源的框架都支持了,也集成了 logback 这样的日志框架,用起来非常方便。
Sleuth 默认增强的日志格式如下:
[${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]
分别是服务名,链路 ID, 工作单元 ID,是否导入到 zipkin 中。对于日志来说最重要的就是 traceId 了,有了 traceId 就能将所有系统的日志串连起来了。
我们也可以自己扩展,增加一些其他的信息放入日志中。比如:
%X{X-REST-API:-},%X{X-RPC-SERVICE:-},%X{X-ORIGIN-INFO:-},%X{X-USER-ID:-},%X{X-BIZ-NAME:-},%X{X-BIZ-ID:-}
- X-REST-API:入口 API, 全局透传
- X-RPC-SERVICE:入口 RPC, 每个服务入口处新增
- X-ORIGIN-INFO:来源信息(调用方应用名:IP:服务名)
- X-USER-ID:用户 ID, 全局透传
- X-BIZ-NAME:业务名称, 全局透传, 应用内可替换
- X-BIZ-ID:业务 ID, 全局透传, 应用内可替换
有了这些扩展的信息就可以直接从日志中知道当前请求的入口 API 是哪个,也知道整个请求经过了哪些服务。
如果我是订单服务的负责人,当我去排查问题的时候根据日志就知道当前这个错误是上游哪个系统和哪个接口调用导致的。
日志中还带上了用户信息,知道是哪个用户的请求。
BIZ-ID 和 BIZ-NAME 可以用于业务场景的问题排查,比如下单后就知道订单 ID 了,后续就可以将订单 ID 追加到日志中,BIZ-NAME=order, BIZ-ID=20102121212121。
后续有支付,发货,退款等等订单相关的操作,日志中都有订单 ID,需要排查的时候直接根据订单 ID 就可以看到整个订单相关的日志信息,前提是打了这些信息。
异常告警
除了用户反馈功能异常,开发也应该在第一时间知道出问题了。所以异常告警一定要做。
一般我们的应用分为:服务应用,Job 应用,异步消费应用
服务应用我们可以在统一的异常处理中进行告警,Job 应用也可以在统一调度的入口进行告警,异步消费的也是一样。
可以通过消息队列告警,也可以通过制定日志的格式,通过记录日志的方式,让日志收集到日志平台,然后配置各种规则进行告警。
异常告警的时候就可以带上 traceId,这样在发现异常的时候,直接通过 traceId 去日志平台搜索,就可以看到这个 traceId 相关的所有日志,对排错很有帮助,前提是你打印了关键的日志信息。
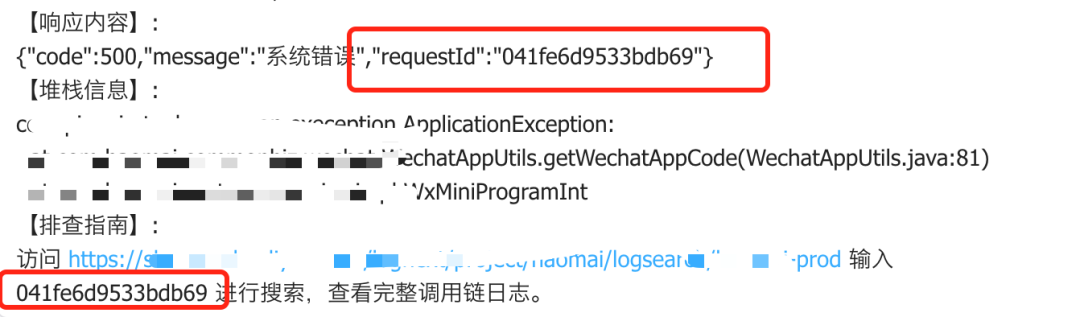
API 响应增加 traceId
可以通过 ResponseBodyAdvice 对响应结果进行统一定制,增加 traceId 响应。这样在出问题的时候可以通过响应的 traceId 直接去日志平台进行日志的搜索。
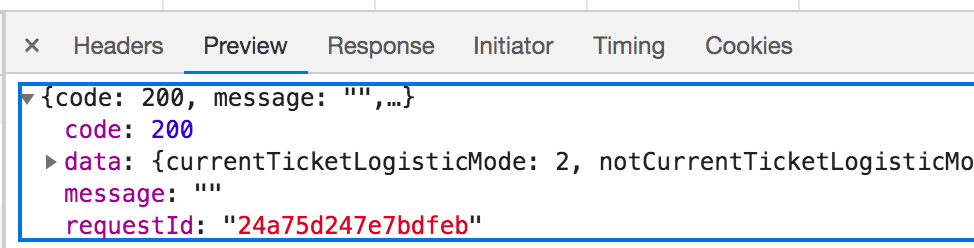
除了快速排查异常问题之外,对于性能优化的时候,我们也可以直接根据 traceId 去查看这个 API 对应的耗时情况,前提是这个 traceId 就是跟你们的 APM 系统一致就行。
异常时打印当前报错方法的参数
通过前面的操作,我们已经可以在异常的时候获取一个 traceId 去排查相关错误信息,也不用去多台机器随机找日志了,极大的提高了问题解决的速度。
只能说这些操作对我们的问题排查起了一半的帮助作用,比如说我现在收到一个告警,然后我去日志平台查了相关的日志,发现某行报错了。
这个时候也只能是猜测这个地方是有问题的,因为我不知道当时是什么参数导致这行报错了。所以如果能在报错的时候将当前报错方法的参数打印到日志中,也就相当于保留了出问题时的现场,解决起问题来就是分分钟的事。
具体实现方案没有固定的,最简单的方式就是写一个 Aspect 切到所有业务方法上,当方法抛出异常的时候记录参数信息,切记只在异常的时候做这个记录的操作,否则对性能影响很大。
效果:
com.xxx.biz.service.impl.GoodsSkuServiceImpl.createSku异常, 参数信息:{"cspuId":1, stock:10, price:100}
Caused by: java.util.NoSuchElementException: No value present
at java.util.Optional.get(Optional.java:135)
at com.xxx.biz.service.impl.GoodsSkuServiceImpl.createSku(GoodsSkuServiceImpl.java:682)
支持调试模式
支持调试模式指的是在某些场景下,我们可以复现出错误,但是除了当时异常时记录的参数信息,还想知道整个请求链路的参数和响应。也就是从入口处经过的所有方法都能够打印出请求和响应数据。
可以定义一个特定的请求头,在复现问题的时候带上这个请求头,由统一的框架去接收这个请求头,然后在整个链路上进行透传。再结合异常的那个 Aspect 将参数和结果进行日志输出即可。
效果:
xxx.xxxController.makeOrder 参数:xxx
xxx.xxxRpcService.makeOrder 参数:xxx
xxx.xxxStockRpcService.lockStock 参数:xxx
xxx.xxxStockRpcService.lockStock 响应:xxx
xxx.xxxRpcService.makeOrder 响应:xxx
xxx.xxxController.makeOrder 响应:xxx
谢谢各位点赞,没点赞的点个赞支持支持
最后,微信搜《Ccww技术博客》观看更多文章,也欢迎关注一波。

如有收获,点个在看,诚挚感谢