
Xgboost 打败深度学习 ?
NLP从入门到放弃
共 2633字,需浏览 6分钟
·
2022-08-02 13:15
为什么基于树的机器学习方法,如 XGBoost 和随机森林在表格数据上优于深度学习?本文给出了这种现象背后的原因,他们选取了 45 个开放数据集,并定义了一个新基准,对基于树的模型和深度模型进行比较,总结出三点原因来解释这种现象。
引自:机器之心


异构列,列应该对应不同性质的特征,从而排除图像或信号数据集。 维度低,数据集 d/n 比率低于 1/10。 无效数据集,删除可用信息很少的数据集。 I.I.D.(独立同分布)数据,移除类似流的数据集或时间序列。 真实世界数据,删除人工数据集,但保留一些模拟数据集。 数据集不能太小,删除特征太少(< 4)和样本太少(< 3 000)的数据集。 删除过于简单的数据集。 删除扑克和国际象棋等游戏的数据集,因为这些数据集目标都是确定性的。
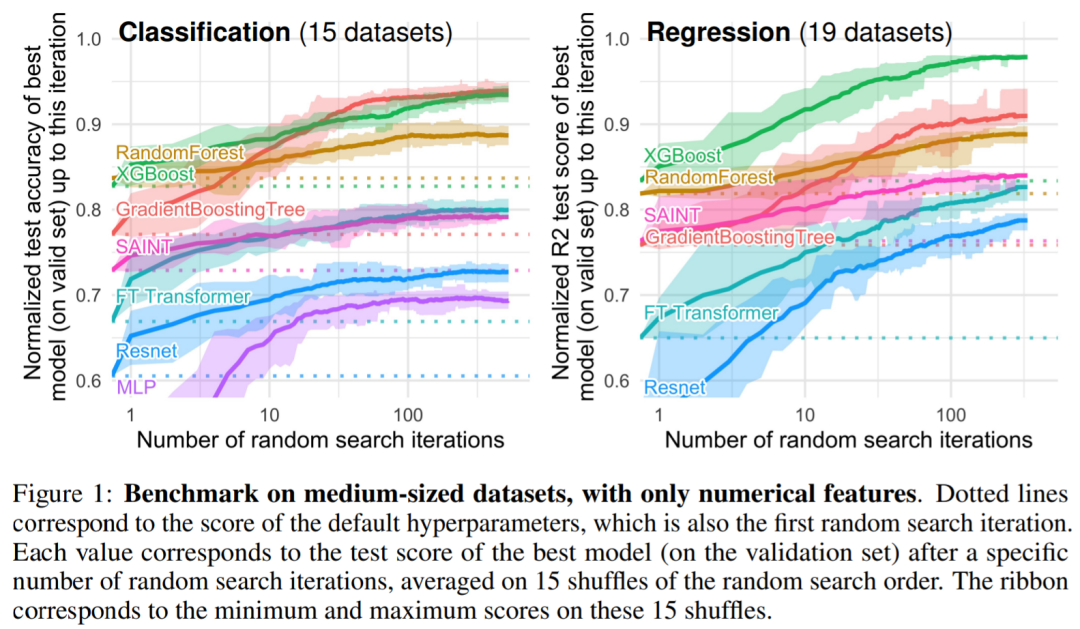
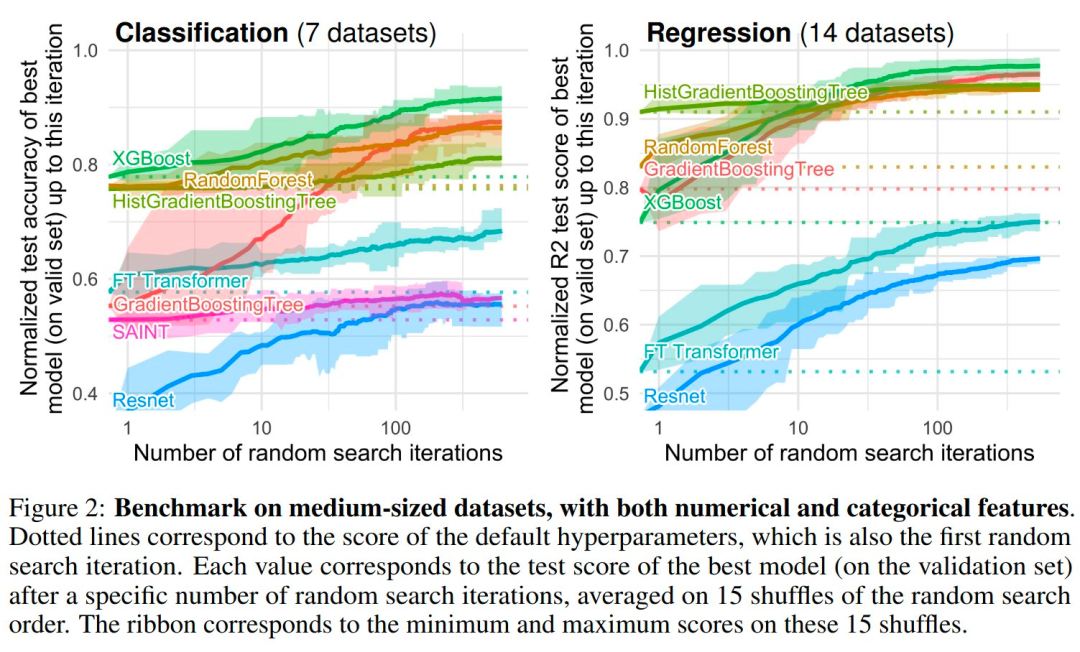
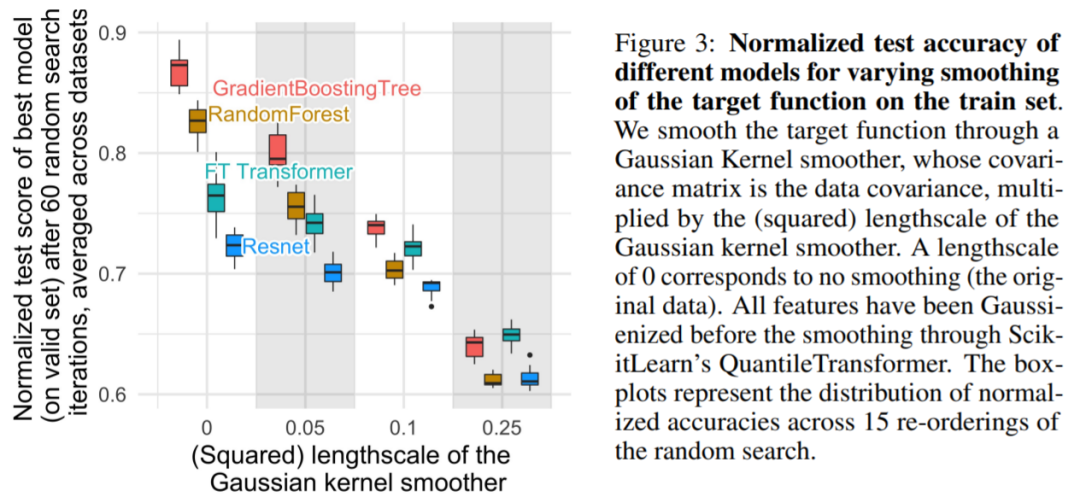
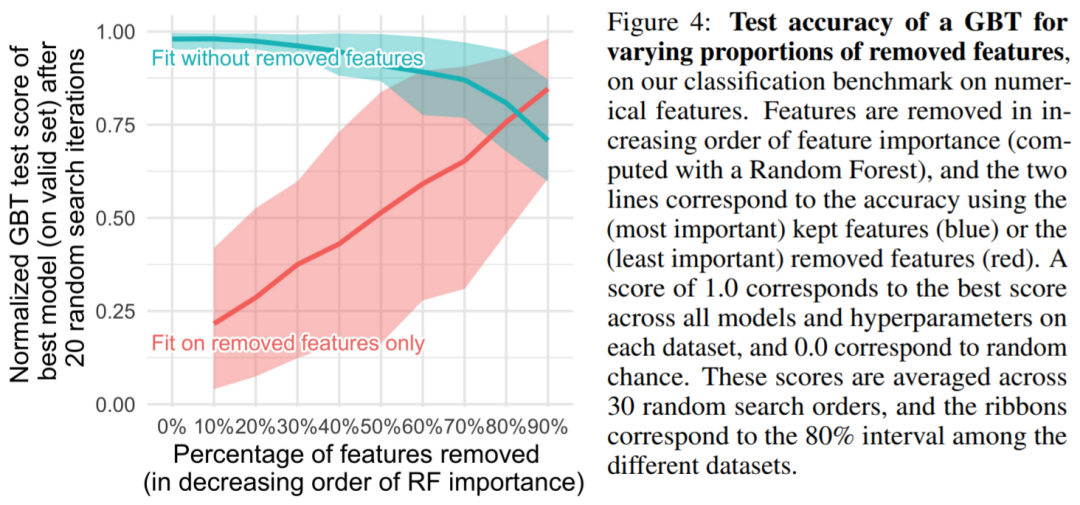
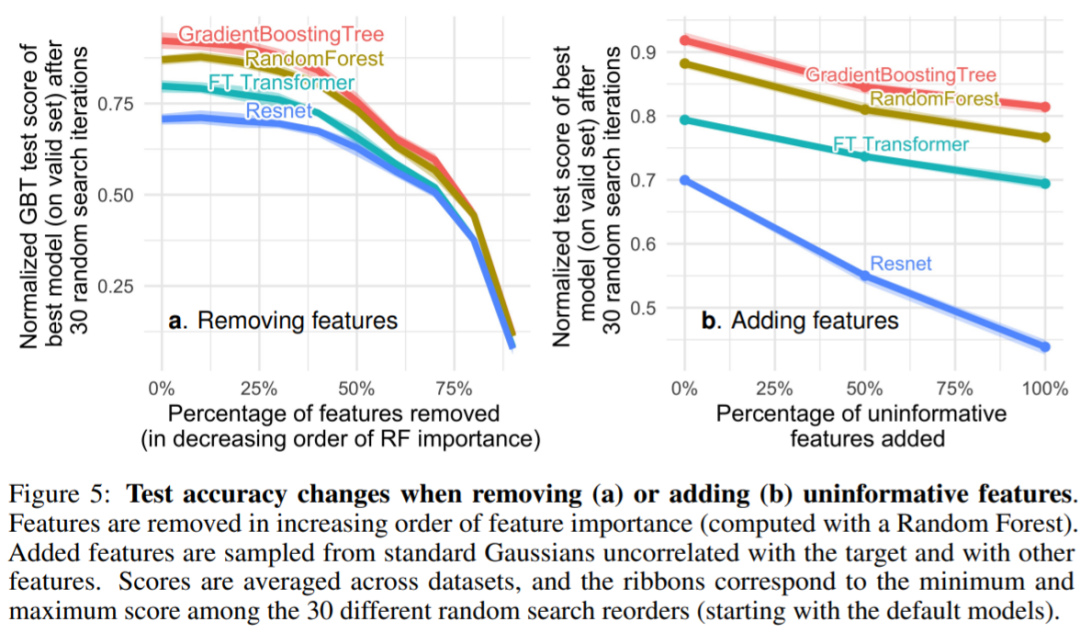
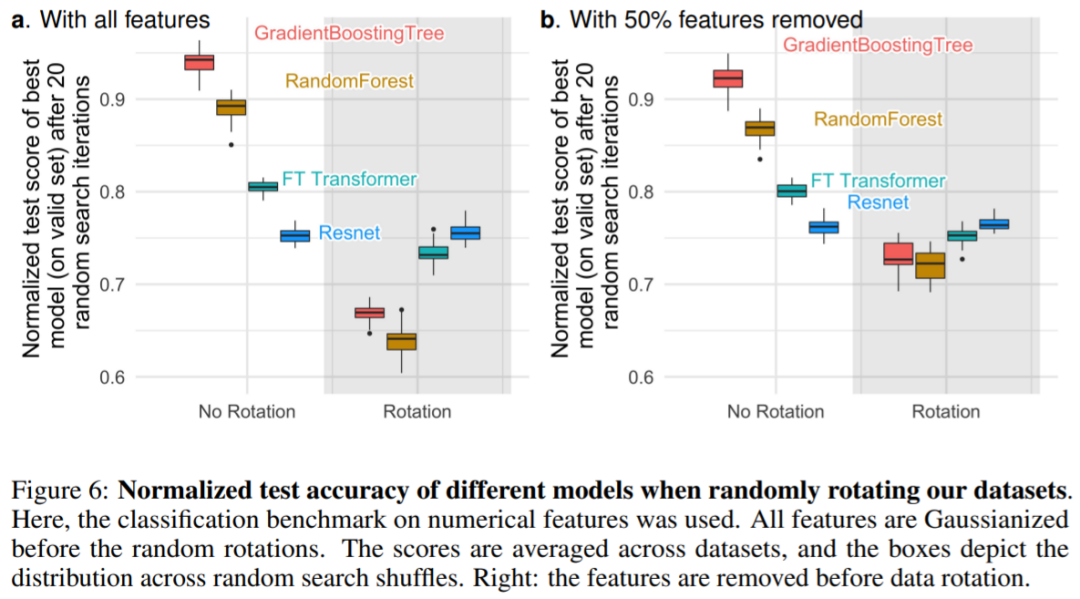
原文链接:https://twitter.com/GaelVaroquaux/status/1549422403889
评论