
Spark 特性 | Apache Spark 3.1 Structured Streaming 改进
•提升了 Python 的可用性;•加强了 ANSI SQL 兼容性;•加强了查询优化;•Shuffle hash join 性能提升;•History Server 支持 structured streaming
更多详情请参见这里。在这篇博文中,我们总结了3.1版本中 Spark Streaming 的显著改进,包括新的流式表(streaming table)API、支持 stream-stream join 和多个 UI 增强。此外,模式验证(schema validation)和对 Apache Kafka 数据源的改进提供了更好的可用性。此外,FileStream source/sink 也进行了各种增强,以提高读/写性能。
新的流式表 API
启动 structured stream 时,连续数据流被认为是无界表(unbounded table)。因此,Table APIs 提供了一种更自然、更方便的方法来处理流查询。在 Spark 3.1 中,社区添加了对 DataStreamReader 和 DataStreamWriter 的支持。我们现在可以直接以表的形式使用这个 API 读取和写入流式 DataFrames。请参见下面的示例:
# Create a streaming DataFramesrc = spark.readStream.format("rate").option("rowPerSecond", 10).load()# Write the streaming DataFrame to a tablesrc.writeStream.option("checkpointLocation", checkpointLoc1).toTable("myTable")# Check the table resultspark.read.table("myTable").show(truncate=30)+-----------------------+-----+|timestamp |value|+-----------------------+-----+|2021-01-19 07:45:23.122|42 ||2021-01-19 07:45:23.222|43 ||2021-01-19 07:45:23.322|44 |...
此外,通过这些新功能,用户可以转换源数据集并写入到一张新表:
# Write to a new table with transformationspark.readStream.table("myTable").select("value") \.writeStream.option("checkpointLocation", checkpointLoc2) \.format("parquet").toTable("newTable")# Check the table resultspark.read.table("newTable").show()+-----+|value|+-----+| 1214|| 1215|| 1216|...
Databricks 推荐在 streaming table APIs 中使用 Delta Lake 格式,因为这种格式将带来以下好处:
•并发压缩由低延迟场景产生的小文件;•多个流作业(或并发批处理作业)支持“仅且一次”(exactly-once)处理;•当使用文件作为流的源时,可以有效地发现哪些文件是新的。
stream-stream 支持更多 Join 类型
在 Spark 3.1 之前,stream-stream join 只支持 inner、left outer 以及 right outer joins。在最新的版本中,社区实现了完整的 full outer 以及 left semi stream-stream join,使 Structured Streaming 支持更多的场景。
•Left semi stream-stream join (SPARK-32862)•Full outer stream-stream join (SPARK-32863)
Kafka 数据源性能提升
在 Spark 3.1 中,社区已经将 Kafka 依赖升级到 2.6.0 (SPARK-32568),这使得用户可以迁移到 Kafka offsets retrieval 新的 API(AdminClient.listOffsets)。它解决了使用旧版本时 Kafka 连接器无限等待的问题 (SPARK-28367)。
模式校验
模式是 Structured Streaming 查询的基本信息。在 Spark 3.1 中,社区为用户输入的模式和内部存储的模式添加了模式验证逻辑:
在查询重启中引入状态模式验证(SPARK-27237)
通过此更新,键和值的模式将存储在 stream 启动时的模式文件(schema files)中。然后,在重新启动查询时,根据现有的键和值模式验证新的键和值模式的兼容性。当字段的数量相同且每个字段的数据类型相同时,状态模式被认为是“兼容的”。注意,这里不会检查字段名,因为 Spark 允许重命名。
这将阻止使用不兼容状态模式的查询运行,从而减少不确定性行为的概率,并提供在错误的时候更多的信息。
为流状态存储引入模式验证(SPARK-31894)
以前,Structured Streaming 直接将检查点(用UnsafeRow表示)放到 StateStore 中,而不需要任何模式验证。当升级到新的 Spark 版本时,检查点文件将被重用。如果没有模式验证,任何与聚合函数相关的更改或 bug 修复都可能导致随机异常,甚至产生错误的结果(参见 SPARK-28067)。现在 Spark 将检验检查点里面的模式,并在迁移过程中重用检查点时抛出 InvalidUnsafeRowException。
Structured Streaming UI 方面的加强
社区在 Spark 3.0 中引入了新的 Structured Streaming UI。在 Spark 3.1 中,社区在 Structured Streaming UI 中添加了对历史记录服务器的支持(Structured Streaming UI(),以及更多关于 streaming 运行时状态的信息,具体如下:
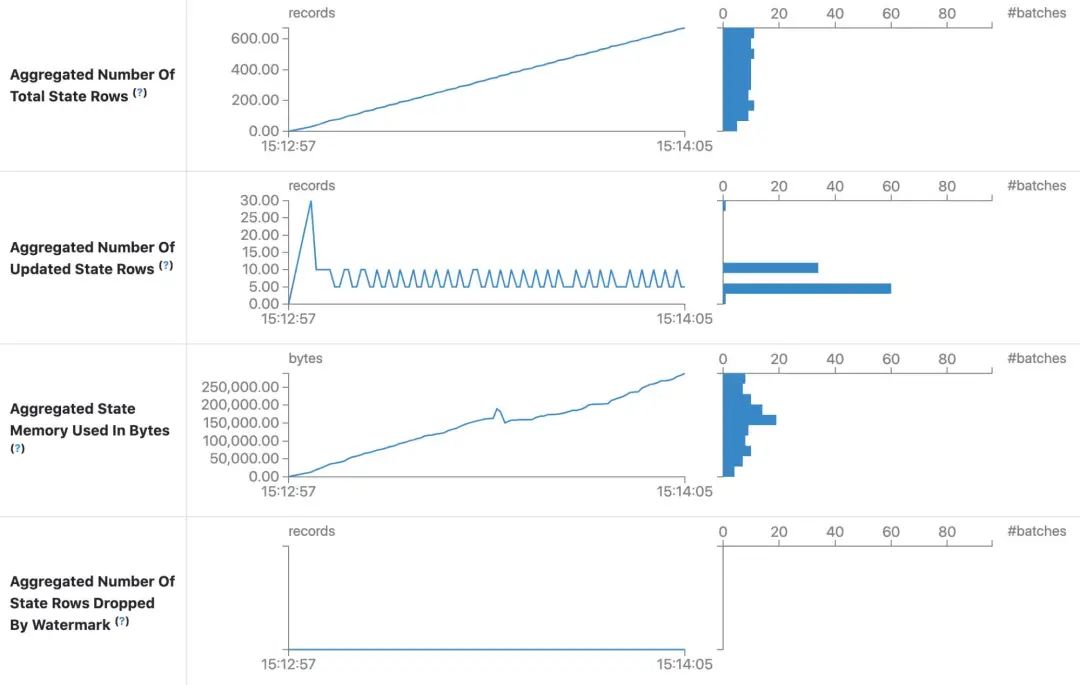
Structured Streaming UI 中的状态信息 (SPARK-33223)
状态信息中添加了四个度量信息:
•Aggregated Number Of Total State Rows•Aggregated Number Of Updated State Rows•Aggregated State Memory Used In Bytes•Aggregated Number Of State Rows Dropped By Watermark
有了这些指标,我们就可以了解状态存储的整体情况。而且根据这些信息我们还可以评估是否需要扩容。
Structured Streaming UI 中 Watermark gap 信息 (SPARK-33224)
Watermark 是状态查询中用户需要跟踪的主要指标之一。它定义了附加模式(append mode)的输出“何时”发出,因此知道 wall clock 和水印(输入数据)之间的差距对于设置输出期望非常有帮助。

Structured Streaming UI 中自定义指标信息(SPARK-33287)
下面显示了在配置 spark.sql.streaming.ui.enabledCustomMetricList 中设置的自定义度量信息:

FileStreamSource/Sink 方面的加强
FileStreamSource/Sink 主要有以下几个方面的加强。
Cache fetched list of files beyond maxFilesPerTrigger as unread files (SPARK-30866)
以前,当设置了 maxFilesPerTrigger 配置时,FileStreamSource 将获取所有可用的文件,根据配置处理有限数量的文件,并在每个微批处理时忽略其他文件。通过这个改进,它将缓存以前批次中获取的文件,并在接下来的批次中处理它们。
Streamline the logic on file stream source and sink metadata log (SPARK-30462)
在此更改之前,每当需要 FileStreamSource/Sink 中的元数据时,元数据日志中的所有信息都被反序列化到 Spark 驱动程序的内存中。通过这个更改,Spark 将尽可能以流式(streamlined)的方式读取和处理元数据日志。
Provide a new option to have retention on output files (SPARK-27188)
FileStreamSink 中有一个新选项用于配置元数据日志文件的保留,这有助于限制长时间运行的 Structured Streaming 查询的元数据日志文件大小的增长。
未来的计划
在下一个主要版本中,社区将继续关注 Spark Structured Streaming 的新功能、性能和可用性改进。如果大家在使用过程中有任何方面的问题可以直接到社区反馈。
本文翻译自《What’s New in Apache Spark™ 3.1 Release for Structured Streaming》https://databricks.com/blog/2021/04/27/whats-new-in-apache-spark-3-1-release-for-structured-streaming.html