
不同并发场景下LongAdder与AtomicLong如何选择
 来源:https://juejin.cn/post/6921595303460241415
来源:https://juejin.cn/post/6921595303460241415
| 写在前面
| volatile
volatile关键字可以理解为轻量级的synchronized,它的使用不会引起线程上下文的切换和调度,使用成本比synchronized低。但是volatile只保证了可见性,所谓可见性是指:当一线程修改了被volatile修饰的变量时,新值对其他线程来说总是立即可知的。volatile不适用于i++这样的计算场景,即运算结果依赖变量的当前值。看个例子:VolatileTest.java。
public class VolatileTest {
private static final int THREAD_COUNT = 20;
private static volatile int race = 0;
public static void increase() {
race++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
//等所有累加线程都结束
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println("race: " + race);
}
}
原因出在increase方法上,虽然increase方法只有一行,但是反编译以后会发现只有一行代码的increase方法是由四行字节码指令构成的。
| AtomicLong
虽然通过对increase方法加锁可以保证结果的正确性,但是synchronized、ReentLock都是互斥锁,同一时刻只允许一个线程执行其余线程只能等待,执行效率会非常差。还好jdk针对这种运算的场景提供了原子类,将上述被volatile修饰的int类型的race变量修改为AtomicLong类型,代码如下:AtomicLongTest.java。
public class AtomicLongTest {
private static final int THREAD_COUNT = 20;
private static volatile AtomicLong race = new AtomicLong(0);
public static void increase() {
race.getAndIncrement();
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
//等所有累加线程都结束
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println("race: " + race);
}
}
运算后得到了预期结果:20000。
| LongAdder
LongAdder的使用姿势和AtomicLong类似,将上面代码中的AtomicLong修改为LongAdder,测试代码如下:
public class LongAdderTest {
private static final int THREAD_COUNT = 20;
//默认初始化为0值
private static volatile LongAdder race = new LongAdder();
public static void increase() {
race.increment();
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println("race: " + race);
}
}
结果也是预期的20000。
| AtomicLong和LongAdder性能比较
了解了volatile关键字,AtomicLong和LongAdder后,来测试一下AtomicLong和LongAdder性能,两者的功能都差不多,如何选择应该用数据说话
使用JMH做Benchmark基准测试,测试代码如下:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class PerformaceTest {
private static AtomicLong atomicLong = new AtomicLong();
private static LongAdder longAdder = new LongAdder();
@Benchmark
@Threads(10)
public void atomicLongAdd() {
atomicLong.getAndIncrement();
}
@Benchmark
@Threads(10)
public void longAdderAdd() {
longAdder.increment();
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder().include(PerformaceTest.class.getSimpleName()).build();
new Runner(options).run();
}
}
说明:
@BenchmarkMode(Mode.Throughput) => 测试吞吐量 @OutputTimeUnit(TimeUnit.MILLISECONDS) => 输出的时间单位 @Threads(10) => 每个进程中的测试线程数
线程数为1:
Benchmark Mode Cnt Score Error Units
PerformaceTest.atomicLongAdd thrpt 200 153824.699 ± 137.947 ops/ms
PerformaceTest.longAdderAdd thrpt 200 124087.220 ± 81.015 ops/ms线程数为5:
PerformaceTest.atomicLongAdd thrpt 200 56392.136 ± 1165.361 ops/ms
PerformaceTest.longAdderAdd thrpt 200 605501.870 ± 4140.190 ops/ms线程数为10:
Benchmark Mode Cnt Score Error Units
PerformaceTest.atomicLongAdd thrpt 200 53286.334 ± 957.765 ops/ms
PerformaceTest.longAdderAdd thrpt 200 713884.602 ± 3950.884 ops/ms
从测试结果来看,当线程数为5时,LongAdder的性能已经优于AtomicLong。
| 产生性能差异的原因
AtomicLong#getAndIncrement方法分析
//AtomicLong#getAndIncrement
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
//Unsafe#getAndAddLong
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
底层使用的是CAS算法,JVM中的CAS操作是利用了处理器提供的CMPXCHG指令实现的。自旋CAS实现的基本思路就是循环进行CAS操作直到成功为止,也正是因为这样的实现思路也带来了在高并发下的性能问题。循环时间长开销大,自旋CAS如果长时间不成功,会给处理器带来非常大的执行开销。在高并发环境下,N个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,所以在上述测试中,当测试线程数非常多时,使用LongAdder的性能优于使用AtomicLong。
LongAdder#increment方法分析
public void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}代码很长,可以结合图片理解:
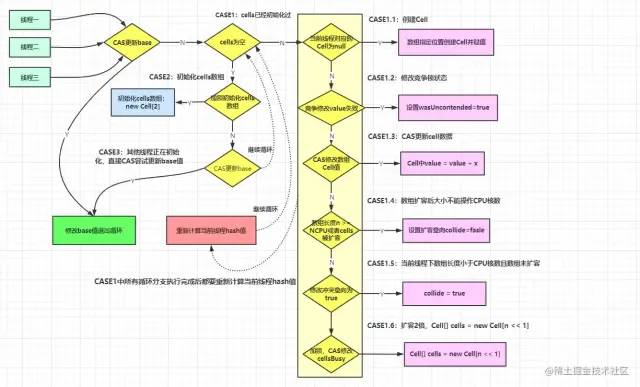
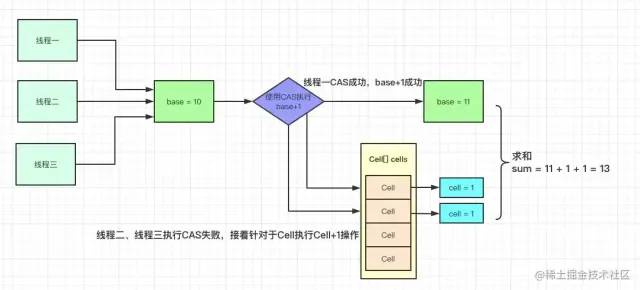
LongAdder性能高的原因是通过使用Cell数组,以空间换效率避免共享变量的竞争,在LongAdder中内部使用base变量保存Long值 ,当没有线程冲突时,使用CAS更新base的值,而存在线程冲突时,没有执行CAS成功的线程将CAS操作Cell数组,将数组中的元素置为1,即cell[i]=1,最后获取计数时会计算cell[i]的总和在加base,即为最后的计数结果,sum代码如下:
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
| AtomicLong和LongAdder选择
高并发下选择LongAdder,非高并发下选择AtomicLong。
关注公众号【Java技术江湖】后回复“PDF”即可领取200+页的《Java工程师面试指南》
强烈推荐,几乎涵盖所有Java工程师必知必会的知识点,不管是复习还是面试,都很实用。
