
【关于Transformer】 那些的你不知道的事(中)
作者:杨夕
项目地址:https://github.com/km1994/nlp_paper_study
论文链接:https://arxiv.org/pdf/1706.03762.pdf
【注:手机阅读可能图片打不开!!!】
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
## 引言
本博客 主要 是本人在学习 Transformer 时的**所遇、所思、所解**,通过以 **十六连弹** 的方式帮助大家更好的理解 该问题。
## 十六连弹
1. 为什么要有 Transformer?
2. Transformer 作用是什么?
3. Transformer 整体结构怎么样?
4. Transformer-encoder 结构怎么样?
5. Transformer-decoder 结构怎么样?
6. 传统 attention 是什么?
7. self-attention 长怎么样?
8. self-attention 如何解决长距离依赖问题?
9. self-attention 如何并行化?
10. multi-head attention 怎么解?
11. 为什么要 加入 position embedding ?
12. 为什么要 加入 残差模块?
13. Layer normalization。Normalization 是什么?
14. 什么是 Mask?
15. Transformer 存在问题?
16. Transformer 怎么 Coding?
## 问题解答
### 六、传统 attention 是什么?
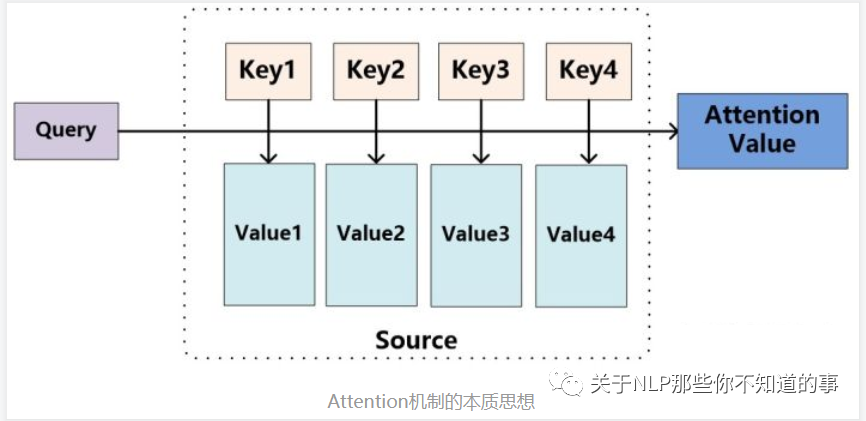
- 注意力机制是什么呢?
- 就是将精力集中于某一个点上
- 举个例子:
- 你在超市买东西,突然一个美女从你身边走过,这个时候你会做什么呢?
- 没错,就是将视线【也就是注意力】集中于这个美女身上,而周围环境怎么样,你都不关注。
- 思路
- 输入 给定 Target 中某个 query;
- 计算权值 Score:
- 计算 query 和 各个 Key 的相似度或相关性,得到每个 Key 对应 value 的权值系数;
- 对 权值 Score 和 value 进行加权求和
- 核心:
- Attention 机制 是对 source 中各个元素 的 value 进行加权求和,而 query 和 key 用于计算 对应 value 的权值系数
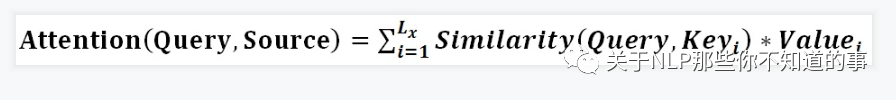
> $L_x=||Source||$代表Source的长度
- 概念:
- attention 的核心 就是从 大量信息中 筛选出少量的 重要信息;
- 具体操作:每个 value 的 权值系数,代表 其 重要度;

- 具体流程介绍
- step 1:计算权值系数
- 采用 不同的函数或计算方式,对 query 和 key 进行计算,求出相似度或相关性
- 采用的计算方法:
- 向量点积:

- Cosine 相似度计算:

- MLP 网络:
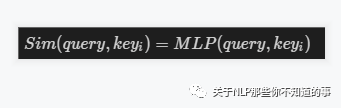
- step 2: softmax 归一化
- 原因:
1. score 值分布过散,将原始计算分值整理成所有元素权重之和为1 的概率分布;
2. 可以通过SoftMax的内在机制更加突出重要元素的权重;
- 公式介绍
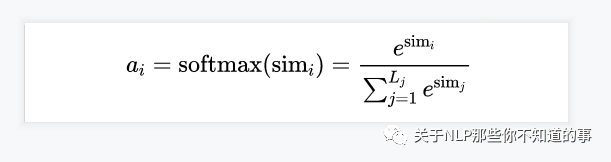
- step 3: 加权求和
- 公式介绍:
- 计算结果 $a_i$ 即为 $value_i$ 对应的权重系数,然后进行加权求和即可得到Attention数值

- 存在问题
- 忽略了 源端或目标端 词与词间 的依赖关系【以上面栗子为例,就是把注意力集中于美女身上,而没看自己周围环境,结果可能就扑街了!】
### 七、self-attention 长怎么样?
- 动机
- CNN 所存在的长距离依赖问题;
- RNN 所存在的无法并行化问题【虽然能够在一定长度上缓解 长距离依赖问题】;
- 传统 Attention
- 方法:基于源端和目标端的隐向量计算Attention,
- 结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
- 问题:忽略了 远端或目标端 词与词间 的依赖关系
- 核心思想:self-attention的结构在计算每个token时,总是会考虑整个序列其他token的表达;
- 举例:“我爱中国”这个序列,在计算"我"这个词的时候,不但会考虑词本身的embedding,也同时会考虑其他词对这个词的影响
- 目的:学习句子内部的词依赖关系,捕获句子的内部结构。
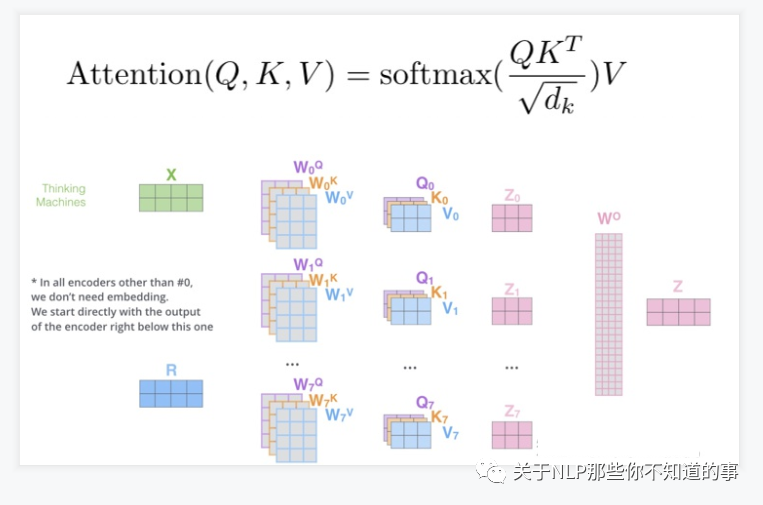
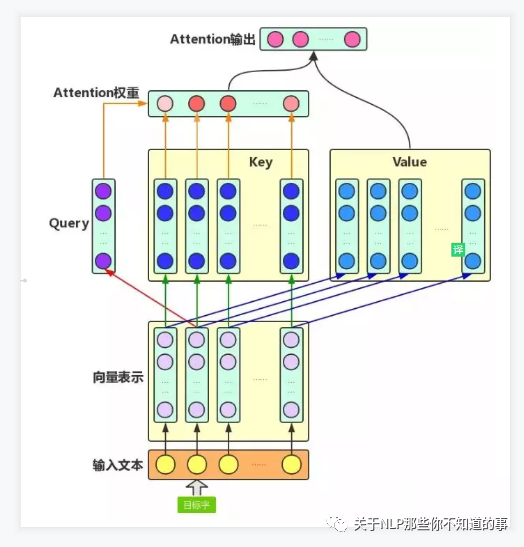
- 步骤
- embedding层:
- 目的:将词转化成embedding向量;
- Q,K,V 向量计算:
- 根据 embedding 和权重矩阵,得到Q,K,V;
- Q:查询向量,目标字作为 Query;
- K:键向量,其上下文的各个字作为 Key;
- V:值向量,上下文各个字的 Value;
- 权重 score 计算:
- 查询向量 query 点乘 key;
- 目的:计算其他词对这个词的重要性,也就是权值;
- scale 操作:
- 乘以 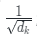 ;
;
- 目的:起到调节作用,使得内积不至于太大。实际上是Q,K,V的最后一个维度,当 $d_k$ 越大, 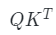 就越大,可能会将 Softmax 函数推入梯度极小的区域;
就越大,可能会将 Softmax 函数推入梯度极小的区域;
- Softmax 归一化:
- 经过 Softmax 归一化;
- Attention 的输出计算:
- 权值 score 和各个上下文字的 V 向量 的加权求和
- 目的:把上下文各个字的 V 融入目标字的原始 V 中
- 举例
- 答案就是文章中的Q,K,V,这三个向量都可以表示"我"这个词,但每个向量的作用并不一样,Q 代表 query,当计算"我"这个词时,它就能代表"我"去和其他词的 K 进行点乘计算其他词对这个词的重要性,所以此时其他词(包括自己)使用 K 也就是 key 代表自己,当计算完点乘后,我们只是得到了每个词对“我”这个词的权重,需要再乘以一个其他词(包括自己)的向量,也就是V(value),才完成"我"这个词的计算,同时也是完成了用其他词来表征"我"的一个过程
- 优点
- 捕获源端和目标端词与词间的依赖关系
- 捕获源端或目标端自身词与词间的依赖关系
### 八、self-attention 如何解决长距离依赖问题?
- 引言:
- 在上一个问题中,我们提到 CNN 和 RNN 在处理长序列时,都存在 长距离依赖问题,那么你是否会有这样 几个问题:
- 长距离依赖问题 是什么呢?
- 为什么 CNN 和 RNN 无法解决长距离依赖问题?
- 之前提出过哪些解决方法?
- self-attention 是如何 解决 长距离依赖问题的呢?
下面,我们将会围绕着几个问题,进行一一解答。
- 长距离依赖问题 是什么呢?
- 介绍:对于序列问题,第 t 时刻 的 输出 $y_t$ 依赖于 t 之前的输入,也就是 说 依赖于 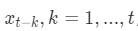 ,当间隔 k 逐渐增大时,$x_{t-k}$ 的信息将难以被 $y_t$ 所学习到,也就是说,很难建立 这种 长距离依赖关系,这个也就是 长距离依赖问题(Long-Term Dependencies Problem)。
,当间隔 k 逐渐增大时,$x_{t-k}$ 的信息将难以被 $y_t$ 所学习到,也就是说,很难建立 这种 长距离依赖关系,这个也就是 长距离依赖问题(Long-Term Dependencies Problem)。
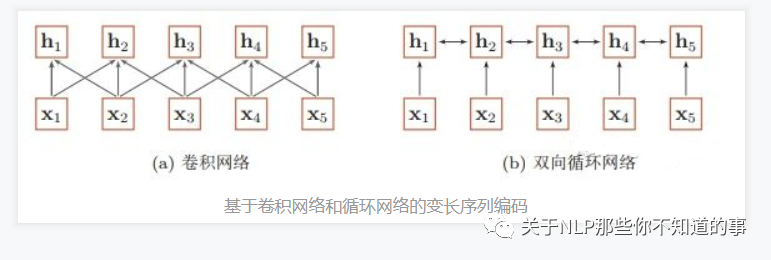
- 为什么 CNN 和 RNN 无法解决长距离依赖问题?
- CNN:
- 捕获信息的方式:
- CNN 主要采用 卷积核 的 方式捕获 句子内的局部信息,你可以把他理解为 **基于 n-gram 的局部编码方式**捕获局部信息
- 问题:
- 因为是 n-gram 的局部编码方式,那么当 $k$ 距离 大于 $n$ 时,那么 $y_t$ 将难以学习 $x_{t-k}$ 信息;
- 举例:
- 其实 n-gram 类似于 人的 视觉范围,人的视觉范围 在每一时刻 只能 捕获 一定 范围内 的信息,比如,你在看前面的时候,你是不可能注意到背后发生了什么,除非你转过身往后看。
- RNN:
- 捕获信息的方式:
- RNN 主要 通过 循环 的方式学习(记忆) 之前的信息$x_{t}$;
- 问题:
- 但是随着时间 $t$ 的推移,你会出现**梯度消失或梯度爆炸**问题,这种问题使你只能建立短距离依赖信息。
- 举例:
- RNN 的学习模式好比于 人类 的记忆力,人类可能会对 短距离内发生的 事情特别清楚,但是随着时间的推移,人类开始 会对 好久之前所发生的事情变得印象模糊,比如,你对小时候发生的事情,印象模糊一样。
- 解决方法:
- 针对该问题,后期也提出了很多 RNN 变体,比如 LSTM、 GRU,这些变体 通过引入 门控的机制 来 有选择性 的记忆 一些 重要的信息,但是这种方法 也只能在 一定程度上缓解 长距离依赖问题,但是并不能 从根本上解决问题。
- 之前提出过哪些解决方法?
- 引言:
- 那么 之前 主要采用 什么方法 解决问题呢?
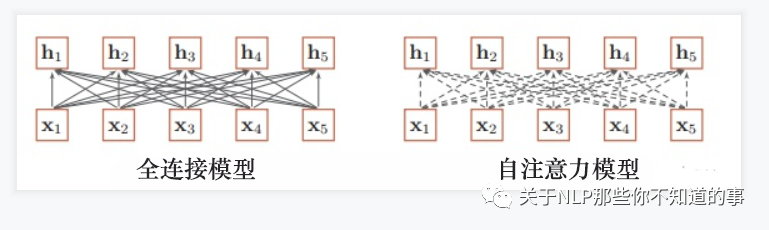
- 解决方法:
- 增加网络的层数
- 通过一个深层网络来获取远距离的信息交互
- 使用全连接网络
- 通过全连接的方法对 长距离 建模;
- 问题:
- 无法处理变长的输入序列;
- 不同的输入长度,其连接权重的大小也是不同的;
- self-attention 是如何 解决 长距离依赖问题的呢?
- 解决方式:
- 利用注意力机制来“动态”地生成不同连接的权重,从而处理变长的信息序列
- 具体介绍:
- 对于 当前query,你需要 与 句子中 所有 key 进行点乘后再 Softmax ,以获得 句子中 所有 key 对于 当前query 的 score(可以理解为 贡献度),然后与 所有词 的 value 向量进行加权融合之后,就能使 当前 $y_t$ 学习到句子中 其他词$x_{t-k}$的信息;
### 九、self-attention 如何并行化?
- 引言:
- 在上一个问题中,我们主要讨论了 CNN 和 RNN 在处理长序列时,都存在 长距离依赖问题,以及 Transformer 是 如何解决 长距离依赖问题,但是对于 RNN ,还存在另外一个问题:
- 无法并行化问题
- 那么,Transformer 是如何进行并行化的呢?
- Transformer 如何进行并行化?
- 核心:self-attention
- 为什么 RNN 不能并行化:
- 原因:RNN 在 计算 $x_i$ 的时候,需要考虑到 $x_1 ~ x_{i-1}$ 的 信息,使得 RNN 只能 从 $x_1$ 计算到 $x_i$;
- 思路:
- 在 self-attention 能够 并行的 计算 句子中不同 的 query,因为每个 query 之间并不存在 先后依赖关系,也使得 transformer 能够并行化;
### 十、multi-head attention 怎么解?
- 思路:
- 相当于 $h$ 个 不同的 self-attention 的集成
- 就是把self-attention做 n 次,取决于 head 的个数;论文里面是做了8次。
- 步骤:
- step 1 : 初始化 N 组 $Q,K,V$矩阵(论文为 8组);

- step 2 : 每组 分别 进行 self-attention;
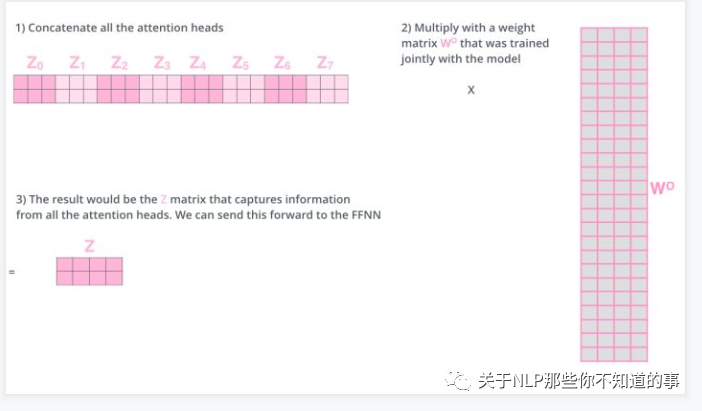
- step 3:
- 问题:多个 self-attention 会得到 多个 矩阵,但是前馈神经网络没法输入8个矩阵;
- 目标:把8个矩阵降为1个
- 步骤:
- 每次self-attention都会得到一个 Z 矩阵,把每个 Z 矩阵拼接起来,
- 再乘以一个Wo矩阵,
- 得到一个最终的矩阵,即 multi-head Attention 的结果;
最后,让我们来看一下完整的流程:
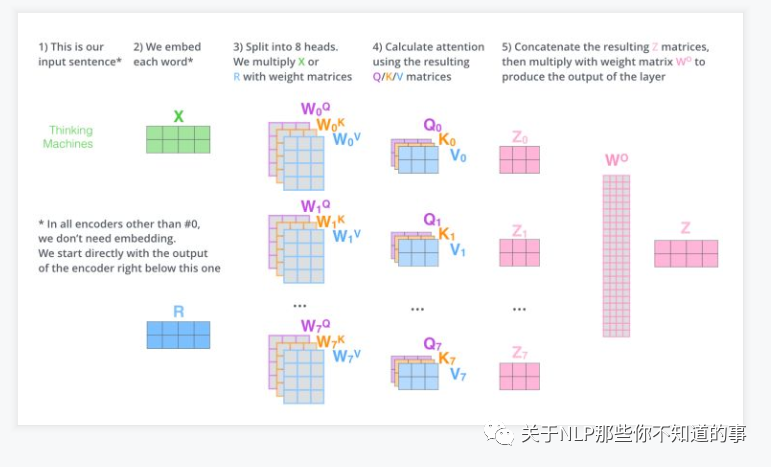
换一种表现方式:
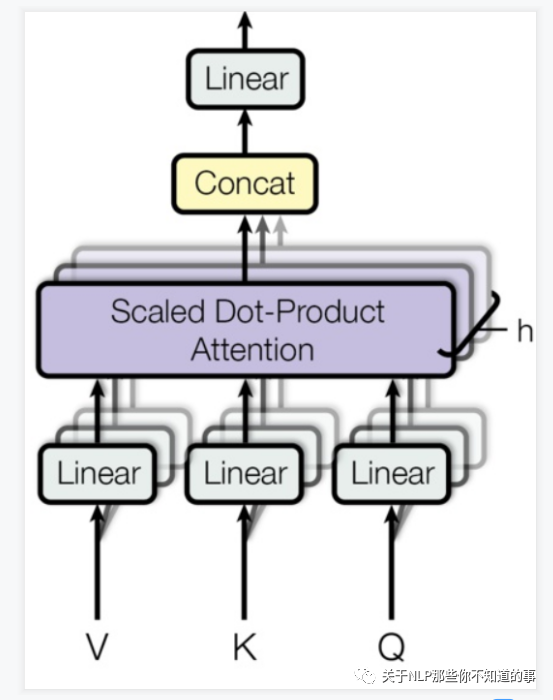
## 参考资料
1. [Transformer理论源码细节详解](https://zhuanlan.zhihu.com/p/106867810)
2. [论文笔记:Attention is all you need(Transformer)](https://zhuanlan.zhihu.com/p/51089880)
3. [深度学习-论文阅读-Transformer-20191117](https://zhuanlan.zhihu.com/p/92234185)
4. [Transform详解(超详细) Attention is all you need论文](https://zhuanlan.zhihu.com/p/63191028)
5. [目前主流的attention方法都有哪些?](https://www.zhihu.com/question/68482809/answer/597944559)
6. [transformer三部曲](https://zhuanlan.zhihu.com/p/85612521)
7. [Character-Level Language Modeling with Deeper Self-Attention](https://aaai.org/ojs/index.php/AAAI/article/view/4182)
8. [Transformer-XL: Unleashing the Potential of Attention Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html)
9. [The Importance of Being Recurrent for Modeling Hierarchical Structure](https://arxiv.org/abs/1803.03585)
10. [Linformer](https://arxiv.org/abs/2006.04768)
