
消息队列(MQ)之生产者-消费者 | 一文搞定
大家好,我是狼王,一个爱打球的程序员
随着互联网的发展,技术也在快速的迭代中,由于大流量,高并发的出现,很多问题也随之而来了,为了解决这些问题,一些高端的人才研究出了各种解决这些问题的东西,
消息队列就是其中一种。那么今天,我们就来聊聊消息队列吧!
什么是消息队列?
消息队列不知道大家看到这个词的时候,会不会觉得它是一个比较高端的技术,反正我是觉得它好像是挺牛逼的。
消息队列,一般我们会简称它为MQ(Message Queue),嗯,就是很直白的简写。
我们先不管消息(Message)这个词,来看看队列(Queue)。这一看,队列大家应该都熟悉吧。
队列是一种先进先出的数据结构。
在Java里边,已经实现了不少的队列了。
那为什么还需要消息队列(MQ)这种中间件呢???
其实这个问题,跟之前我学Redis的时候很像。Redis是一个以key-value形式存储的内存数据库,明明我们可以使用类似HashMap这种实现类就可以达到类似的效果了,那还为什么要Redis?
到这里,大家可以先猜猜为什么要用消息队列(MQ)这种中间件
消息队列可以简单理解为:把要传输的数据放在队列中。
科普:
- 把数据放到消息队列叫做生产者
- 从消息队列里边取数据叫做消费者
市面上的消息队列产品有很多,比如老牌的
ActiveMQ、RabbitMQ,目前比较火的有Kafka,和阿里巴巴捐赠给Apache的RocketMQ,连redis 这样的NoSQL 数据库也支持 MQ 功能。总之这块知名的产品就有十几种。
为什么要用消息队列,也就是在问:用了消息队列有什么好处。
解耦
以常见的订单系统为例
用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发货、发短信通知等。
在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能。
这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发货、发短信通知等。
这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发货或发短信之类的消息时,执行相应的业务逻辑。
简单的说就是原来a服务需要调用b服务的接口或者方法来进行数据的传递,这个时候使用消息队列的话,a服务只需将数据发送到消息队列中,b服务从消息队列中取出相应的数据即可,就实现了解耦
异步
异步其实就是a服务将数据发送到消息队列之后就可以进行返回或者执行其他过程,不需要等待b服务处理数据,从而来提高一些使用异步的业务场景的效率问题
削峰/限流
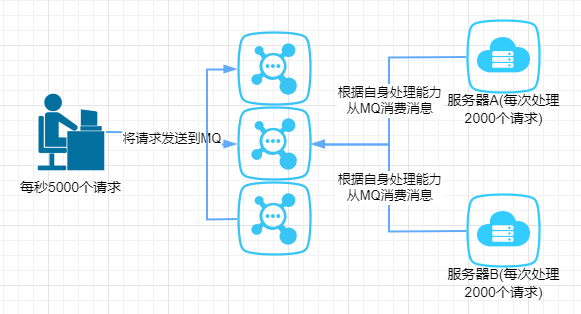
我们再来一个场景,比如现在我们每个月要搞一次大促,大促期间的并发可能会很高的,比如每秒5000个请求。假设我们现在有两台机器处理请求,并且每台机器只能每次处理2000个请求。
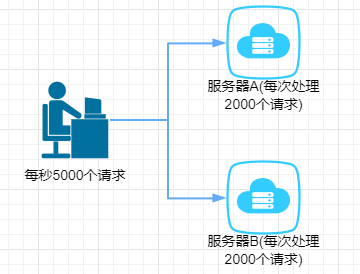
那多出来的1000个请求,可能就把我们整个系统给搞崩了,所以,有一种办法,我们可以写到消息队列中:
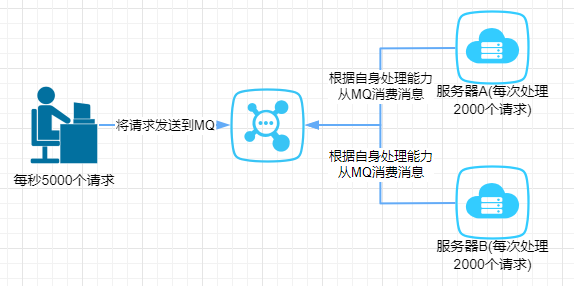
服务器A和服务器B根据自己的能够处理的请求数去消息队列中拿数据,这样即便有每秒有1w个请求,那只是把请求放在消息队列中,去拿消息队列的消息由系统自己去控制,这样就不会把整个系统给搞崩。
使用消息队列有什么问题?
经过我们上面的场景,我们已经可以发现,消息队列能做的事其实还是蛮多的。
说到这里,我们先回到文章的开头,"明明JDK已经有不少的队列实现了,我们还需要消息队列中间件呢?"
其实很简单,JDK实现的队列种类虽然有很多种,但是都是简单的内存队列。为什么我说JDK是简单的内存队列呢?
下面我们来看看要实现消息队列(中间件)可能要考虑什么问题。
高可用
无论是我们使用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的。试着想一下,如果是单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了,就出现了单点故障。
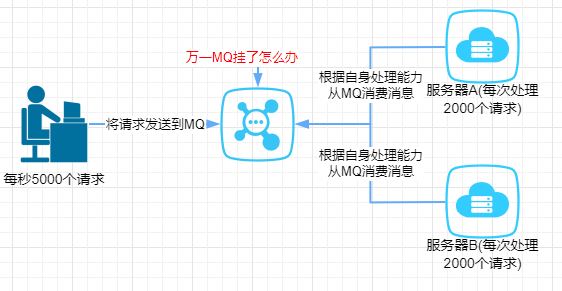
所以,当我们项目中使用消息队列,都是得集群/分布式的。要做集群/分布式就必然希望该消息队列能够提供现成的支持,而不是自己写代码手动去实现。
数据丢失问题
我们将数据写到消息队列上,服务器A和服务器B还没来得及消费消息队列的数据,就挂掉了。如果没有做任何的措施,我们的数据就丢了。
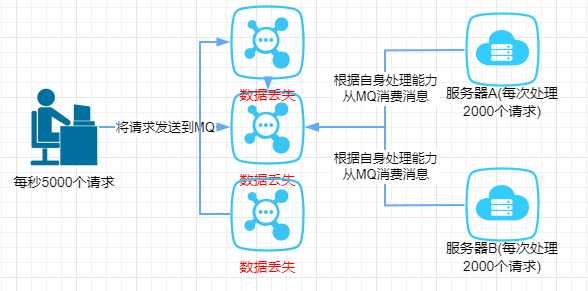
学过Redis的都知道,Redis可以将数据持久化磁盘上,万一Redis挂了,还能从磁盘将数据恢复过来。同样地,消息队列中的数据也需要存在别的地方,这样才尽可能减少数据的丢失。
- 那存在哪呢?
- 磁盘?
- 数据库?
- 同步存储还是异步存储?
不同的MQ针对消息丢失的处理和解决方案都有所不同,但是肯定都是从生产者和消费者两端进行分析的。
生产者端丢失消息
生产者要确保消息发送到了MQ,就会有回调确认机制的处理和事务的方式
消息队列丢失消息
在消息队列中假如因为MQ挂了导致消息丢了,那么就可以将消息持久化,或者使用生产者端重发消息的方式
消费者端丢消息
一般消费者丢了消息的原因就是从MQ中取到了消息,但是可能消费失败了需要重新消费,但是MQ中已经没有该条消息了,这样的话可以通过消费者端手动确认的机制,或者让生产者端重发消息的方式
消费者怎么得到消息队列的数据?
消费者怎么从消息队列里边得到数据?一般有两种办法:
- 生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push)
- 消费者不断去轮训消息队列,看看有没有新的数据,如果有就消费(俗称pull)
其他问题
除了这些,我们在使用的时候还得考虑各种的问题:
消息重复消费了怎么办啊?我想保证消息是绝对有顺序的怎么做?……..
虽然消息队列给我们带来了那么多的好处,但同时我们发现引入消息队列也会提高系统的复杂性。市面上现在已经有不少消息队列轮子了,每种消息队列都有自己的特点,选取哪种MQ还得好好斟酌。
这次我们先来讲讲RabbitMQ
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP : Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
可靠性(Reliability)RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。灵活的路由(Flexible Routing)在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。消息集群(Clustering)多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。高可用(Highly Available Queues)队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。多种协议(Multi-protocol)RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。多语言客户端(Many Clients)RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。管理界面(Management UI)RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。跟踪机制(Tracing)如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。插件机制(Plugin System)RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
RabbitMQ 中的概念模型
消息模型
所有 MQ 产品从模型抽象上来说都是一样的过程:消费者(consumer)订阅某个队列。生产者(producer)创建消息,然后发布到队列(queue)中,最后将消息发送到监听的消费者。
RabbitMQ 基本概念
上面只是最简单抽象的描述,具体到 RabbitMQ 则有更详细的概念需要解释。上面介绍过 RabbitMQ 是 AMQP 协议的一个开源实现,所以其内部实际上也是 AMQP 中的基本概念:
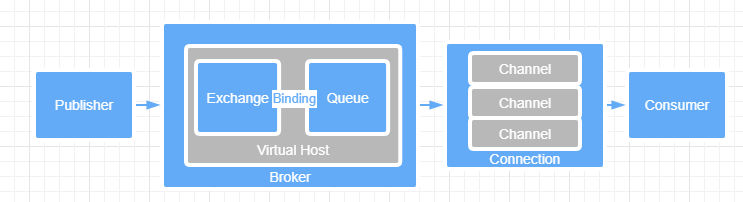
Message 消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。Publisher 消息的生产者,也是一个向交换器发布消息的客户端应用程序。Exchange 交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。Binding 绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Queue 消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。Connection 网络连接,比如一个TCP连接。Channel 信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。Consumer 消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。Virtual Host 虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。Broker表示消息队列服务器实体。
本文主要讲解了什么是消息队列,消息队列可以为我们带来什么好处,以及一个消息队列可能会涉及到哪些问题,后来会更加深入的去探讨哦!希望给大家带来一定的帮助。
好了。今天就说到这了,我还会不断分享自己的所学所想,希望我们一起走在成功的道路上!
转发朋友圈是对我最大的支持!乐于输出干货的Java技术公众号:狼王编程。公众号内有大量的技术文章、海量视频资源、精美脑图,不妨来关注一下!回复资料领取大量学习资源和免费书籍!
 觉得有点东西就点一下“赞和在看”吧!感谢大家的支持了!
觉得有点东西就点一下“赞和在看”吧!感谢大家的支持了!