
内核调试利器|ftrace 使用教程
1. 位置无关码
加载地址:存储代码的物理地址。如ARM64处理器上电复位后是从0x0地址开始第一条指令的,所以通常这个地方存放代码最开始的部分,如异常向量表的处理地址
运行地址:指程序运行时的地址
链接地址:在编译链接时指定的地址,编程人员设想将来程序要运行的地址。程序所有标号的地址在链接后便确定了,不管程序在哪里运行都不会改变。aarch64-linux-gnu-obidump (objdump)工具进行反汇编查看的就接地链接地址
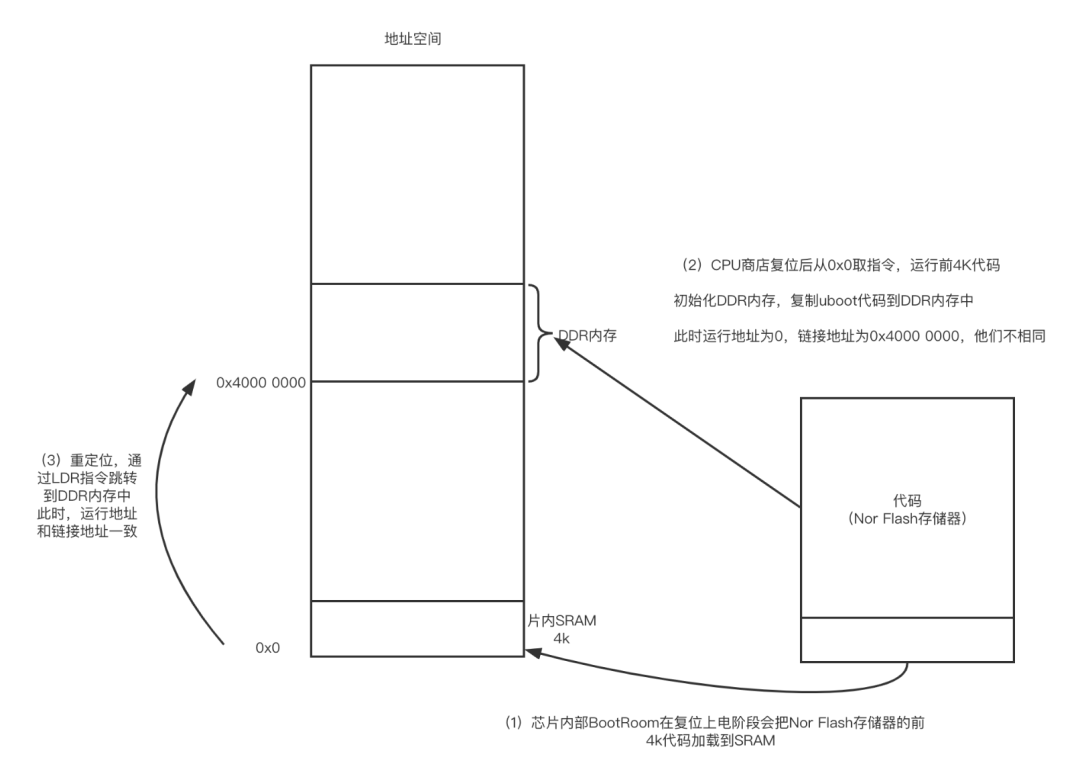
链接地址和运行地址可以相同,也可以不同。那什么时候运行地址和链接地址不相同,什么时候相同呢?我们以一块ARM64开发板为例,芯片内部有SRAM,起始地址为0x0,DDR内存的起始地址为0x4000 0000。
通常代码存储在 Nor Flash存储器或者 Nand Flash存储器中,芯片内部的 BOOT ROM会把开始的小部分代码装载到SRAM中运行。芯片上电复位之后,从SRAM中取指令。由于 Uboot的镜像太大了,SRAM放不下,因此必须要放在DDR内存中。通常Uboot编译时链接地址都没置到DDR内存中,也就是0x4000 0000地址处。那这时运行地址和链接地址就不一样了。运行地址为0x0,链接地址变成了0x4000 0000那么程序为什么还能运行呢个重要问题,就是位置无关代码和位置有关代码。
位置无关代码:从字面意思看,该指令的执行是与内存地址无关的;无论运行地址和链接地址相等或者不相等,该指令都能正常运行。在汇编语言中,像BL、B、MOV指令属于位置无关指令,不管程序装载在哪个位置,它们都能正确地运行,它们的地址域是基于PC值的相对偏移寻址,相当于[pc+offset]
位置有关代码:从字面意思看,该指令的执行是与内存地址有关的,和当前PC值无关。ARM汇编里面通过绝对跳转修改PC值为当前链接地址的值
1 | ldr pc, = on_sdram ;跳到 SDRAM中继续执行 |
因此,当通过LDR指令跳转到链接地址处执行时,运行地址就等于链接地址了。这个过程叫作“重定位”。在重定位之前,程序只能执行和位置无关的一些汇编代码。为什么要刻意设置加载地址、运行地址以及链接地址不一样呢?如果所有代码都在ROM(或 Nor Flash存储器)中执行,那么链接地址可以与加载地址相同;而在实际项目应用中,往往想要把程序加载到DDR内存中,DDR内存的访问速度比ROM要快很多,而且容量也大。但是碍于加载地址的影响,不可能直接达到这一步,所以思路就是让程序的加载地址等于ROM起始地址,而链接地址等于DDR内存中某一处的起始地址(暂且称为 ram start)。程序先从ROM中启动,最先启动的部分要实现代码复制功能(把整个ROM代码复制到DDR内存中),并通过LDR指令来跳转到DDR内存中,也就是在链接地址里运行B指令没法实现这个跳转)。上述重定位过程在U-Boot中实现,如图所示。
当跳转到 Linux内核中时,U-Boot需要把 Linux内核映像内容复制到DDR内存中,然后跳转到内核入口地址处( stext函数)。当跳转到内核入口地址( stext函数)时,程序运行在运行地址,即DDR内存的地址。但是我们从 vmlinux看到的 stext 函数的链接地址是虚拟地址(内核启动汇编代码也需要一个重定位过程。这个重定位过程在__primary_switch()汇编函数中完成。启动MMU之后,通过ldr指令把 __primary_switched()函数的链接地址加载到x8寄存器,然后通过br指令跳转到 __primary_switched()函数的链接地址处,从而实现了重定位,如图所示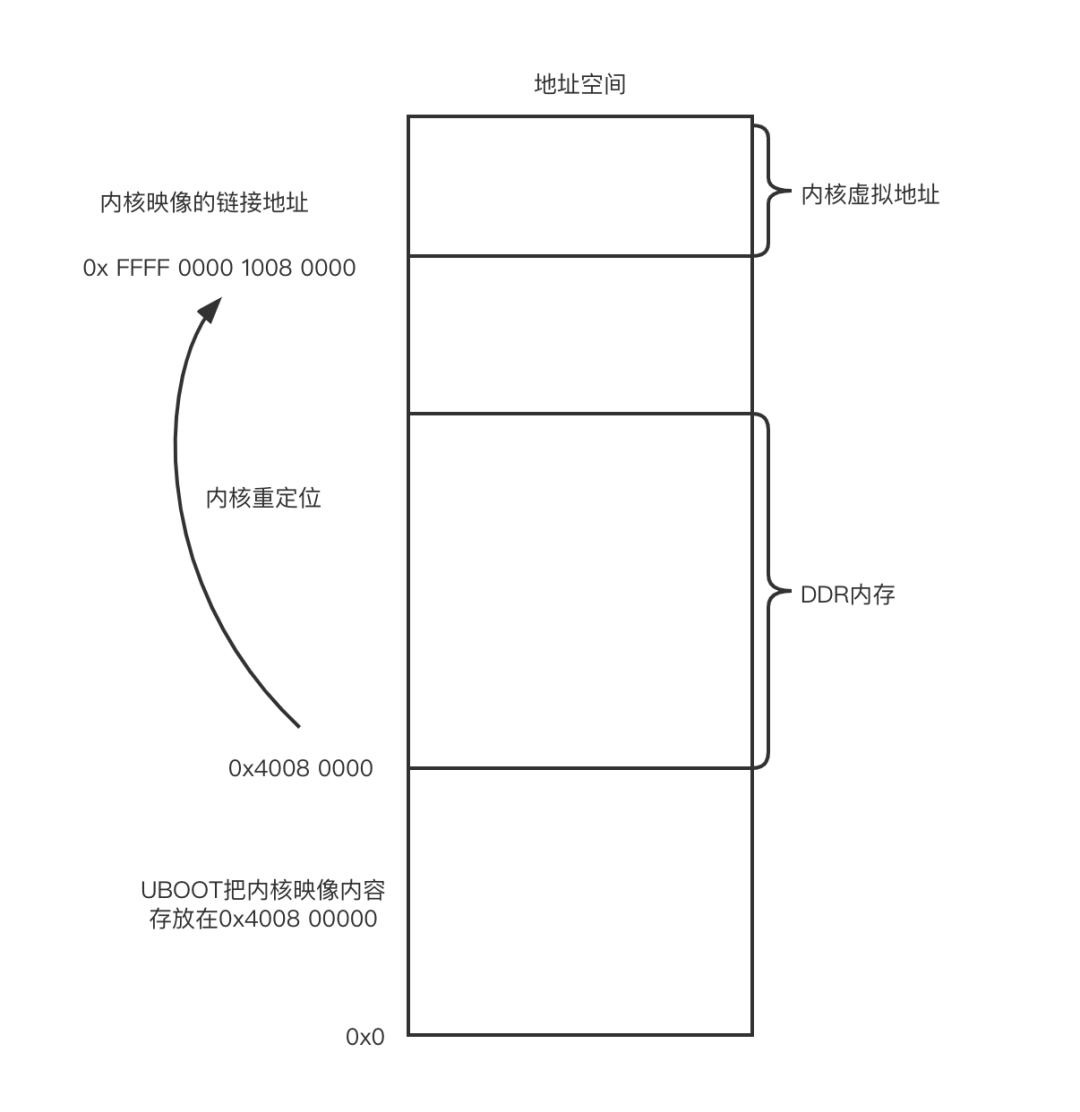
1 | <arch/arm64/kernel/head.S> |
2. ftrace
frace最早出现在 Linux2.6.27内核中,其设计目标简单,基于静态代码插桩(stub)技术,不需要用户通过额外的编程来定义 trace行为。静态代码插桩技术比较可靠,不会因为用户使用不当而导致内核崩溃。ftrace 的名字源于 function trace利用GCC的 profile特性在所有函数入口处添加一段插桩代码, ftrace重载这段代码来实现 trace 功能。GCC的-pg选项会在每个函数入口处加入 mcount的调用代码,原本 mcount有libc实现,而内核不会链接libc库,因此frace编写了自己的mcount stub函数。在使用ftrace之前,需要确保内核编译配置选项。
1 | CONFIG_FTRACE=y |
ftrace的相关配置选项比较多,针对不同的跟踪器有各自对应的配置选项。ftrace通过debugfs文件系统向用户空间提供访间接口,因此需要在系统启动时挂载 debugfs,可以修改系统的 /etc/fstab文件或手动挂载。
1 | mount -t debugfs debugfs/sys/kernel/debug |
在 sys/kernel/debug/trace目录下提供了各种跟踪器( tracer)和事件( event),一些常用的选项如下。
available_tracers:列出当前系统支持的跟踪器
available_events:列出当前系统支持的事件
current_tracer:设置和显示当前正在使用的跟踪器。使用echo命令把跟踪器的名字写入该文件,即可切换不同的跟踪器。默认为nop,即不做任何跟踪操作
trace: 读取跟踪信息。通过cat命令查看 ftrace记录下来的眼踪信息
tracing_on:用于开始或暂停跟踪
trace_options:设置 ftrace的一些相关选项
ftrace当前包含多个跟踪器,方便用户跟踪不同类型的信息,如进程睡眠、唤醒、抢占、延迟的信息。查看 available_tracers可以知道当前系统支持哪些跟踪器,如果系统支持的跟踪器上没有用户想要的。那就必须在配置内核时打开,然后重新编译内核。常用的ftrace跟踪器如下所示:
nop:不跟踪任何信息。将nop写入current_tracer文件可以清空之前收集到的跟踪信息
function:跟踪内核函数执行情况
function_graph:可以显示类似于C语言的函数调用关系图,比较直观
hwlat:用来跟踪与硬件相关的延时
blk:跟踪块设备的函数
mmiotrace:用于跟踪内存映射I/O操作
wakeup:跟踪普通优先级的进程从获得调度到被唤醒的最长延迟时间
weakup_rt:跟踪RT类型的任务从获得调度到被唤醒的最长延迟时间
irqoff:跟踪关闭中断的信息,并记录关闭的最大时长
preemptoff:跟踪关闭禁止抢占的信息,并记录关闭的最大时长
3. irqs跟踪器
当中断关闭(俗称关中断)后,CPU就不能响应其他的事件。如果这时有一个鼠标中断,要在下一次开中断时才能响应这个中断,这段延时称为中断延迟。向current_tracer文件写入 irqsoff字符串即可打开 irqsoff来跟踪中断延迟。
1 | cd /sys/kernel/debug/tracing/ |
4. Function tracing - no modification necessary
Ftrace 最强大的追踪器之一是函数追踪器。它使用gcc的-pg选项让内核中的每个函数调用一个特殊的函数“ mcount() ”。该函数必须在汇编中实现,因为调用不遵循正常的 C ABI。
当配置 CONFIG_DYNAMIC_FTRACE 时,调用会在启动时转换为 NOP,以保持系统以 100% 的性能运行。在编译过程中,记录了 mcount() 调用站点。该列表在启动时用于将这些站点转换为 NOP。由于 NOP 对跟踪毫无用处,因此当启用函数(或函数图)跟踪器时,保存该列表以将调用站点转换回跟踪调用。
由于此性能增强,强烈建议启用 CONFIG_DYNAMIC_FTRACE。此外,CONFIG_DYNAMIC_FTRACE 提供了筛选应跟踪哪个函数的能力。请注意,即使 NOP 在基准测试中没有显示任何影响,但已知添加-pg选项附带的帧指针会导致轻微的开销。
要找出哪些跟踪器可用,只需在跟踪目录中查找available_tracers文件即可 :
1 | [tracing]# cat available_tracers |
要启用函数跟踪器,只需将“function” echo 到 current_tracer文件中。
1 | [tracing]# echo function > current_tracer |
标题很好地解释了输出的格式。前两项是跟踪的任务名称和 PID。执行跟踪的 CPU 位于括号内。时间戳是自启动以来的时间,后跟函数名称。在这种情况下,函数是被跟踪的函数,其父函数跟在“ <- ”符号之后。
这些信息非常强大,并且很好地显示了函数的流程。但这可能有点难以遵循。由 Frederic Weisbecker 创建的函数图跟踪器跟踪函数的进入和退出,这使跟踪器能够了解被调用函数的深度。函数图跟踪器可以使人眼更容易跟踪内核中的执行流程:
1 | [tracing]# echo function_graph > current_tracer |
这给出了一个函数的开始和结束,用类似 C 的注释“ { ”来启动一个函数,“ } ”在末尾。叶函数不调用其他函数,只是以“ ; ”结尾。DURATION 列显示在相应函数中花费的时间。函数图跟踪器记录函数进入和退出的时间,并将差异报告为持续时间。这些数字只出现在叶函数和“ }" 符号。注意,这次还包括嵌套函数内所有函数的开销以及函数图跟踪器本身的开销。函数图跟踪器劫持了函数的返回地址,以便为函数插入跟踪回调函数退出。这会破坏 CPU 的分支预测并导致比函数跟踪器更多的开销。最接近的真实时序仅发生在叶函数中。
孤独的“ + ”是有一个注释标记。当持续时间大于 10 微秒时,显示“ + ”。如果持续时间大于 100 微秒,将显示“ !”。
5. Using trace_printk()
printk()是所有调试器之王,但它有一个问题。如果您正在调试诸如定时器中断、调度程序或网络之类的大容量区域,printk()可能会导致系统陷入困境,甚至可能会创建实时锁。添加一些printk()时,看到错误“消失”也很常见。这是由于printk()引入的绝对开销。
Ftrace 引入了一种新形式的printk()称为 trace_printk()。它可以像printk()一样使用,也可以在任何上下文中使用(中断代码、NMI 代码和调度程序代码)。是什么样的好的trace_printk()是,它不会输出到控制台。相反,它写入 Ftrace 环形缓冲区,并且可以通过跟踪文件读取。
使用trace_printk()写入环形缓冲区只需要大约十分之一微秒左右。但是使用printk(),尤其是在写入串行控制台时,每次写入可能需要几毫秒。trace_printk()的性能优势 使您可以记录内核中最敏感的区域,而几乎没有影响。
例如,您可以将这样的内容添加到内核或模块中:
1 | trace_printk("read foo %d out of bar %p\n", bar->foo, bar); |
然后通过查看跟踪文件,您可以看到您的输出。
1 | [tracing]# cat trace |
上面的示例是通过添加一个实际上具有foo和bar构造的模块来完成的 。
trace_printk()输出将出现在任何跟踪器中,甚至是函数和函数图跟踪器。
1 | [tracing]# echo function_graph > current_tracer |
是的,trace_printk() 输出看起来像函数图跟踪器中的注释。
6. Starting and stopping the trace
显然,有时您只想跟踪特定的代码路径。也许您只想跟踪运行特定测试时发生的情况。文件tracing_on用于禁止环形缓冲区记录数据:
1 | [tracing]# echo 0 > tracking_on |
这将禁用 Ftrace 环形缓冲区的记录。其他所有事情仍然发生在跟踪器上,它们仍然会产生大部分开销。他们确实注意到环形缓冲区没有记录,也不会尝试写入任何数据,但仍会执行跟踪器发出的调用。
要重新启用环形缓冲区,只需将“1”写入该文件:
1 | [tracing]# echo 1 >tracing_on |
请注意,在数字和大于号“ > ”之间有一个空格非常重要。否则,您可能正在将标准输入或输出写入该文件。
1 | [tracing]# echo 0>tracing_on /* 这行不通!*/ |
一个常见的运行可能是:
1 | [tracing]# echo 0 > tracing_on |
第一行禁止环形缓冲区记录任何数据。接下来启用函数图跟踪器。函数图跟踪器的开销仍然存在,但不会将任何内容记录到跟踪缓冲区中。最后一行启用环形缓冲区,运行测试程序,然后禁用环形缓冲区。这缩小了函数图跟踪器存储的数据范围,以仅包括run_test程序积累的数据 。
7. Trace Markers
查看内核内部发生的事情可以让用户更好地了解他们的系统是如何工作的。但有时需要在用户空间发生的事情和内核内部发生的事情之间进行协调。跟踪中显示的时间戳都与跟踪中发生的事情有关,但它们与墙时间不太对应。
为了帮助同步用户空间和内核空间中的操作,创建了trace_marker文件。它提供了一种从用户空间写入 Ftrace 环形缓冲区的方法。该标记随后将出现在轨迹中,以给出轨迹中特定事件发生的位置。
1 | [tracing]# echo hello world > trace_marker |
在<...>表示该写的标记任务的名字没有记录。未来的版本可能会解决这个问题。
8. Starting, Stopping and Recording in a Program
该tracing_on和trace_marker 文件的工作很好地跟踪应用程序的活动,如果应用程序的源可用。如果应用程序中存在问题并且您需要找出应用程序特定位置的内核内部发生了什么,这两个文件就派上用场了。
在应用程序启动时,您可以打开这些文件以准备好文件描述符:
1 | int trace_fd = -1; |
然后,在代码中的某个关键位置,可以放置标记以显示应用程序当前所在的位置:
1 | if (marker_fd >= 0) |
在查看示例时,您首先会看到一个名为“find_debugfs()”的函数。挂载调试文件系统的正确位置是/sys/kernel/debug但强大的工具不应依赖于挂载在那里的调试文件系统。find_debugfs()的示例 位于此处。文件描述符被初始化为 -1 以允许此代码在启用和不启用跟踪的内核的情况下工作。
当检测到问题时,将 ASCII 字符“0”写入trace_fd文件描述符将停止跟踪。正如在第 1 部分中讨论的那样,这只会禁用记录到 Ftrace 环形缓冲区中,但跟踪器仍然会产生开销。
使用上面的初始化代码时,跟踪将在应用程序开始时启用,因为跟踪器以覆盖模式运行。也就是说,当跟踪缓冲区填满时,它将删除旧数据并用新数据替换它。由于在出现问题时只有最近的跟踪信息是相关的,因此在应用程序正常运行期间无需停止和启动跟踪。只有在检测到问题时才需要禁用跟踪器,以便跟踪记录导致错误的历史记录。如果应用程序中需要间隔跟踪,它可以将 ASCII“1”写入 trace_fd 以启用跟踪。
下面是一个名为simple_trace.c的简单程序示例, 它使用上述初始化过程:
1 | req.tv_sec = 0; |
(由于这是一个仅用于示例目的的简单程序,因此未添加错误检查。) 这是跟踪这个简单程序的过程:
1 | [tracing]# echo 0 > tracing_on |
第一行禁用跟踪,因为程序将在启动时启用它。接下来选择函数图跟踪器。程序被执行,结果如下。请注意,输出可能有点冗长,其中大部分内容已被删除并替换为 [...]:
1 | [...] |
请注意,对 trace_marker 的写入在函数图跟踪器中显示为注释。这里的第一列代表 CPU。当我们像这样交错 CPU 跟踪时,可能很难读取跟踪。工具 grep 可以很容易地过滤它,或者可以使用 per_cpu 跟踪文件。per_cpu 跟踪文件位于 per_cpu 下的 debugfs 跟踪目录中。
1 | [tracing]# ls per_cpu |
在这些 CPU 目录中的每一个目录中都存在一个跟踪文件,仅显示该 CPU 的跟踪。要在不受其他 CPU 干扰的情况下更好地了解函数图跟踪器,只需查看 per_cpu/cpu0/trace。
1 | [tracing]# cat per_cpu/cpu0/trace |
9. Disabling the Tracer Within the Kernel
在内核驱动程序的开发过程中,可能会存在测试过程中出现的奇怪错误。也许驱动陷入睡眠状态,永远不会醒来。当内核事件发生时,试图从用户空间禁用跟踪器是很困难的,通常会导致缓冲区溢出和相关信息丢失,然后用户才能停止跟踪。
有两个在内核中运行良好的函数:tracing_on()和tracking_off()。这两个行为就像分别将“1”或“0” echo 到tracing_on文件中一样。如果内核中存在可以检查的某些条件,则可以通过添加如下内容来停止跟踪器:
1 | if (test_for_error()) |
接下来,添加几个trace_printk() s(参见第 1 部分),重新编译并引导内核。然后,您可以启用函数或函数图跟踪器,然后等待错误条件发生。检查tracing_on 文件将让您知道错误条件何时发生。当内核调用tracking_off()时,它将从“1”切换到“0” 。
检查跟踪后,或将其保存在另一个文件中:
1 | cat trace > ~/trace.sav |
您可以继续跟踪以检查另一个命中。为此,只需将“1” echo 到tracing_on 中,跟踪将继续。如果可以合法触发触发tracing_off()调用的条件,这也很有用 。如果条件是由正常操作触发的,只需通过在tracing_on 中echo “1”来重新启动跟踪,希望下次遇到条件时将是因为异常。
10. ftrace_dump_on_oops
有时内核会崩溃,检查内存和崩溃状态更像是一门 CSI 科学,而不是程序调试科学。将kdump / kexec与crash 实用程序一起使用是检查崩溃点系统状态的一种有价值的方法,但它不会让您看到在导致崩溃的事件之前发生了什么。
在内核引导参数中配置 Ftrace 并启用ftrace_dump_on_oops,或者通过在/proc/sys/kernel/ftrace_dump_on_oops 中echo “1” ,将使 Ftrace 能够在 oops 或 panic 时以 ASCII 格式将整个跟踪缓冲区转储到控制台。将控制台输出到串行日志使调试崩溃更容易。您现在可以追溯导致崩溃的事件。
转储到控制台可能需要很长时间,因为默认的 Ftrace 环形缓冲区每个 CPU 超过 1 兆字节。要缩小环形缓冲区的大小,请将希望环形缓冲区的千字节数写入 buffer_size_kb。请注意,该值是每个 CPU,而不是环形缓冲区的总大小。
1 | [tracing]# echo 50 > buffer_size_kb |
以上将把 Ftrace 环形缓冲区缩小到每个 CPU 50 KB。您还可以使用sysrq-z将 Ftrace 缓冲区的转储触发到控制台 。
要为内核转储选择特定位置,内核可以直接调用 ftrace_dump()。请注意,这可能会永久禁用 Ftrace,可能需要重新启动才能再次启用它。这是因为 ftrace_dump()读取缓冲区。缓冲区被写入所有上下文(中断、NMI、调度),但缓冲区的读取需要锁定。为了能够执行ftrace_dump()锁定被禁用并且缓冲区可能最终在输出后被破坏。
1 | /* |
11. Stack Tracing
最后要讨论的主题是检查内核堆栈大小以及每个函数使用多少堆栈空间的能力。启用堆栈跟踪器 ( CONFIG_STACK_TRACER ) 将显示堆栈的最大使用发生在哪里。
堆栈跟踪器是从函数跟踪器基础结构构建的。它不使用 Ftrace 环形缓冲区,但确实使用函数跟踪器来挂钩每个函数调用。因为它使用函数跟踪器基础结构,所以在未启用时不会增加开销。要启用堆栈跟踪器,请将 1 echo 到 /proc/sys/kernel/stack_tracer_enabled 中。要查看启动期间的最大堆栈大小,请将“ stacktrace ”添加到内核启动参数。
堆栈跟踪器在每次函数调用时检查堆栈的大小。如果它大于最后记录的最大值,它会记录堆栈跟踪并使用新大小更新最大值。要查看当前最大值,请查看 stack_max_size文件。
1 | [tracing]# echo 1 > /proc/sys/kernel/stack_tracer_enabled |
这不仅为您提供了找到的最大堆栈的大小,还显示了每个函数使用的堆栈大小的细分。请注意, write_cache_pages的堆栈最大,使用了 304 个字节,其次是generic_make_request,使用了 224 个字节的堆栈。
要重置最大值,请将“0”回显到stack_max_size 文件中。
1 | [tracing]# echo 0 > stack_max_size |
保持运行一段时间将显示内核使用过多堆栈的位置。但请记住,堆栈跟踪器只有在未启用时才没有开销。当它运行时,您可能会注意到性能有所下降。
请注意,当内核使用单独的堆栈时,堆栈跟踪器不会跟踪最大堆栈大小。因为中断有自己的堆栈,它不会跟踪那里的堆栈使用情况。原因是当堆栈不是当前任务的堆栈时,目前没有简单的方法可以快速查看堆栈的顶部是什么。使用拆分堆栈时,进程堆栈可能是两页,而中断堆栈可能只有一页。这可能会在未来修复,但在使用堆栈跟踪器时请记住这一点。
12. Function filtering
运行函数跟踪器可能会让人不知所措。数据量可能很大,人脑很难掌握。Ftrace 提供了一种方法来限制您看到的功能。存在两个文件,可让您限制跟踪的功能:
1 | set_ftrace_filter |
这些过滤功能取决于CONFIG_DYNAMIC_FTRACE 选项。如前几篇文章所述,当启用此配置时,所有mcount调用者位置都将被存储,并在启动时转换为 NOP。这些位置被保存并用于在功能跟踪器被激活时启用跟踪。但这也有一个很好的副作用:并非所有功能都必须启用。上述文件将确定哪些功能被启用,哪些不启用。
当set_ftrace_filter 中列出任何函数时,只会跟踪那些函数。当跟踪处于活动状态时,这将有助于系统的性能。跟踪每个函数会产生很大的开销,但是在使用set_ftrace_filter 时,只有该文件中列出的那些函数才会更改 NOP 以调用跟踪器。根据正在跟踪的功能,仅启用几百个功能几乎不会引起注意。
该set_ftrace_notrace文件是相反set_ftrace_filter。不是将跟踪限制为一组函数,而是不会跟踪set_ftrace_notrace 中列出的函数。某些函数经常出现,跟踪这些函数不仅会减慢系统速度,还会填满跟踪缓冲区,并使分析您关心的函数变得更加困难。rcu_read_lock()和spin_lock()等函数 属于这一类。
向这些文件添加函数的过程通常使用 bash 重定向。使用符号“>”将删除文件中的所有现有函数并将正在回显的内容添加到文件中。使用“>>”附加到文件将保留现有功能并添加新功能。
1 | [tracing]# echo sys_read > set_ftrace_filter |
要删除所有功能,只需在过滤器文件中回显一个空行即可。
1 | [tracing]# echo sys_read sys_open sys_write > set_ftrace_notrace |
这些文件中列出的函数也可以在内核命令行上设置。选项 ftrace_notrace 和 ftrace_filter 将通过列出逗号分隔的函数集来预设这些文件。
ftrace_notrace=rcu_read_lock,rcu_read_unlock,spin_lock,spin_unlock
ftrace_filter=kfree,kmalloc,schedule,vmalloc_fault,spurious_fault内核命令行添加的函数设置了相应过滤器文件中的内容。这些选项仅预加载文件,仍然可以使用如上所述的 bash 重定向来删除或添加功能。set_ftrace_notrace 中列出的函数优先。也就是说,如果一个函数同时列在 set_ftrace_notrace 和 set_ftrace_filter 中,则不会跟踪该函数。
13. Wildcard filters
可以添加到过滤器文件的函数列表显示在 available_filter_functions 文件中。这个函数列表源自前面提到的存储的 mcount 调用者列表。
1 | [tracing]# cat available_filter_functions | head -8 |
您可以 grep 此文件并将结果重定向到过滤器文件之一:
1 | [tracing]# grep sched available_filter_functions > set_ftrace_filter |
不幸的是,向过滤文件添加大量函数很慢,您会注意到上面的 grep 需要几秒钟才能执行。这是因为写入过滤器文件的每个函数名称将被单独处理。上面的 grep 产生了 300 多个函数名。这 300 个名称中的每一个都将与内核中的每个函数名称进行比较(使用 strcmp()),这相当多。
1 | [tracing]# wc -l available_filter_functions |
所以上面的 grep 导致set_ftrace_filter生成超过 300 * 24331 (7,299,300) 次比较!
幸运的是,这些文件也使用通配符;以下 glob 表达式是有效的:
value* - 选择所有以value开头的函数。*value* - 选择所有包含文本value 的函数。*value - 选择所有以value结尾的函数。
内核包含一个相当简单的解析器,不会以预期的方式处理 value*value。它将忽略第二个 值并选择所有以value开头的函数,而不管它以什么结尾。传递给过滤器文件的通配符直接针对每个可用函数进行处理,这比在列表中传递单个函数要快得多。
因为 bash 也使用星号 (*),所以最好用引号将输入括起来:
1 | [tracing]# echo set* > set_ftrace_filter |
过滤器还可以通过在过滤器文件的输入中使用“mod”命令来仅选择属于特定模块的那些函数:
1 | [tracing]# echo ':mod:tg3' > set_ftrace_filter |
如果您正在调试单个模块,并且只想在跟踪中查看属于该模块的函数,这将非常有用。
在之前的文章中,启用和禁用记录到环形缓冲区是使用tracing_on文件以及tracing_on()和 tracing_off()内核函数完成的。但是,如果您不想重新编译内核,并且想在特定函数处停止跟踪,则 set_ftrace_filter有一个方法可以这样做。使功能跟踪启用或禁用环形缓冲区的命令格式如下:
function:command[:count]这将在函数开始 时执行命令。该命令是 traceon或traceoff,并且可以添加一个可选的计数以使命令只执行给定的次数。如果计数被保留(包括前导冒号),则每次调用该函数时都会执行该命令。
不久前,我正在调试对内核所做的更改,该更改导致某些程序出现分段错误。我很难捕捉到跟踪,因为当我看到分段错误后能够停止跟踪时,数据已经被覆盖了。但是控制台上的回溯显示正在调用函数__bad_area_nosemaphore。然后我可以使用以下命令停止跟踪器:
1 | [tracing]# echo '__bad_area_nosemaphore:traceoff' > set_ftrace_filter |
请注意,带有命令的函数不会影响一般过滤器。即使已将命令添加到 __bad_area_nosemaphore,过滤器仍允许跟踪所有函数。命令和过滤器功能是分开的,互不影响。将上述命令附加到函数 __bad_area_nosemaphore 后,下次发生分段错误时,跟踪停止并包含调试情况所需的数据。
14. Removing functions from the filters
如前所述,用“>”回显将清除过滤器文件。但是如果您只想从过滤器中删除一些功能怎么办?
1 | [tracing]# cat set_ftrace_filter > /tmp/filter |
上述工作,但如前所述,如果 set_ftrace_filter 中已有多个函数,则可能需要一段时间才能完成。以下执行相同的操作,但速度要快得多:
1 | [tracing]# echo '!*lock*' >> set_ftrace_filter |
这 '!'符号将删除过滤器文件中列出的函数。如上所示,“!”与通配符一起使用,但也可以与单个函数一起使用。自从 '!'在 bash 中具有特殊含义,它必须用单引号括起来,否则 bash 将尝试执行其后的内容。另请注意使用了“>>”。如果您错误地使用了“>”,则过滤器文件中将没有任何功能。因为命令和过滤器不会相互干扰,清除 set_ftrace_filter 不会清除命令。命令必须用“!”清除象征。
1 | [tracing]# echo 'sched*' > set_ftrace_filter |
这可能看起来很别扭,但是使用“>”和“>>”只影响要跟踪的函数而不影响函数命令,实际上简化了过滤函数和添加和删除命令之间的控制。
15. Tracing a specific process
也许您只需要跟踪一个特定的进程或一组进程。文件 set_ftrace_pid 允许您指定要跟踪的特定进程。要仅跟踪当前线程,您可以执行以下操作:
1 | [tracing]# echo $$ > set_ftrace_pid |
上面将设置函数 tracer 只跟踪执行 echo 命令的 bash shell。如果要跟踪特定进程,可以创建一个 shell 脚本包装程序。
1 | [tracing]# cat ~/bin/ftrace-me |
请注意,如果要在执行上述操作后返回通用函数跟踪,则必须清除 set_ftrace_pid 文件。
1 | [tracing]# echo -1 > set_ftrace_pid |
16. What calls a specific function?
有时了解什么在调用特定函数很有用。直接前任很有帮助,但整个回溯甚至更好。函数跟踪器包含一个选项,该选项将为跟踪器调用的每个函数在环形缓冲区中创建一个回溯。由于为每个函数创建回溯具有很大的开销,这可能会实时锁定系统,因此在使用此功能时必须小心。想象一下运行在 1000 HZ 的较慢系统上的定时器中断。很可能让定时器中断调用产生回溯的每个函数需要 1 毫秒才能完成。到定时器中断返回时,将在任何其他工作完成之前触发一个新的中断,从而导致活锁。
要使用函数跟踪器回溯功能,被调用的函数必须受到函数过滤器的限制。启用函数回溯的选项是函数跟踪器独有的,只有在启用函数跟踪器时才能激活它。这意味着您必须先启用函数跟踪器,然后才能访问该选项:
1 | [tracing]# echo kfree > set_ftrace_filter |
请注意,在启用 func_stack_trace 选项以确保启用过滤器之前,我小心地对 set_ftrace_filter 进行分类。最后,我在禁用过滤器之前禁用了 options/func_stack_trace。还要注意该选项是非易失性的,也就是说,即使您在 current_tracer 中启用了另一个跟踪器插件,如果您重新启用跟踪器功能,该选项仍然会启用。
17. The function_graph tracer
函数跟踪器非常强大,但可能很难理解它产生的线性格式。Frederic Weisbecker 已将函数跟踪器扩展到 function_graph 跟踪器。function_graph 跟踪器搭载了大部分由函数跟踪器创建的代码,但在mcount调用中添加了自己的钩子。因为它仍然使用mcount调用方法,所以上面解释的大部分函数过滤也适用于 function_graph 跟踪器,但traceon / traceoff命令和set_ftrace_pid 除外(尽管后者将来可能会改变)。function_graph tracer在之前的文章中也有说明,但是set_graph_function文件没有说明。上一节中使用的func_stack_trace可以看到什么可能调用一个函数,但是set_graph_function可以用来查看一个函数调用了什么:
1 | [tracing]# echo kfree > set_graph_function |
这将显示仅由kfree()执行的调用图。“ ==========> ”表示通话过程中发生了中断。跟踪记录kfree() 块中的所有函数,甚至是那些在kfree()范围内触发的中断调用的函数。
function_graph 跟踪器显示函数在持续时间字段中花费的时间。在之前的文章中提到,只有叶子函数,即不调用其他函数的叶函数,才有准确的持续时间,因为父函数的持续时间还包括 function_graph 跟踪器调用子函数的开销。通过使用set_ftrace_filter文件,您可以强制任何函数成为 function_graph 跟踪器中的叶函数,这将允许您查看该函数的准确持续时间。
1 | [tracing]# echo smp_apic_timer_interrupt > set_ftrace_filter |
上面显示定时器中断需要 16 到 26 微秒才能完成。
18. Function profiling
oprofile和perf是非常强大的分析工具,它们定期对系统进行采样,并可以显示大部分时间都花在了什么地方。使用函数分析器,可以很好地查看实际的函数执行情况,而不仅仅是示例。如果内核中配置了CONFIG_FUNCTION_GRAPH_TRACER,则函数分析器将使用函数图基础结构来记录函数执行了多长时间。如果只配置了CONFIG_FUNCTION_TRACER,函数分析器将只计算被调用的函数。
1 | [tracing]# echo nop > current_tracer |
以上还包括函数被抢占或 schedule() 被调用以及任务被换出的次数。这可能看起来没用,但它确实可以让我们了解哪些函数经常被抢占。Ftrace 还包括允许您让函数图跟踪器忽略任务计划时间的选项。
1 | [tracing]# echo 0 > options/sleep-time |
请注意,sleep-time选项包含“-”,而不是 sleep_time。
禁用功能分析器然后重新启用它会导致数字重置。该列表按平均时间排序,但使用脚本您可以轻松地按任何数字排序。所述trace_stat / function0仅表示存在一个CPU 0 trace_stat /功能#为系统上的每个CPU。所有被追踪和命中的函数都在这个文件中。
1 | [tracing]# cat trace_stat/function0 | wc -l |
未命中的函数未列出。以上显示自我开始分析以来,已命中 2978 个函数。
影响分析的另一个选项是图形时间(再次使用“-”)。默认情况下它是启用的。启用后,函数的时间包括函数内调用的所有函数的时间。从上面示例的输出中可以看出,列出了几个系统调用的平均值最高。禁用时,次数只包括函数本身的执行次数,不包括从函数调用函数的次数:
1 | [tracing]# echo 0 > options/graph-time |
请注意,睡眠时间和图形时间也会影响 function_graph 跟踪器显示的持续时间。
19. 总结
函数跟踪器非常强大,有很多不同的选项。它已经在主线 Linux 中可用,并且希望在大多数发行版中默认启用。它允许您深入了解内核及其功能库,让您很好地了解事情发生的原因。开始使用函数跟踪器打开我们称之为内核的黑匣子。玩得开心!
原文:
https://carlyleliu.github.io/2021/Linux%E5%86%85%E6%A0%B8%E8%B0%83%E8%AF%95%EF%BC%88%E4%B8%80%EF%BC%89ftrace/