
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)

本文约15200字,建议阅读15+分钟 我们对3D目标检测方法进行了性能分析,并总结了多年来的研究趋势,展望了该领域的未来方向。
1摘要
2简述
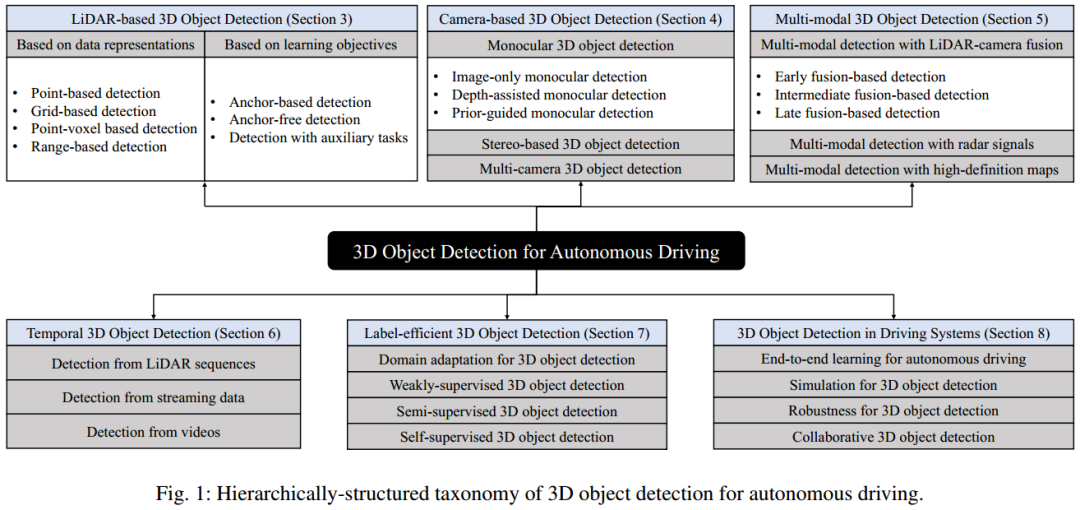
我们从不同的角度全面回顾了3D目标检测方法,包括来自不同传感器输入的检测(基于LiDAR、基于摄像头和多模态)、时间序列检测、标签高效检测、以及3D目标检测在驾驶系统中的应用。 我们从结构和层次上总结了3D目标检测方法,对这些方法进行了系统分析,并为不同类别方法的潜力和挑战提供了有价值的见解。 对3D目标检测方法的综合性能和速度进行分析,确定多年来的研究趋势,并为3D目标检测的未来方向提供深刻的见解。
3背景
3D目标检测是什么?
1、定义
2、传感器输入
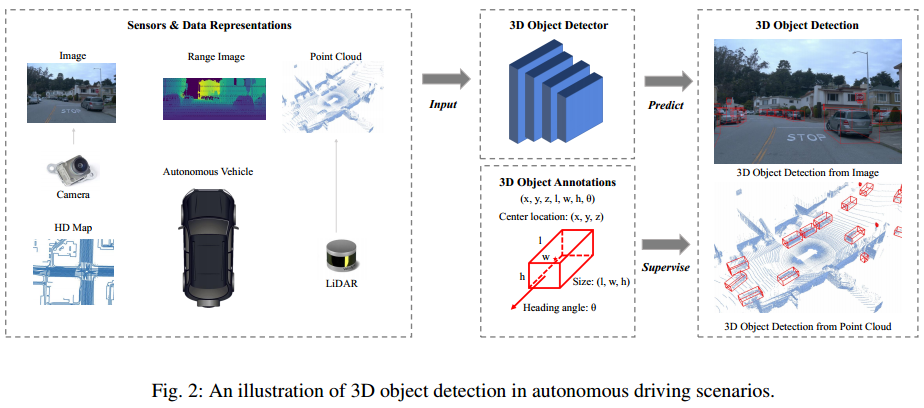
3、与2D目标检测的比较
3D目标检测方法必须处理多样化的数据。点云检测需要新的算子和网络来处理不规则的点数据,而点云和图像的检测需要特殊的融合机制。 3D目标检测方法通常利用不同的投影视图来生成目标预测结果。与从透视图检测目标的2D目标检测方法相反,3D方法必须考虑不同的视图来检测3D目标,例如鸟瞰图、点视图、柱面视图等。 3D目标检测对目标在3D空间的准确定位有很高的要求。分米级的定位误差可能导致对行人和骑自行车的人等小目标的检测失败,而在2D目标检测中,几个像素的定位误差可能仍然保持较高的IoU指标(预测值和真值的IoU)。因此,不论是利用点云还是图像进行3D目标检测,准确的3D几何信息都是必不可少的。
4、与室内3D目标检测对比
自动驾驶场景的检测范围远大于室内场景。驾驶场景中的3D目标检测通常需要预测很大范围内的3D目标,例如Waymo[250]中为150m×150m×6m,而室内3D目标检测通常以房间为单位,而其中[54]大多数单人房间小于10m×10m×3m。那些在室内场景中工作的时间复杂度高的方法在驾驶场景中可能无法表现出好的适应能力。 LiDAR和RGB-D传感器的点云分布不同。在室内场景中,点在扫描表面上分布相对均匀,大多数3D目标在其表面上可以接收到足够数量的点。而在驾驶场景中,大多数点落在LiDAR传感器附近,而那些远离传感器的3D目标仅接收到少量点。因此,驾驶场景中的方法特别需要处理3D目标的各种点云密度,并准确检测那些遥远和稀疏的目标。 驾驶场景中的检测对推理延迟有特殊要求。驾驶场景中的感知必须是实时的,以避免事故。因此,这些方法需要及时高效,否则它们将无法落地。
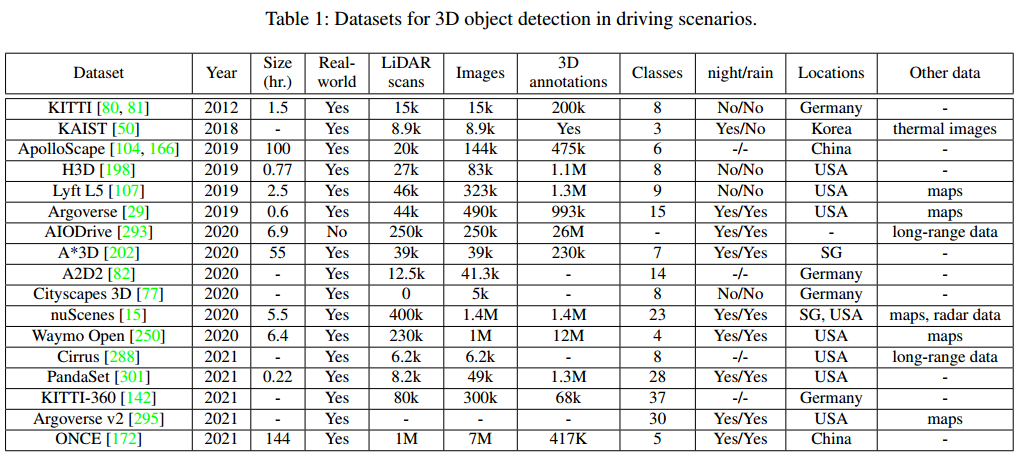
数据集
增大数据规模。 增加数据多样性,不只有白天夜晚,还要包括阴天、雨天、雪天、雾天等。 增加标注类别,除了常用的机动车、行人、非机动车等,还应包括动物,路上的障碍物等。 增加多模态数据,不只有点云和图像数据,还有高精地图、雷达数据、远程激光雷达、热成像数据等。
评价标准
4基于LiDAR的3D目标检测
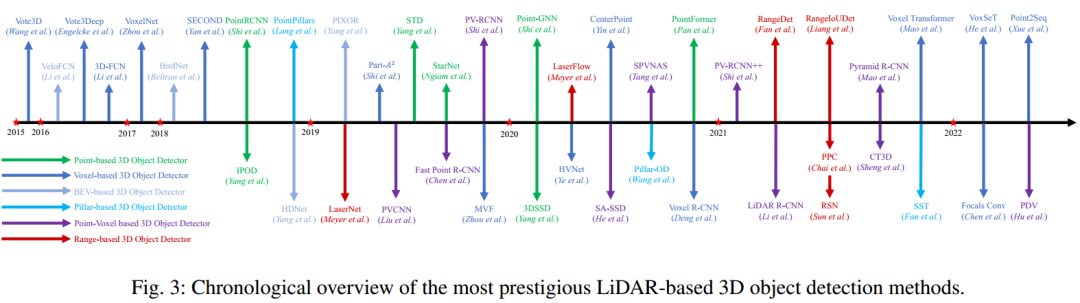
3D目标检测的数据表示
1、基于点的3D目标检测
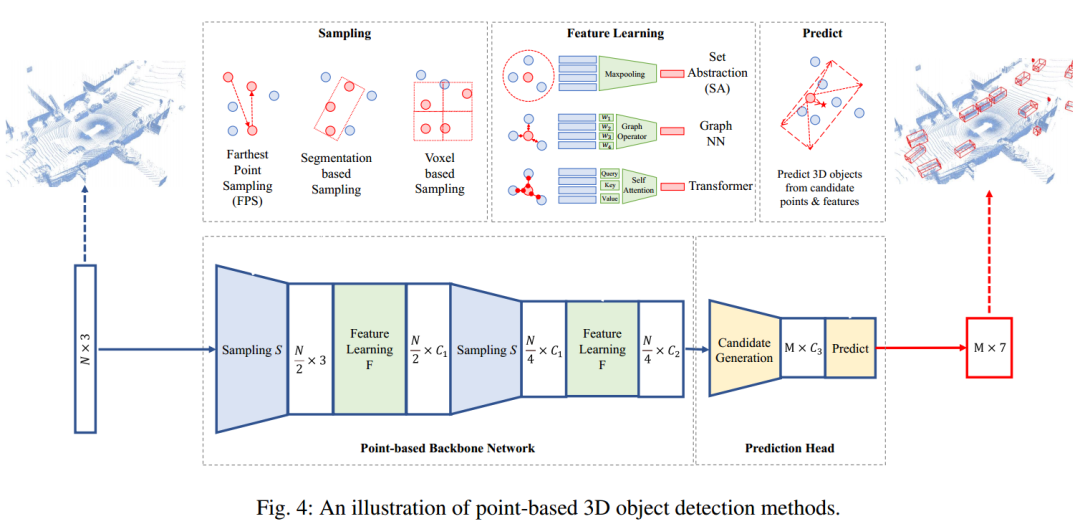
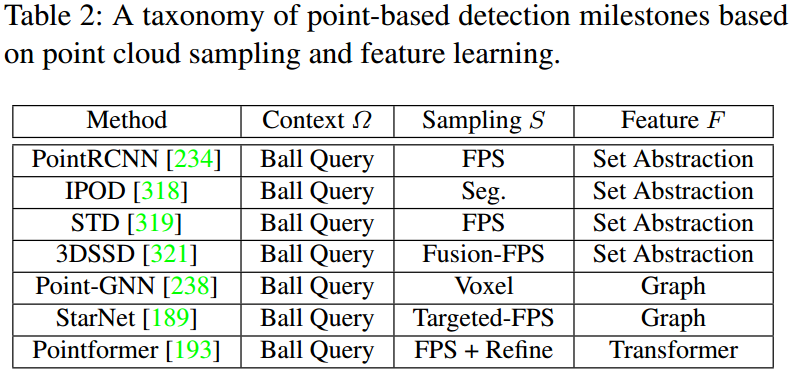
2、基于网格的3D目标检测
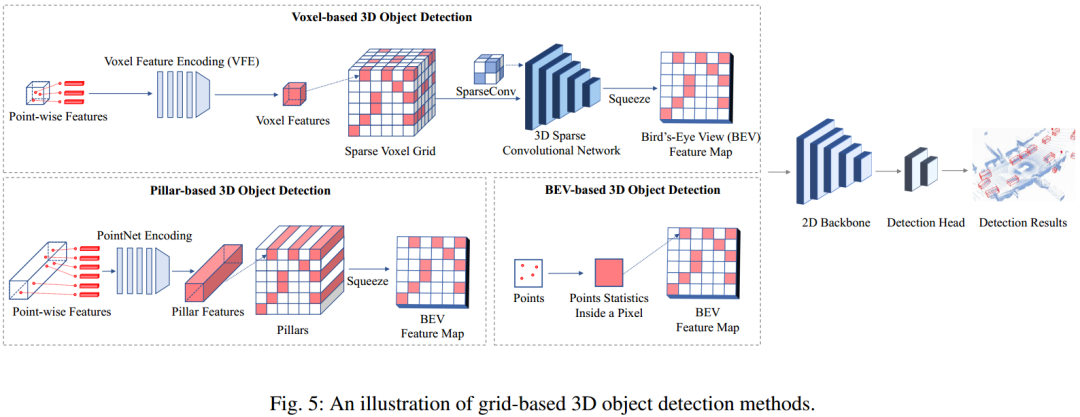
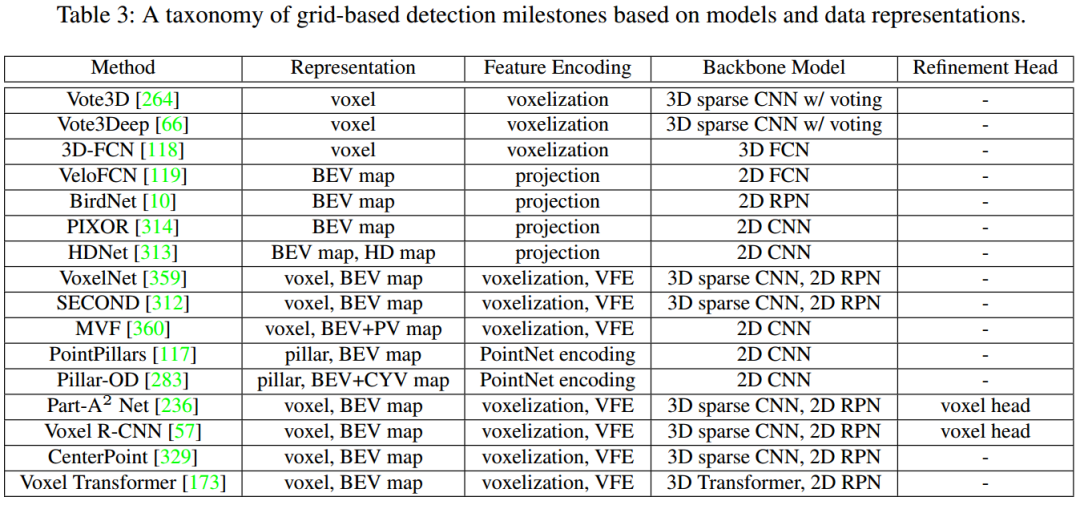
多视图体素。一些方法从不同的视角提出了一种动态体素化和融合方案,例如从鸟瞰图和透视图[360],从圆柱形和球形视图[34],从深度视图[59]等。 多尺度体素。一些论文生成不同尺度的体素[323]或使用可重构体素。
3、基于Point-Voxel的3D目标检测方法
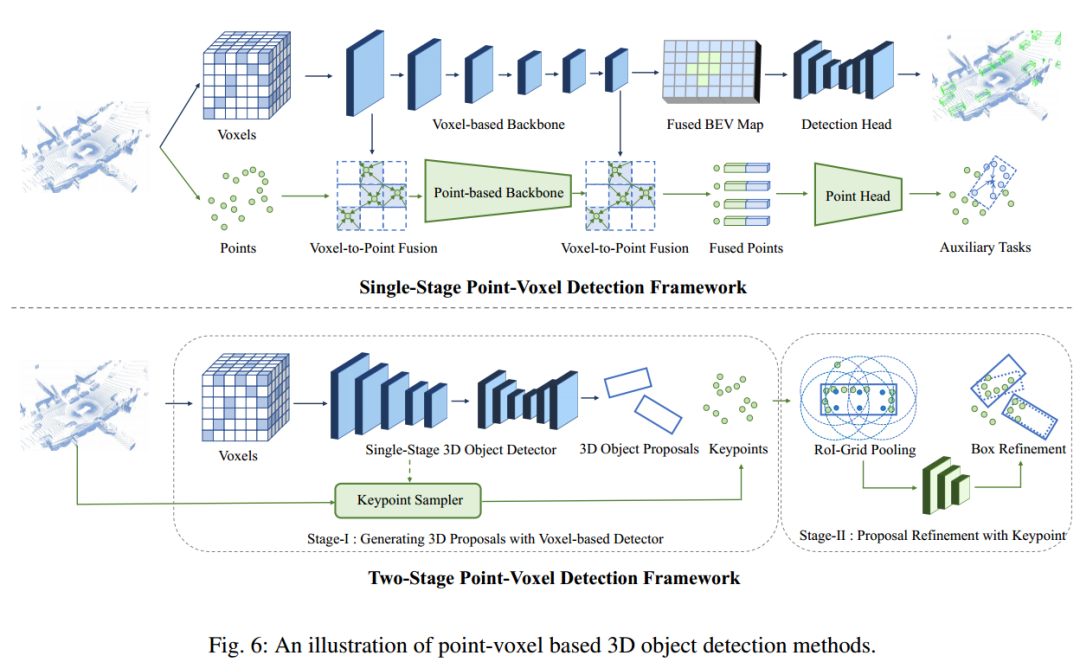
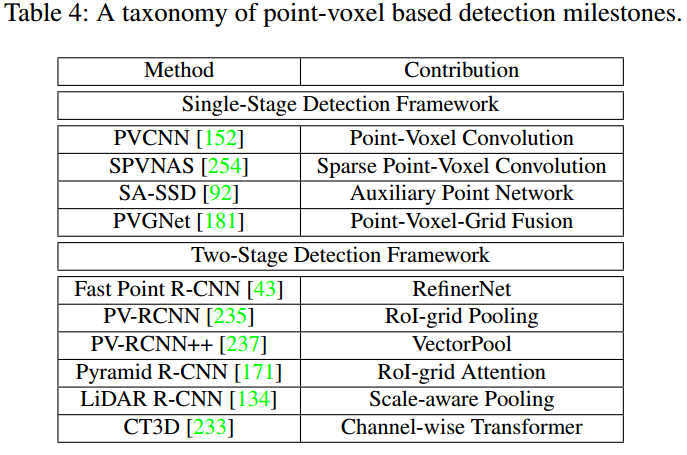
4、基于Range的3D目标检测
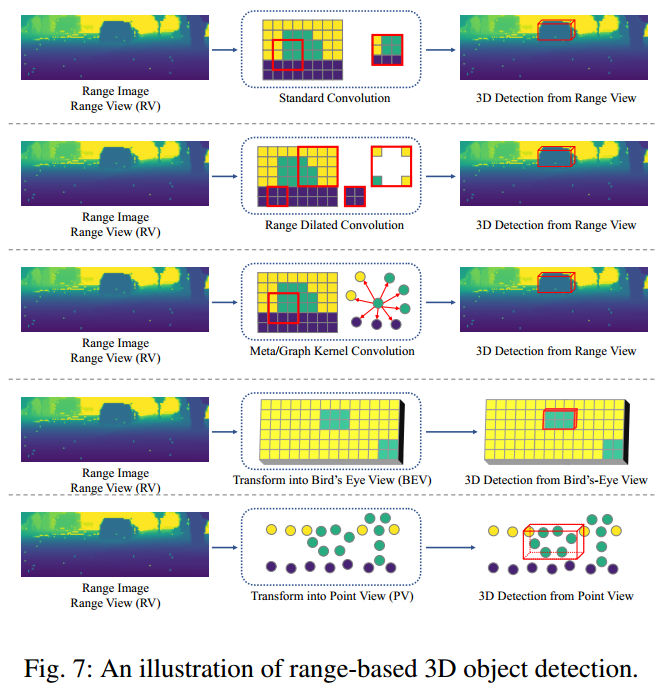
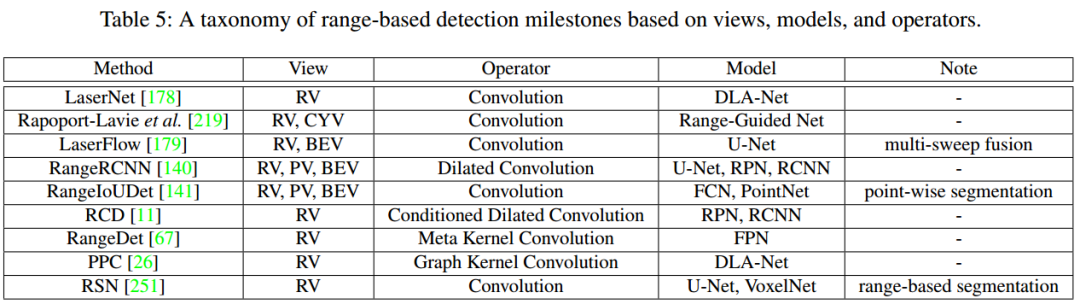
3D目标检测的学习目标
1、Anchor-based方法
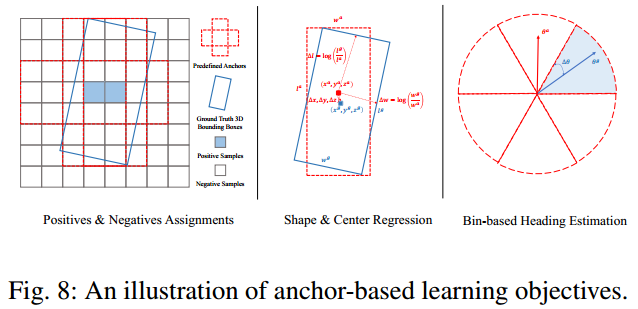
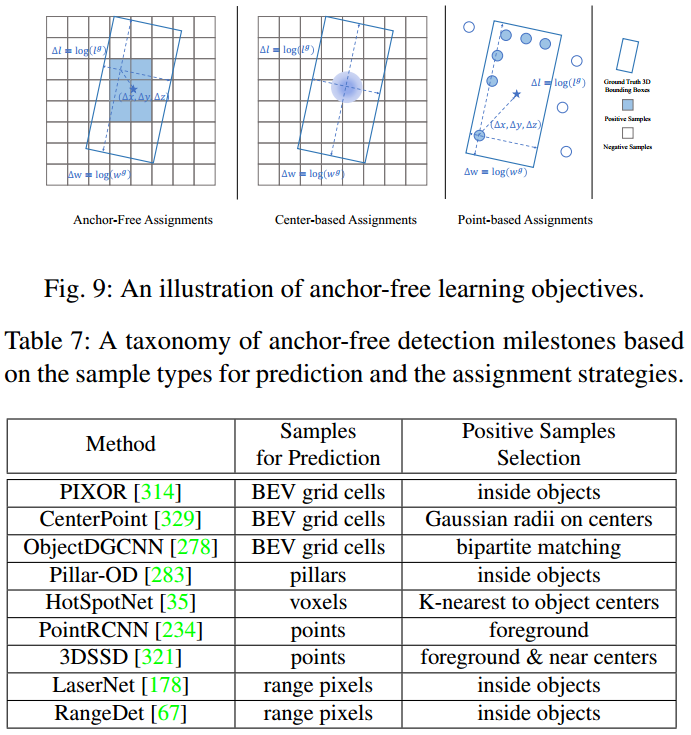
2、Anchor-free方法
3、利用辅助任务的3D目标检测
5基于相机的3D目标检测
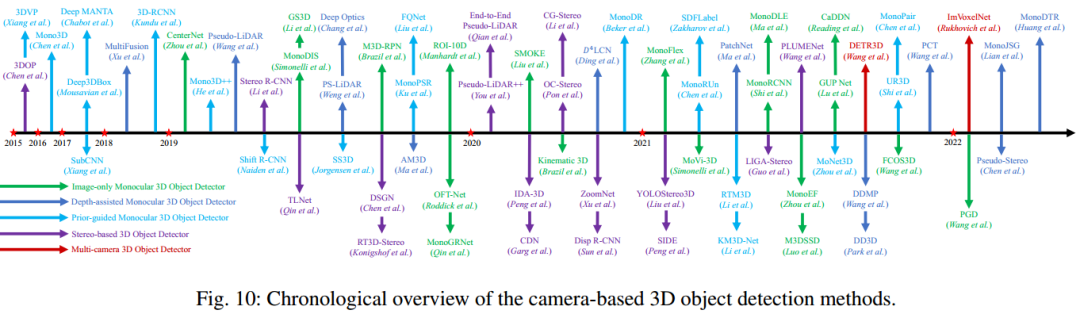
单目3D目标检测
1、纯图像单目3D检测

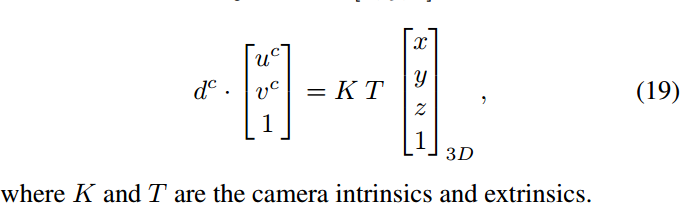
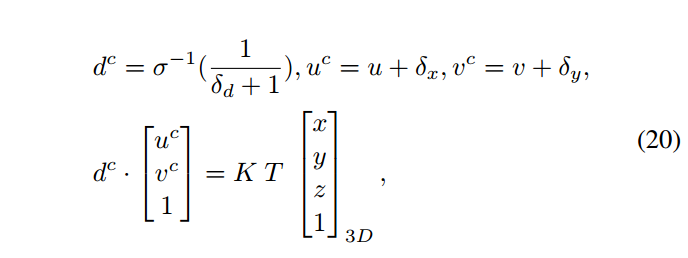
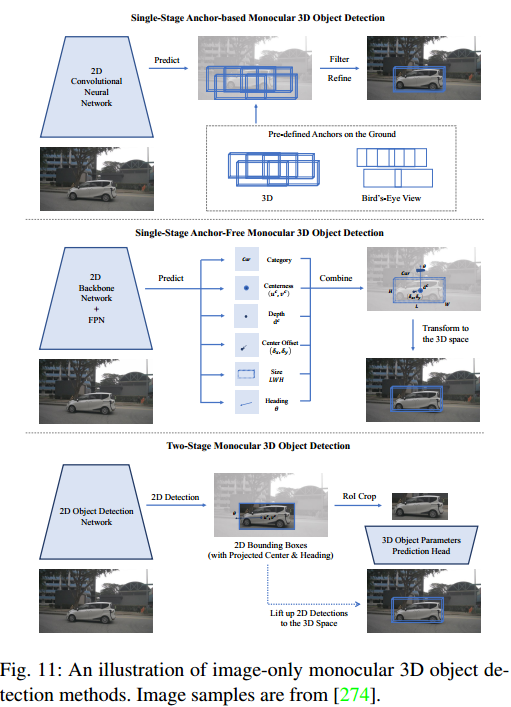
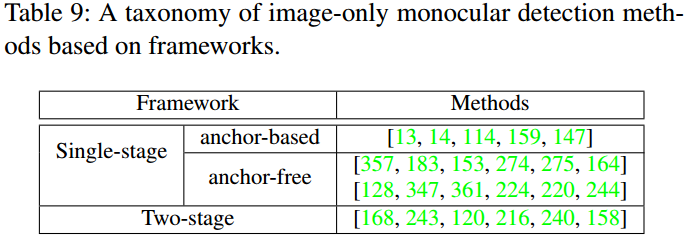
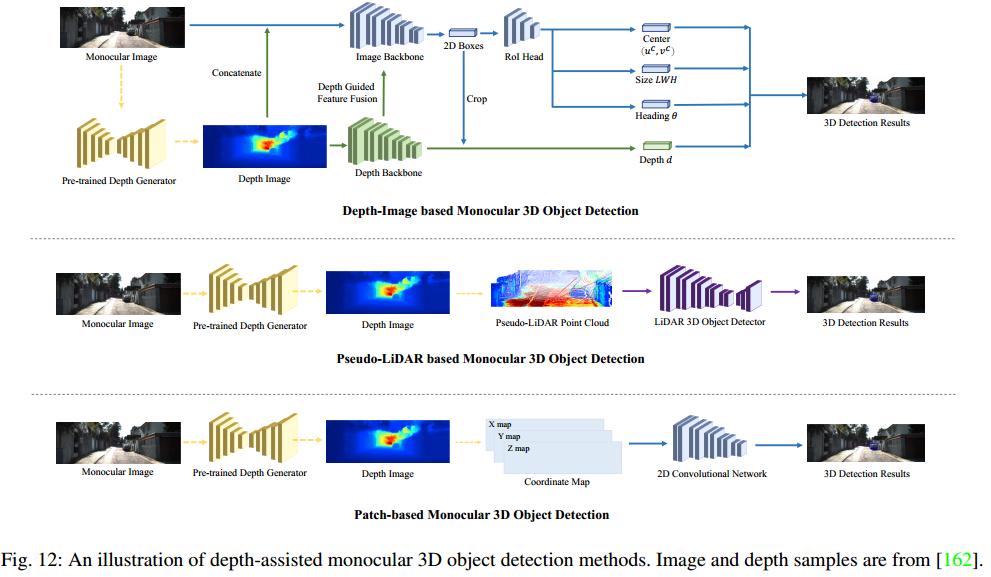
2、深度辅助的单目3D检测
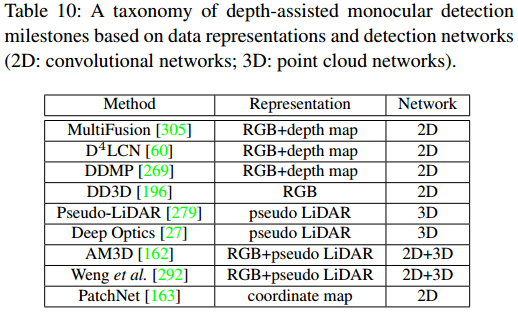
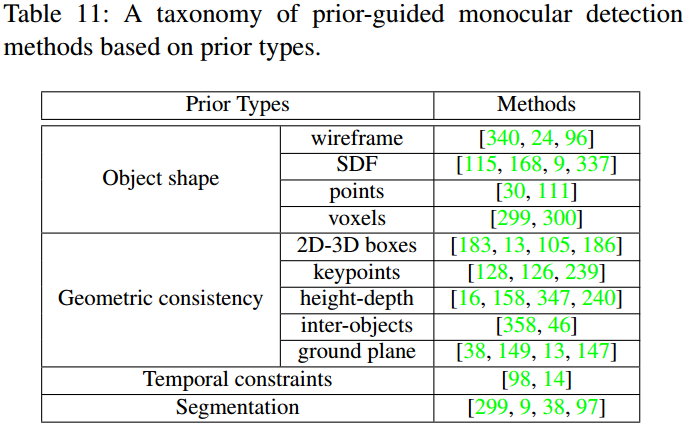
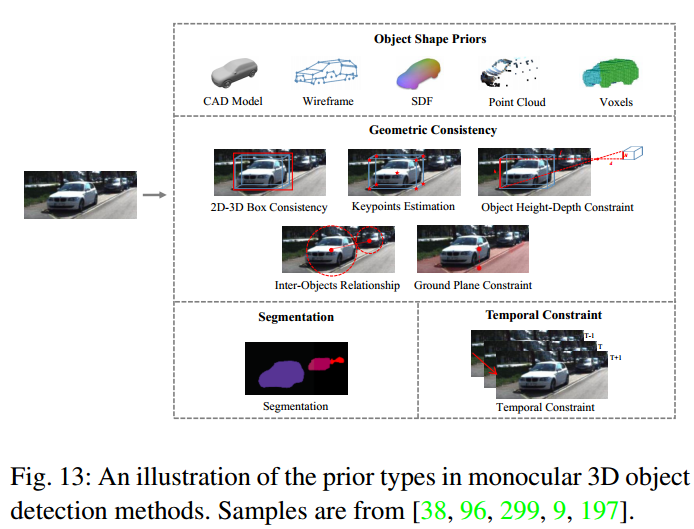
3、先验引导的单目3D检测
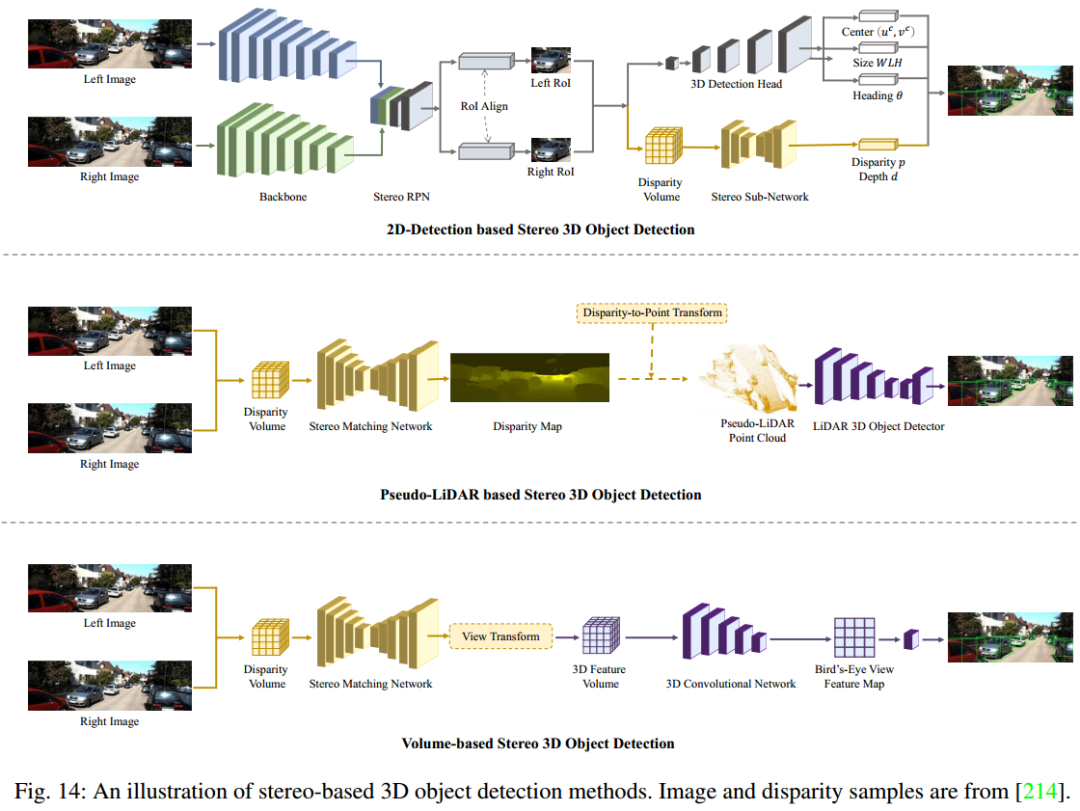
4、基于双目的3D目标检测

5、基于多相机的3D目标检测
6基于多模态的3D目标检测
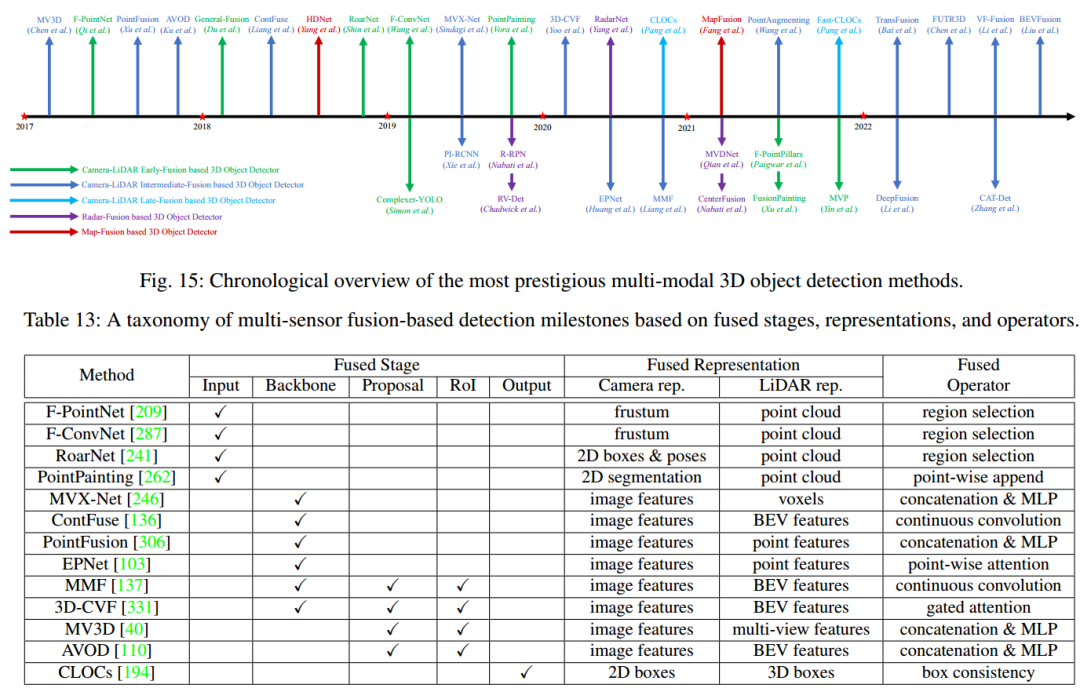
基于LiDAR-相机融合的多模态检测
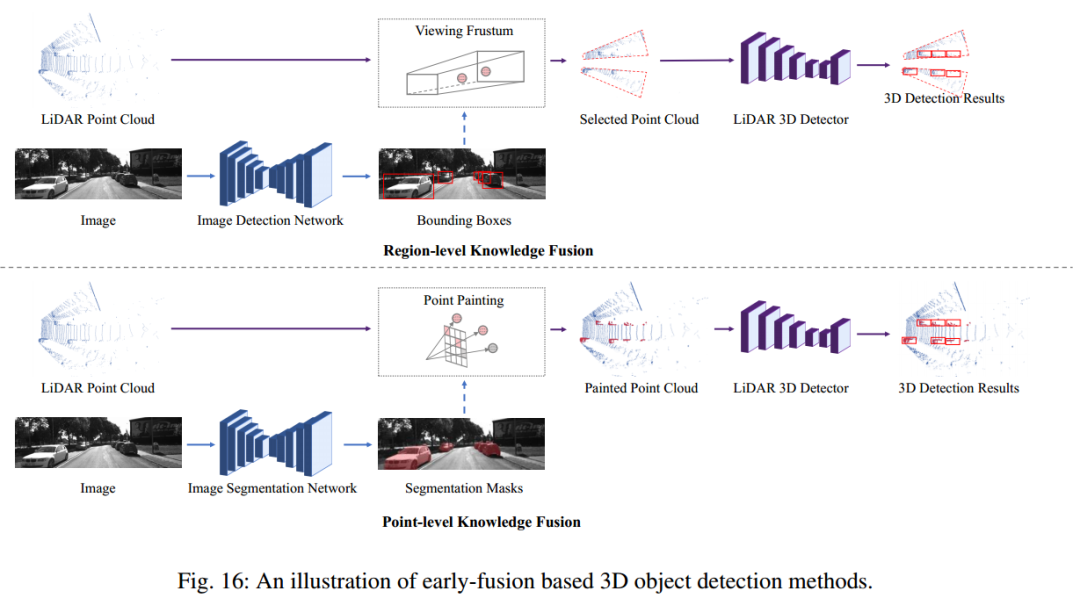
1、前融合方法
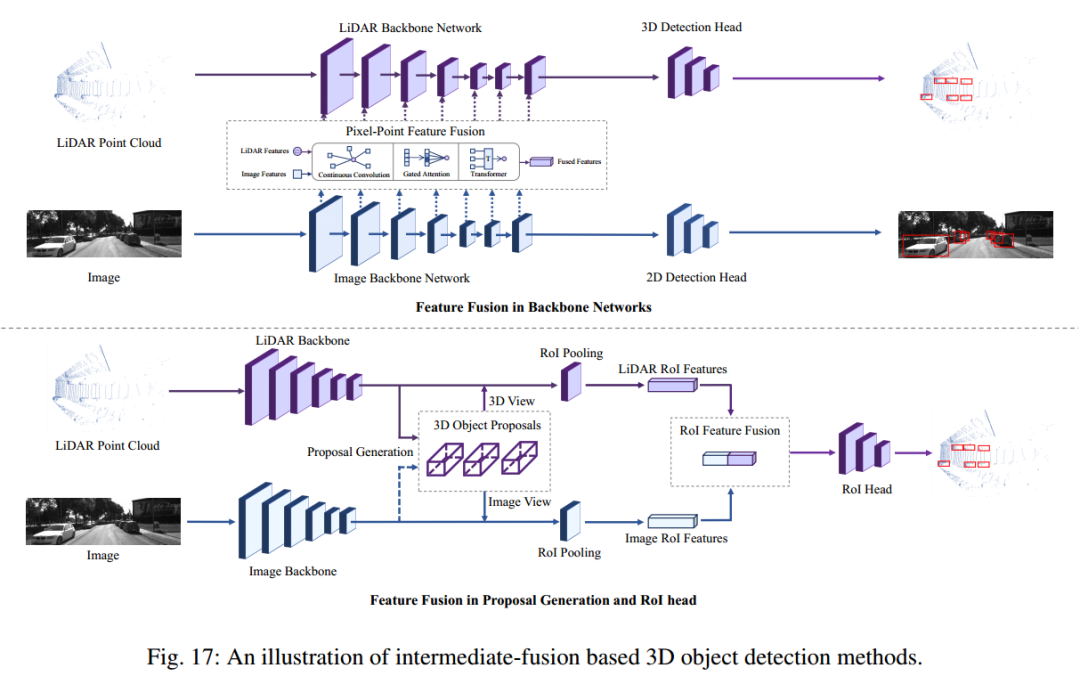
2、中融合方法
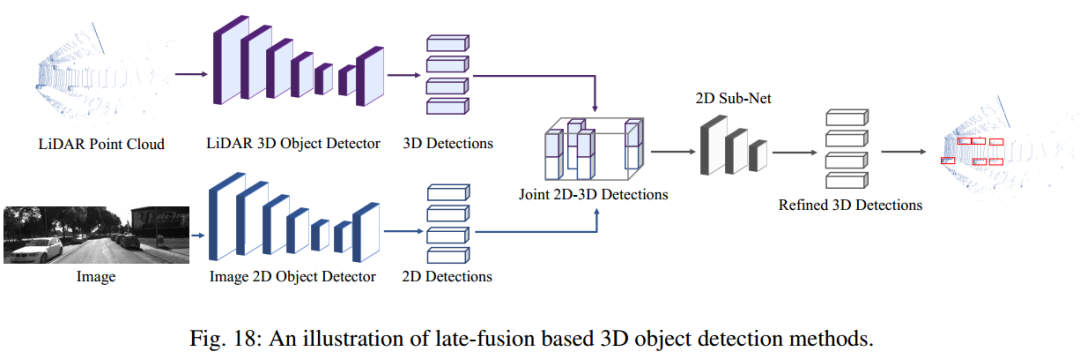
3、后融合方法
基于雷达信号的多模态检测
结合高精地图的多模态检测
7时序3D目标检测
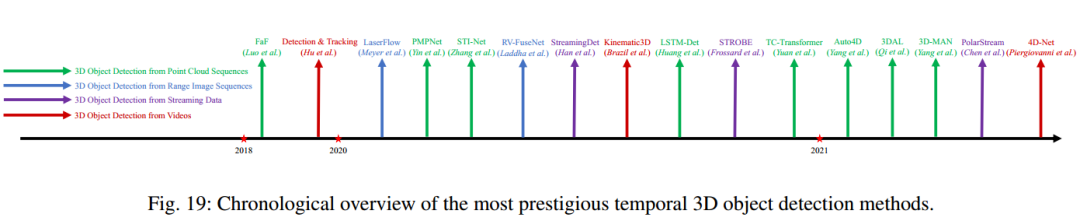
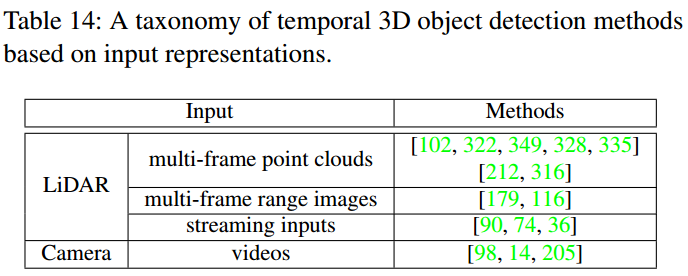
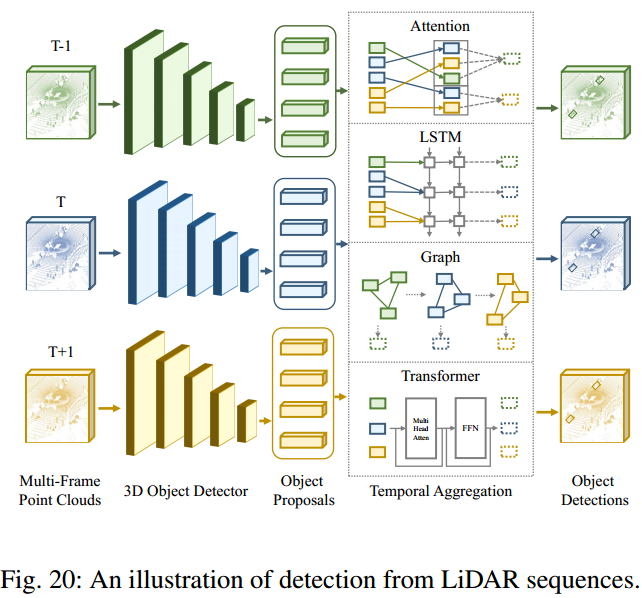
激光雷达序列
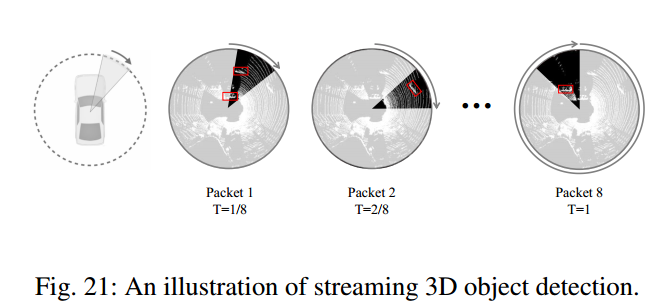
利用流数据进行3D目标检测
利用视频进行3D目标检测
8标签高效的3D目标检测
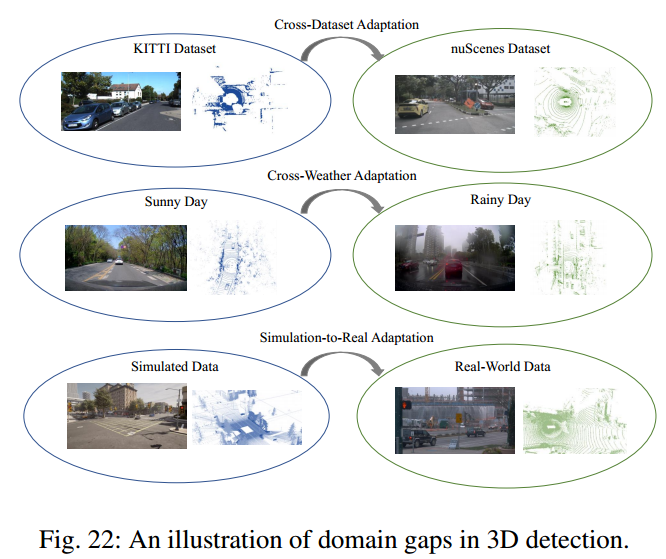
3D目标检测中的域自适应

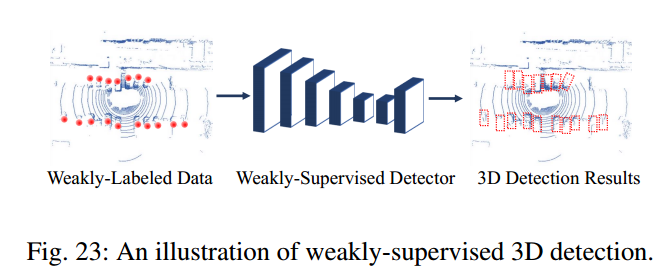
弱监督3D目标检测
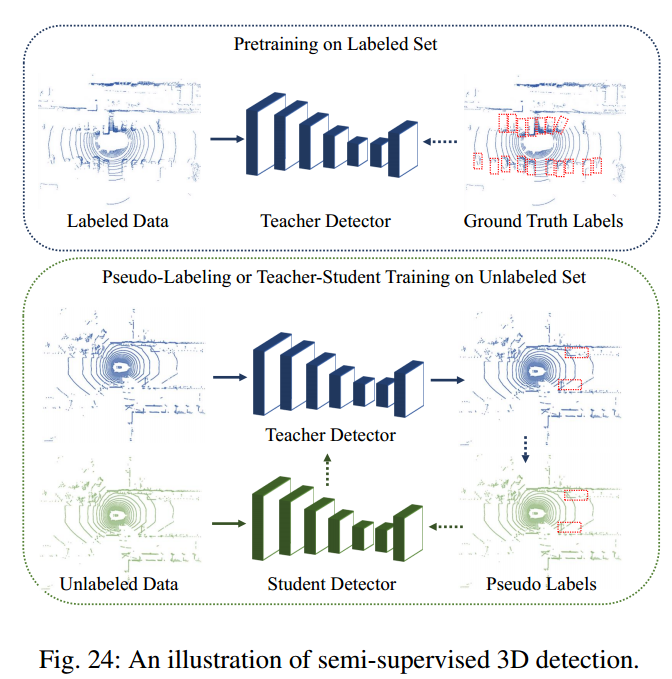
半监督3D目标检测
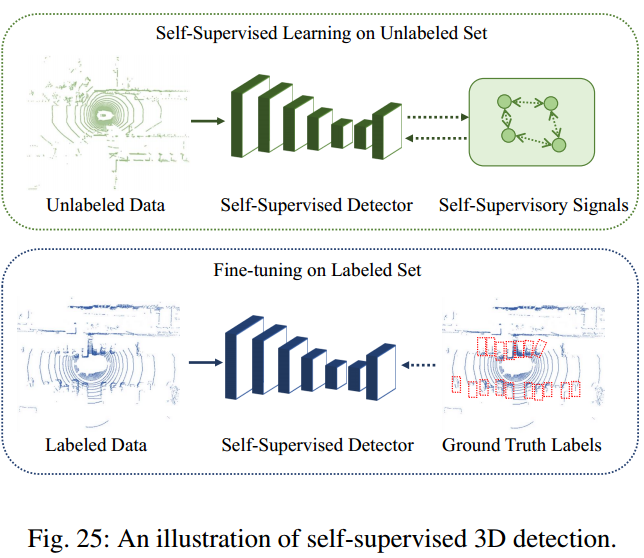
自监督3D目标检测
9自动驾驶系统中的3D目标检测
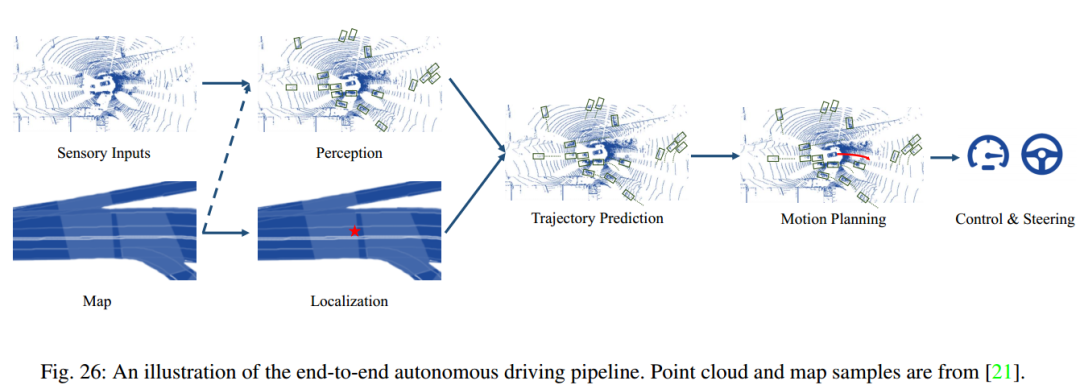
自动驾驶中的端到端学习
3D目标检测仿真
3D目标检测的鲁棒性
协同3D目标检测
10分析和展望
研究趋势
未来展望
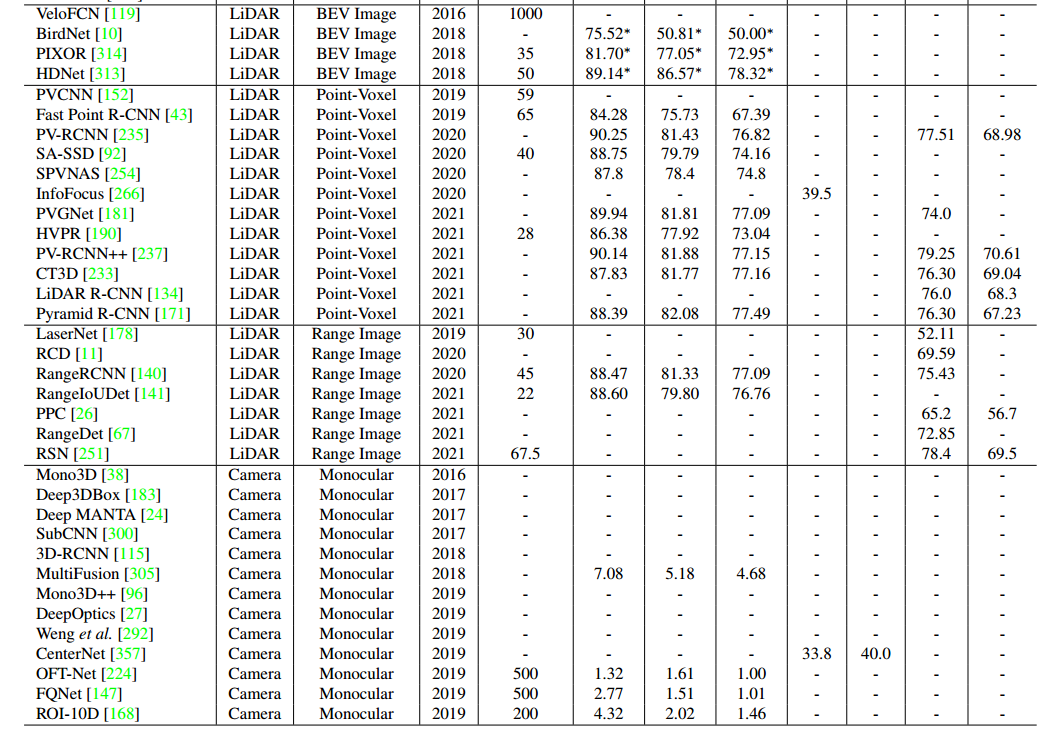
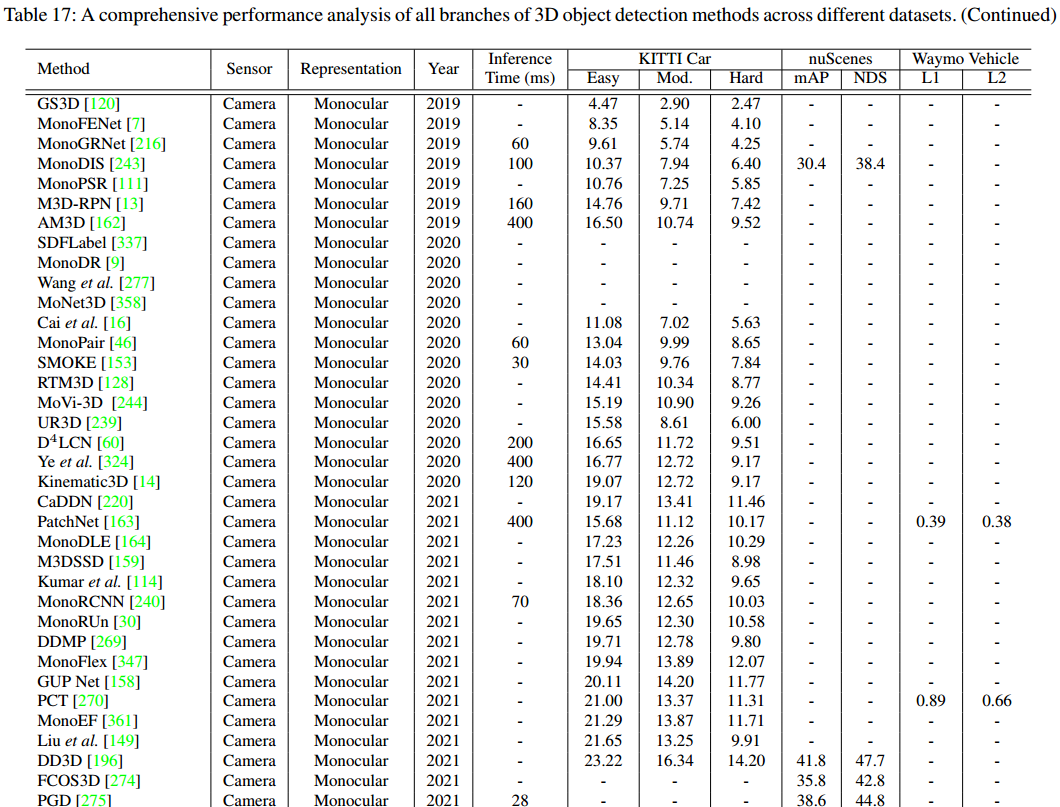
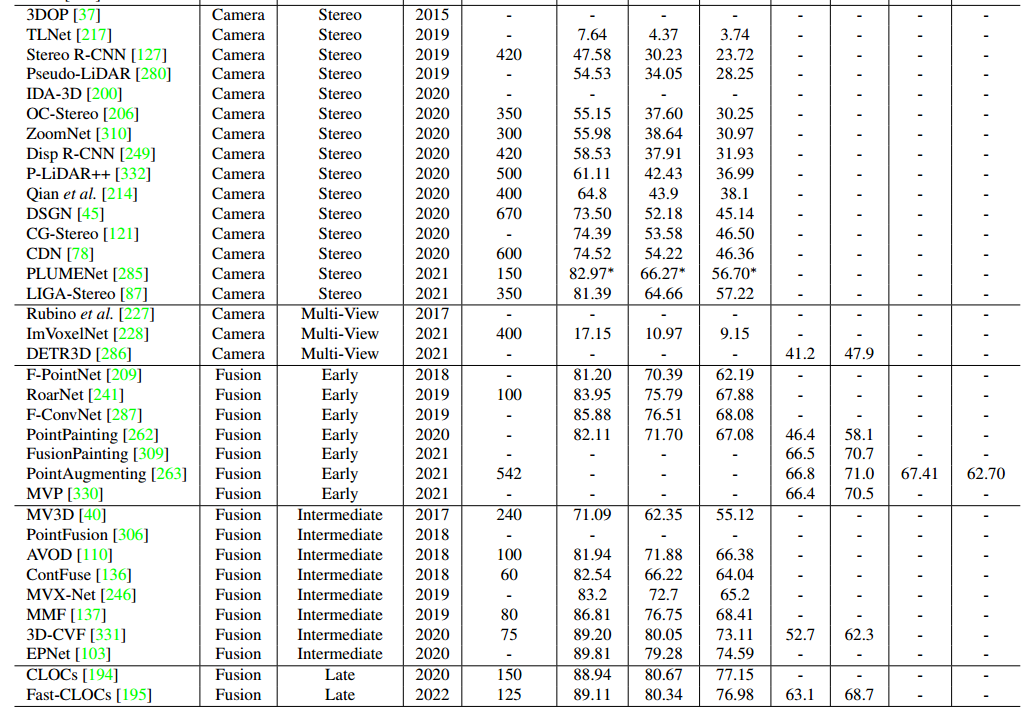
11总结
12参考文献
[1] Mao, J., Shi, S., Wang, X., & Li, H. (2022). 3D Object Detection for Autonomous Driving: A Review and New Outlooks.ArXiv, abs/2206.09474.
编辑:于腾凯
校对:林亦霖
评论