
使用OpenCV和TesseractOCR进行车牌检测
共 6761字,需浏览 14分钟
·
2021-04-19 10:20
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


1)目的和简介
2)前言
3)使用OpenCV和Haar级联进行车牌检测
4)使用TesseractOCR识别和提取车牌号
当我们谈论AI时,计算机视觉绝对是人们想到的最重要的应用之一。我们一直对它着迷,因为它与人的视线有关,可以说是人的感官中最重要的器官。
我们接触过大量项目涉及的人脸和/或身体的项目。因此,我们决定改为在汽车牌照上开展此项目。我们从事此该项目的另一个原因是,我们在检测到车牌后,准备使用光学字符识别(OCR)来识别,提取和显示检测到的车牌号。
我们将使用Python 来构建我们的项目,并且利用两个开源软件的来实现检测目的,即OpenCV和TesseractOCR。在继续进行操作之前,请按以下步骤在计算机上完全安装这些工具。
(1)安装OpenCV
OpenCV(开源计算机视觉库)是一个开源计算机视觉和机器学习软件库。它主要专注于图像处理,视频捕获和分析,包括人脸检测和物体检测等功能,并有助于为计算机视觉应用程序提供通用的基础结构。
(2)Haar CascadeXML文件
除了安装OpenCV库外,要检索的另一重要内容是Haar Cascade XML文件。这是一种基于机器学习的方法(涉及AdaBoost),其中从许多正负图像中训练级联函数。它利用积分图像(或总面积表)的概念有效地提取特征(例如,边缘,线条)的数值,这胜过了在整个图像的多个区域中减去像素总和的默认计算量大的方式。
另外,它使用“级联分类器”。这意味着不是一次就为图像中的许多特征应用数百个分类器(这是非常低效的),而是一对一地应用分类器。
以人脸图像为例。如果“眼睛”功能的第一个分类器发生故障(即无法检测到图像中的人眼),则该算法不会打扰应用后续的分类器(例如,针对鼻子,针对嘴等)。而是停止并声明未检测到脸部。
另一方面,如果检测到第一个“眼睛”特征,则算法将应用特征分类的第二阶段并继续进行分类过程。最后,如果图像通过所有分类阶段,则可以声明存在面部区域。
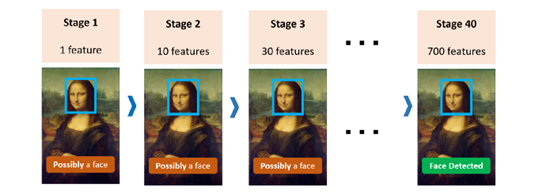
实际上,OpenCV附带了各种Haar级联的经过预先训练的XML文件,其中每个XML文件都包含功能集。
(3)TesseractOCR
TesseractOCR是一种开源光学字符识别(OCR)引擎。它被公认为是最流行,最准确的开源OCR引擎之一。有趣的是,该引擎实际上最初是由惠普开发的专有软件,但后来于2005年开源,并且此后的开发一直由Google赞助。以下是安装TesseractOCR(适用于Windows)的说明:
使用Windows安装程序安装TesseractOCR应用程序,该程序可从以下网站获得:https : //github.com/UB-Mannheim/tesseract/wiki。在完成此项目时,我们下载了2020年11月27日(64位)版本(tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe)
运行下载的安装程序,并记下该应用程序的安装位置。对我来说,我将其安装在folder内D:\Program Files\Tesseract-OCR。稍后我们将使用此文件夹路径,这很重要,因为我们需要直接指向该文件夹内的tesseract.exe。
pip install pytesseract使用以下命令在您的环境中安装TesseractOCR的Python版本(即PyTesseract):
# Import dependenciesimport numpy as npimport matplotlib.pyplot as plt%matplotlib inlineimport cv2 # This is the OpenCV Pythonlibraryimport pytesseract # This is theTesseractOCR Python library# Set Tesseract CMD path to the location oftesseract.exe filepytesseract.pytesseract.tesseract_cmd =r'C:\Program Files\Tesseract-OCR\tesseract.exe'
首先,我们导入要使用的汽车图像。由于默认情况下OpenCV将图像导入为BGR(蓝绿色红色)格式,cv2.cvtColor因此在要求matplotlib显示图像之前,我们需要运行将其切换为RGB格式。

现在使用OpenCV的CascadeClassifier函数为车牌引入Haar Cascade功能集(XML文件)了。
# Import Haar Cascade XML file for Russiancar plate numberscarplate_haar_cascade = cv2.CascadeClassifier('./haar_cascades/haarcascade_russian_plate_number.xml')
接下来,我们使用detectMultiScaleCascadeClassifier的方法来运行检测。
# Setup function to detect car platedef carplate_detect(image):carplate_overlay = image.copy()carplate_rects = carplate_haar_cascade.detectMultiScale(carplate_overlay,scaleFactor=1.1,minNeighbors=3)for x,y,w,h in carplate_rects:cv2.rectangle(carplate_overlay, (x,y), (x+w,y+h), (255,0,0), 5)return carplate_overlay
我们简要地谈谈OpenCVdetectMultiScale方法。该方法允许我们检测输入图像中不同大小的对象,并返回检测对象的矩形边界列表。对于每个矩形,将返回4个值,它们分别对应于以下值:
矩形(x)左下角的x坐标
矩形(y)的左下角的y坐标
矩形宽度(w)
矩形高度(h)
该函数涉及的关键参数detectMultiScale是scaleFactor和minNeighbors。
scaleFactor指定在每个图像比例尺(作为比例尺金字塔的一部分,该比例尺是图像的多比例尺表示)上图像尺寸减小多少。本质上,当训练对象检测模型时,它们被训练为检测固定大小的对象(在我们的情况下为车牌),并且可能会错过比预期更大或更小的车牌。作为比例金字塔的一部分,图像会被调整几次大小,以期使车牌最终成为“可检测”的尺寸。我使用默认的比例因子1.1,这意味着OpenCV会将图像缩小10%,以尝试更好地匹配车牌。

我们可以看到我们的功能奏效了!已成功检测到汽车牌照,并以红色矩形为边界。我们的下一步是将重点放在车牌本身上,并努力使用OCR功能提取车牌的编号和文字。
(1)提取车牌并放大图像
为了确保OCR功能的成功,我们需要执行一系列图像处理步骤。让我们从选出的汽车牌照图像开始。为此,我们设置了类似于我们先前在车板检测中所做的功能,只是这次我们将提取感兴趣区域(车板)并将其作为新图像返回。
# Create function to retrieve only the carplate region itselfdef carplate_extract(image):carplate_rects = carplate_haar_cascade.detectMultiScale(image,scaleFactor=1.1,minNeighbors=5)for x,y,w,h in carplate_rects:carplate_img = image[y+15:y+h-10 ,x+15:x+w-20] # Adjusted to extractspecific region of interest i.e. car license platereturn carplate_img
此外,resize由于它只是原始输入图像的一小部分,因此我们也想扩大我们的汽车牌照(使用OpenCV的方法)。
# Enlarge image for further processinglater ondef enlarge_img(image, scale_percent):width = int(image.shape[1] * scale_percent / 100)height = int(image.shape[0] * scale_percent / 100)dim = (width, height)resized_image = cv2.resize(image, dim, interpolation = cv2.INTER_AREA)return resized_image
运行这两个功能将使我们感兴趣的区域就是汽车牌照本身(称为carplate_extract_img)。
# Display extracted car license plate imagecarplate_extract_img =carplate_extract(carplate_img_rgb)carplate_extract_img =enlarge_img(carplate_extract_img, 150)plt.imshow(carplate_extract_img);

(2)转换为灰度
下一步是将图像从RGB颜色转换为灰度。这样做的目的是减少图像中的颜色数量,这可能会干扰OCR检测。而且我们要关注图像的重要边缘和形状,将其转换为灰度会使结果更为准确。
# Convert image to grayscalecarplate_extract_img_gray =cv2.cvtColor(carplate_extract_img, cv2.COLOR_RGB2GRAY)plt.axis('off')plt.imshow(carplate_extract_img_gray, cmap= 'gray');

iii)平滑(又称模糊或去噪)
接下来,我们对图像进行平滑处理。平滑技术有助于消除噪点,并使应用程序专注于图像的一般细节。从本质上讲,这就是我们所说的“降噪”步骤,它使图像中的文字字符更加清晰和可识别。
我们使用中值模糊进行了平滑处理(使用cv2.medianBlur),该值可计算内核窗口下所有像素的中值,而中心像素将替换为该中值。对于这个项目,我们发现中值模糊特别有效(肯定比高斯模糊更有效),因此这里展示了中值模糊。
# Apply median blurcarplate_extract_img_gray_blur = cv2.medianBlur(carplate_extract_img_gray,3)# kernel size 3plt.axis('off')plt.imshow(carplate_extract_img_gray_blur,cmap = 'gray');

视觉上的差异可能比较小,但是要仔细比较两个图像,我们会注意到字符的边缘稍微更平滑且锯齿更少。经过这些转换后,我们的图像现在可以用于OCR应用了。对于其他图像,如果需要更高的平滑度,则可以始终将内核大小从此处使用的大小增加。让我们将图像传递到PyTesseractimage_to_string函数中:
# Display the text extracted from the carplateprint(pytesseract.image_to_string(carplate_extract_img_gray_blur, config =f'--psm 8 --oem 3 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'))

“T111TT97”的印刷文字与我们车牌图像上的字符匹配!
有关上述PyTesseractimage_to_string 函数的一些其他详细信息。该config参数包含其他几个参数(也称为flags):
tessedit_char_whitelist帮助将TesseractOCR函数限制为一组预定义(白名单)字符。由于我们知道车牌文本的范围是0–9和AZ,因此可以这样指定。
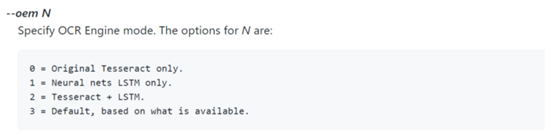
--oem是指Ø CR é ngine中号ODE(OEM),并取其发动机模式,我们想要的值对应。在这种情况下,我基于可用的默认引擎(模式号3(--oem 3))使用了引擎。以下是我们可以使用的各种OCR引擎模式的详细信息:
--psm指的是P中的egmentation的中号(PSM),这使我们能够获得TesseractOCR运行仅布局分析的一个子集,并假设图像的特定形式。各种受支持的选项的详细信息如下所示:
由于我们的驾照图片将被视为一个单词(即PSM选项号8),因此我使用--psm 8了config参数内的值。我们也尝试了所有可能的PSM选项:
# Testing all PSM valuesfor i in range(3,14):print(f'PSM: {i}')print(pytesseract.image_to_string(carplate_extract_img_gray_blur, config =f'--psm {i} --oem 3 -ctessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'))
在本篇文章中,我们介绍了如何在Python中设置OpenCV和TesseractOCR(以PyTesseract的形式),以及如何利用其强大的内置功能来检测车牌并从中提取文本、车牌号。
最重要的是,我们还讨论了一些理论概念,例如Haar级联,多尺度检测参数,用于优化识别的图像处理以及TesseractOCR的页面分割模式(PSM)。
该项目是大规模(和更高级)计算机视觉项目的垫脚石,例如从大量图像中批量提取车牌文本,甚至将这些概念应用到视频文件或实时供稿中。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~