
这招可以让Pandas 数据帧处理速度提高400倍!
点击关注"Python学习与数据挖掘"
更多超级干货第一时间推送给你哦!!!
数据处理是数据科学模型开发流程的重要组成部分之一。数据科学家需要花费80%的时间准备数据集以使其适合建模。有时,对大型数据集执行数据整理和探索变得繁琐的工作,只有等待很长时间才能完成计算,或者转移到某些并行处理。
Pandas 是拥有大量API的著名 Python 库之一,但是在可伸缩性方面却失败了。对于大型数据集,迭代整个循环有时会花费很多时间,有时甚至是数小时,甚至对于小型数据集,使用标准循环对数据框架进行迭代也非常耗时。
在本文中,我们将讨论在大型数据集上加快迭代过程的技术或技巧。
1、Pandas 内置函数:iterrows()
iterrows() 是内置的 Pandas 库函数,它返回一系列的每个实例或行。它将数据帧作为一对索引和列特征作为Series进行迭代。
我使用了一个具有1000万条记录和5列的数据集。我们在数据集中使用字符串类型的特征"name",必须将其删除以删除空格。
temp=[]
for i,row in df.iterrows():
name_new = row['name'].strip()
temp.append(name_new)
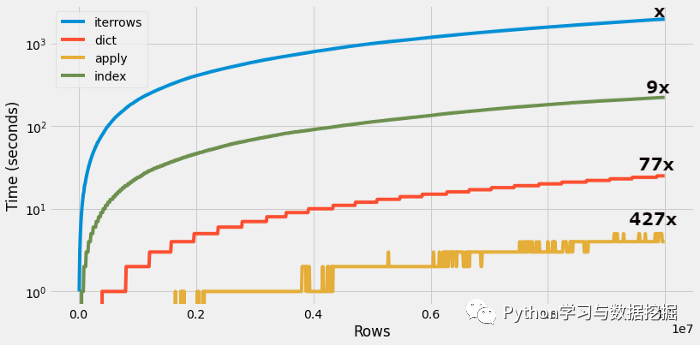
该代码段执行了将近「1967秒」。现在,让我们找出其他技术来遍历数据帧并比较其时间复杂度。
按索引迭代
数据框是具有行和列的Pandas对象。数据帧的行和列都已建立索引,并且可以遍历索引以遍历行。
temp=[]
for idx in range(0,df.shape[0],1):
name_new = df['name'].iloc[idx].strip()
temp.append(name_new)
遍历数据帧并执行剥离操作花了将近「223秒」(比iterrows函数快9倍)。
使用 to_dict()
只需将Pandas数据框转换为字典,即可遍历数据框并以闪电般的速度执行操作。你可以在Pandas中使用.to_dict()函数将数据框转换为字典。现在,与iterrows()函数相比,在字典上进行迭代相对非常快。
df_dict = df.to_dict('records')
temp=[]
for row in df_dict:
name_new = row['name'].strip()
temp.append(name_new)
对数据集的字典格式进行处理后耗时「25.5秒」,这比iterrows()函数快77倍。
使用 apply()
apply() 是内置的Pandas函数,它允许传递一个函数并将其应用于Pandas系列的每个值。apply()函数本身并不快,但是它对Pandas库有很大的改进,因为该函数有助于根据所需条件隔离数据。
temp = df['name'].apply(lambda x: x.strip())
apply() 函数执行耗时「4.60秒」,比iterrows() 函数快427倍。
结论
在本文中,我们讨论了在Pandas数据帧上进行优化的几种技术,并比较了它们的时间复杂度。建议在非常特殊的情况下使用iterrows()函数。
可以轻松地从使用iterrows()或索引方法转变为基于字典的迭代技术,该技术将工作流程的速度提高了77倍。Apply函数的速度提高了约400倍,但用途有限,人们需要对代码进行大量更改才能转换为这种方法。

大家好,最后给大家免费分享 Python 三件套:《ThinkPython》、《简明Python教程》、《Python进阶》的PDF电子版。如果你是刚入门的小白,不用想了,这是最好的学习教材。
现在免费分享出来,有需要的读者可以下载学习,在下面的公众号里回复关键字:三件套,就行。
领取方式:
长按下方扫码,关注后发消息 [三件套]
感谢你的分享,点赞,在看三连 