在本文中,想展示如何使用仅编码器模型的预训练权重来为我们的微调提供一个良好的开始。
BERT是一个著名的、强大的预先训练的“编码器”模型。让我们看看如何使用它作为“解码器”来形成编码器-解码器架构。Transformer 架构由两个主要构建块组成——编码器和解码器——我们将它们堆叠在一起形成一个 seq2seq 模型。从头开始训练基于Transformer 的模型通常很困难,因为它需要大型数据集和高 GPU 内存。我们可以使用许多具有不同目标的预训练模型。
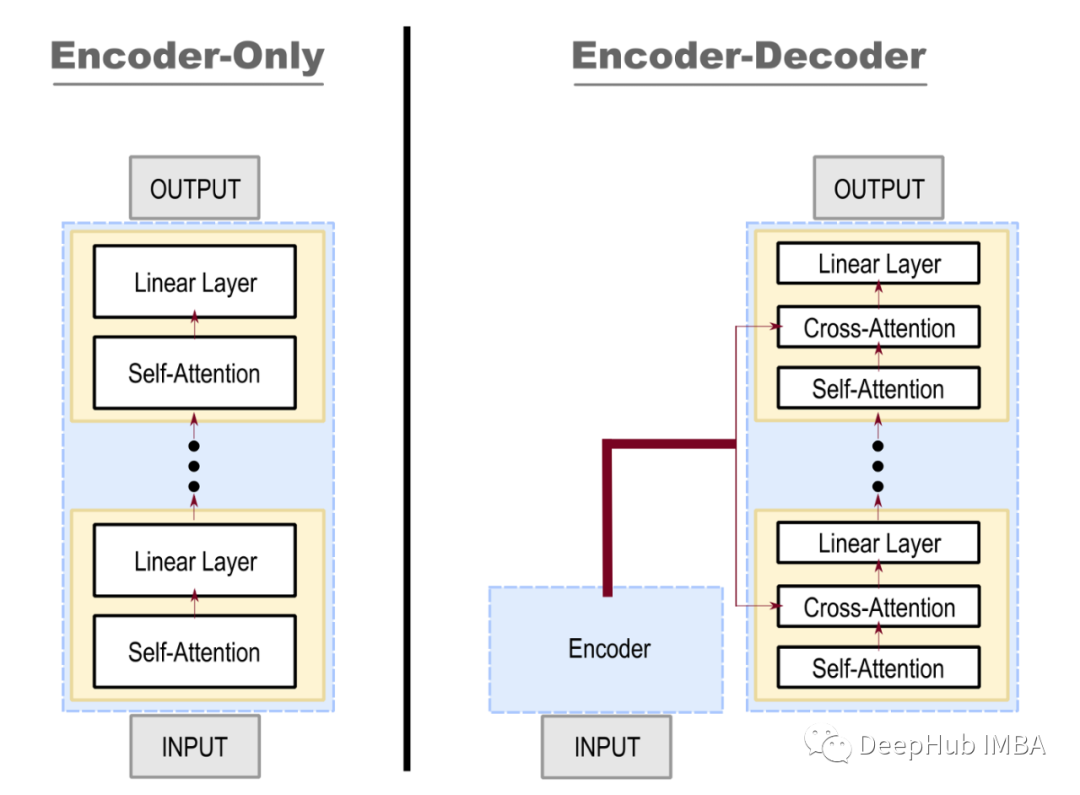
首先,编码器模型(例如,BERT、RoBERTa、FNet 等)学习如何从他们阅读的文本中创建固定大小的特征表示。这种表示可用于训练网络进行分类、翻译、摘要等。具有生成能力的基于解码器的模型(如 GPT 系列)。可以通过在顶部添加一个线性层(也称为“语言模型头”)来预测下一个标记。编码器-解码器模型(BART、Pegasus、MASS、...)能够根据编码器的表示来调节解码器的输出。它可用于摘要和翻译等任务。它是通过从编码器到解码器的交叉注意力连接来完成的。在本文中,想展示如何使用仅编码器模型的预训练权重来为我们的微调提供一个良好的开始。我们将使用 BERT 作为编码器和解码器来训练一个摘要模型。Huggingface 新的 API可以混合和匹配不同的预训练模型。这让我们的工作变得超级简单!但在我们在进入代码之前先看看这个概念。应该怎么做才能使 BERT(编码器模型)在 seq2seq 中工作?为简单起见,我们删除了图 中网络的其他元素!为了进行简单的比较,仅编码器模型(左)的每个块(层)都由一个自注意力和一个线性层组成。同时,encoder-decoder 网络(右)在每一层也有一个 cross-attention 连接。交叉注意力层使模型能够根据输入来调节预测。将 BERT 模型直接用作解码器是不可能的,因为构建块是不一样,但是利用BERT的权值可以很容易地添加额外的连接并构建解码器部分。在构建完成后就需要微调模型来训练这些连接和语言模型的头部权重。(注意:语言模型的头部位置在输出和最后一个线性层之间——它不包括在上图中)我们可以使用 Huggingface 的 EncoderDecoderModel 对象来混合和匹配不同的预训练模型。它将通过调用 .from_encoder_decoder_pretrained() 方法指定编码器/解码器模型来处理添加所需的连接和权重。在下面的示例中,我们使用 BERT base 作为编码器和解码器。from transformers import EncoderDecoderModel
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased",
"bert-base-uncased")
由于 BERT 模型不是为文本生成而设计的,所以我们需要做一些额外的配置。下一步是设置标记器并指定句首和句尾标记。from transformers import BertTokenizerFast
# Set tokenizer
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
tokenizer.bos_token = tokenizer.cls_token
tokenizer.eos_token = tokenizer.sep_token
# Set model's config
bert2bert.config.decoder_start_token_id = tokenizer.bos_token_id
bert2bert.config.eos_token_id = tokenizer.eos_token_id
bert2bert.config.pad_token_id = tokenizer.pad_token_id
现在我们可以使用 Huggingface 的 Seq2Seq Trainer 对象的Seq2SeqTrainingArguments() 参数微调模型。这里可以更改和尝试许多配置,获得适合模型的参数组合。注意以下数值并非最优选择,仅用于测试!如果显存不够的话,则 fp16 值是非常重要的。它将使用半精度减少显存使用。要研究的其他有用变量是 learning_rate 、 batch_size 等。from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
training_args = Seq2SeqTrainingArguments(
output_dir="./",
learning_rate=5e-5,
evaluation_strategy="steps",
per_device_train_batch_size=4,
per_device_eval_batch_size=8,
predict_with_generate=True,
overwrite_output_dir=True,
save_total_limit=3,
fp16=True,
)
trainer = Seq2SeqTrainer(
model=bert2bert,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
)
trainer.train()
在 CNN/DM 数据集上微调的 BERT-to-BERT 模型性能。我使用 Beam Search 解码方法。使用 ROUGE 评分指标计算结果。BART 模型是文本摘要中的 SOTA 模型,BERT seq2seq 的表现也很不错!只有 1% 的差异通常不会转化为句子质量的巨大变化。这里我们也没有做任何的超参数调整,如果调整优化后会变得更好。混合搭配方法可以让我们进行更多的实验。例如可以将 BERT 连接到 GPT-2 以利用 BERT 的来创建强大的文本表示以及 GPT 生成高质量句子的能力。在为所有问题选择 SOTA 模型之前,为自定义数据集使用不同的网络是一种很好的做法。使用 BERT(与 BART 相比)的主要区别在于 512 个令牌输入序列长度限制(与 1024 相比)。因此,如果数据集的输入序列较小,它使 BERT-to-BERT 模型会是一个不错的选择。它训练较小的模型会更有效,并且需要更少的资源,例如数据和 GPU 内存。本文的代码在这里可以找到:
https://github.com/NLPiation/tutorial_notebooks/blob/main/summarization/hf_BERT-BERT_training.ipynb