
Prometheus 高可用方案

Prometheus的本地存储给Prometheus带来了简单高效的使用体验,可以让Promthues在单节点的情况下满足大部分用户的监控需求。但是本地存储也同时限制了Prometheus的可扩展性,带来了数据持久化等一系列的问题。通过Prometheus的Remote Storage特性可以解决这一系列问题,包括Promthues的动态扩展,以及历史数据的存储。
而除了数据持久化问题以外,影响Promthues性能表现的另外一个重要因素就是数据采集任务量,以及单台Promthues能够处理的时间序列数。因此当监控规模大到Promthues单台无法有效处理的情况下,可以选择利用Promthues的联邦集群的特性,将Promthues的监控任务划分到不同的实例当中。
这一部分将重点讨论Prometheus的高可用架构。
一、现实可用的小规模高可用方案
关于 Prometheus 的高可用,官方文档中只提供了一个解决方案,具体实现方式如下:
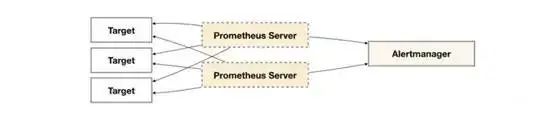
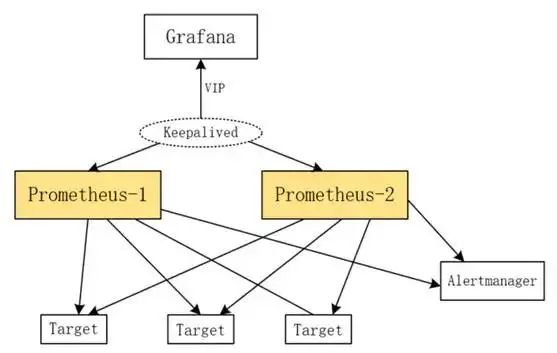
使用两个 Prometheus 主机监控同样的目标,然后有告警出现,也会发送同样的告警给 Alertmanager,然后使用 Alertmanager 自身的去重告警功能,只发出一条告警出来。从而实现了 prometheus 高可用的一个架构。 基于此架构,我们还可以使用 keepalived 做双机热备,通过 VIP 与 grafana 相连。实现一个完整的带 web 界面展示告警的高可用 Prometheus 监控架构。
根据查找的资料,可知 Prometheus 的监控数量和 Prometheus 主机的内存和磁盘大小的关系表。
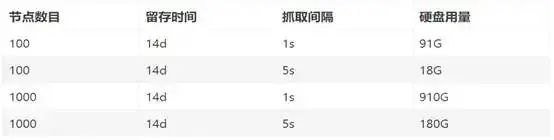
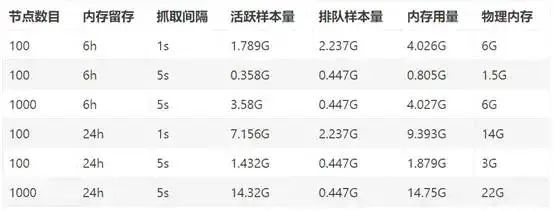
根据表格中数据,我们可以用两台 8G 内存,磁盘大小为 100G 的 Prometheus 主机做主备架构,进行 500 个节点以下的基础架构的监控,然后由于抓取间隔和数据留存时间的设定是直接关乎内存和磁盘空间的使用率,所以我们可以通过调整这两点,来调整内存和磁盘空间到合适的值。
二、大规模监控的高可用方案
根据官方文档,Prometheus 有一个面向于大规模目标监控的功能** FEDERATION ** 联邦机制,是指从其它 Prometheus 主机上抓取特定的数据到一个汇总的 Prometheus 主机中,既然是从其它 Prometheus 主机汇总而来,那么数据量会很大,难以长久储存在主机本地,所以我们需要使用 Prometheus 的远程读写数据库的功能,来远程保存至第三方数据库。 而这个用于汇总的 Prometheus 主机,我们也使用主备两台主机做高可用处理,不过与第三方数据库之间需要用一个 adapter 工具,来做主备数据库传输切换。如下图所示。
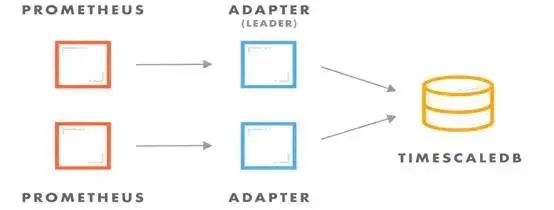
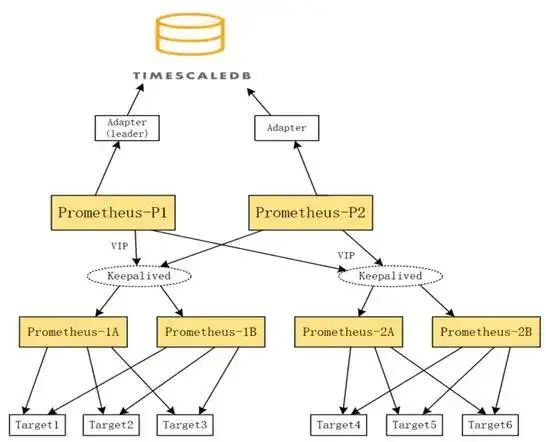
在这里第三方存储是使用的 PostgreSQL + TimescaleDB,而 adapter 是用的官方开发的 Prometheus-postgresql-adpter 自带 leader 切换的功能,当设置好 Prometheus 和 adapter 后,如果 adapter 长时间没有收到对应的 Prometheus 的数据,那么它会自动锁定然后切换到备用 adapter,备用 adpter 会将自己所对应的 Prometheus 主机的数据发往第三方存储。 也就是说,这两台 Prometheus 主机都是会实时接收其它相同 Prometheus 主机的数据,然后只有其中一方的数据会被标识为 leader 的 adapter 发送到第三方存储中。完整架构图如下。
三、总结
不管是第一章的小规模监控高可用方案还是第二章的大规模监控高可用方案,主要应用的还是 Prometheus 官方文档提到高可用方法和 Prometheus 的联邦机制机远程读写存储的功能。而主备切换的工具 keepalive 和 Prometheus-postgresql-adpter,以及远程数据库 PostgreSQL+TimescaleDB,这些都可以替换成 Nginx proxy、服务注册工具 consul,远程存储 Thanos,我们可以根据实际需求做测试,再决定使用哪些第三方工具。
文章转载:Devops技术栈
(版权归原作者所有,侵删)
有收获,点个在看
