清华大学张亚勤:智能计算新趋势
Python高校
共 5661字,需浏览 12分钟
·
2021-12-02 12:55
点击“凹凸域”,马上关注
更多内容、请置顶或星标
来源:人工智能和大数据
本文约5467字,建议阅读10分钟
本文介绍了张亚勤院士分享的有关于产业发展新趋势以及人工智能在生命科学、 双碳趋势下的绿色计算、自动驾驶等领域中扮演的角色。

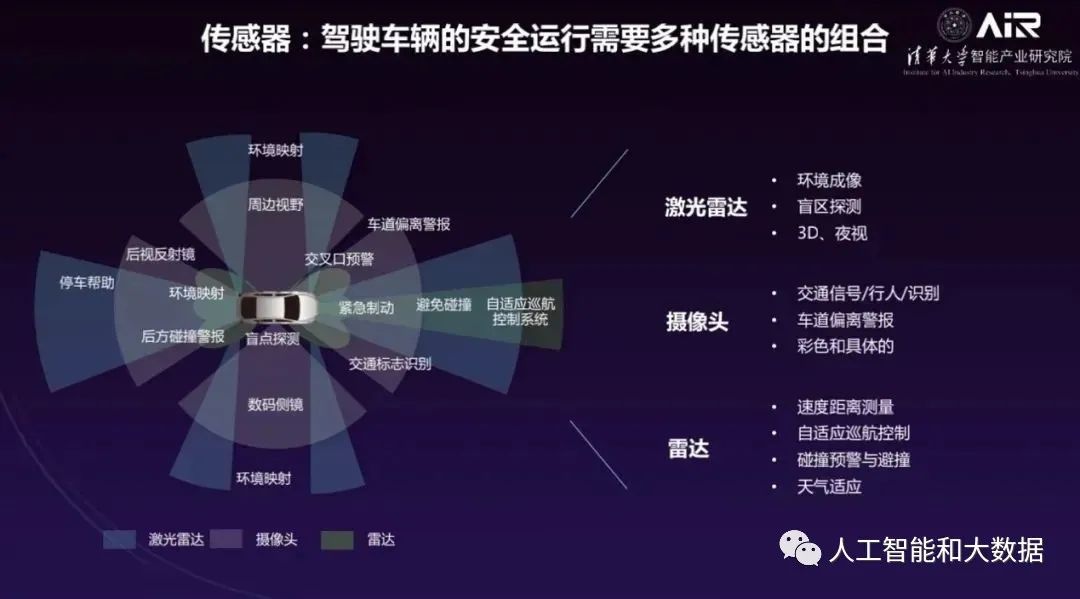
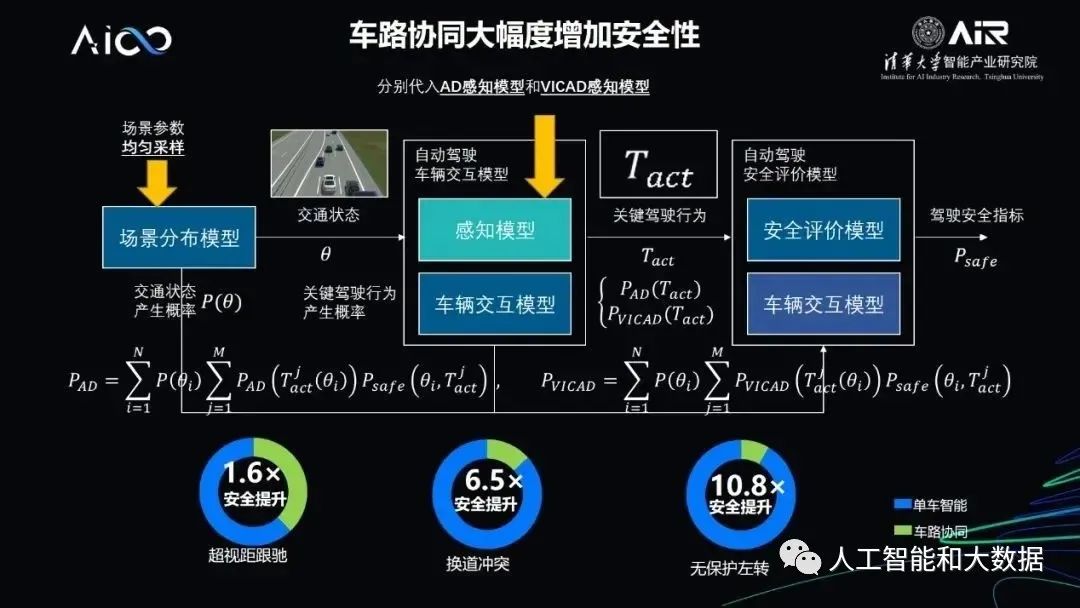
— END —
想要了解更多AI资讯
点这里👇关注我,记得标星呀~
请点击上方卡片,专注计算机人工智能方向的研究
评论

共 5661字,需浏览 12分钟
·
2021-12-02 12:55
点击“凹凸域”,马上关注
更多内容、请置顶或星标
来源:人工智能和大数据
本文约5467字,建议阅读10分钟
本文介绍了张亚勤院士分享的有关于产业发展新趋势以及人工智能在生命科学、 双碳趋势下的绿色计算、自动驾驶等领域中扮演的角色。
— END —
想要了解更多AI资讯
点这里👇关注我,记得标星呀~
请点击上方卡片,专注计算机人工智能方向的研究