
MySQL千万数据调研,order by 原理详解
大家好,我是Leo。
之前聊的RocketMQ暂时放放,目前正在调研一个千万数据的处理方案。
在做数据库结构优化时,遇到了 order by 调优点的问题。苦思冥想!觉得不了解 order by 的原理,无法把这个细节把控好。于是就来了这一篇。

基础知识系列
大厂面试系列
本章概括
order by 默认算法
首先看一下表的建表语句以及查询语句,这里SQL只是伪代码。
CREATE TABLE `waybill` (
`id` bigint(20) NOT NULL,
`shipping_number` varchar(26) COMMENT '运单号',
`order_create_time` datetime COMMENT '开单时间',
`status` tinyint(1) comment '运单状态',
PRIMARY KEY (`id`),
KEY `waybill_index_status` (`status`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='运单表';
explain SELECT shipping_number,age,status FROM `waybill` where status = 4 order by order_create_time desc
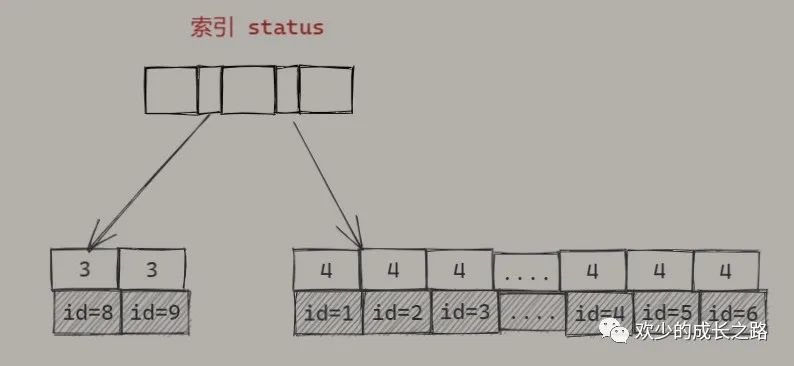
根据伪代码和索引我们画一下 B+树的原型图。方便大家更好的理解
附带着贴一下 执行计划后的结果集,由 Using filesort 可以看出这是需要排序的,也证实了我们上述的 order by

根据索引结构图分析一下执行流程
初始化 sort_buffer,放入shipping_number,order_create_time,status字段。从索引status树上寻找满足 status=4的主键id,也就是图上的1,2,3,.....4,5,6拿到了主键id再去主键树上取出id为 1,2,3,.....4,5,6的shipping_number,order_create_time,status三个字段的值,然后放入sort_buffer。依次取出所有的id对应的值也就结束了。 最后在 sort_buffer中对 order_create_time 字段进行快速排序,返回所有满足数据的数据
sort_buffer 是一个用于排序的buffer缓冲区
上述流程中的第五步,在 sort_buffer 中排序的规则主要 sort_buffer_size 决定的。我们可以通过下列代码查询对应的值。默认为256K。
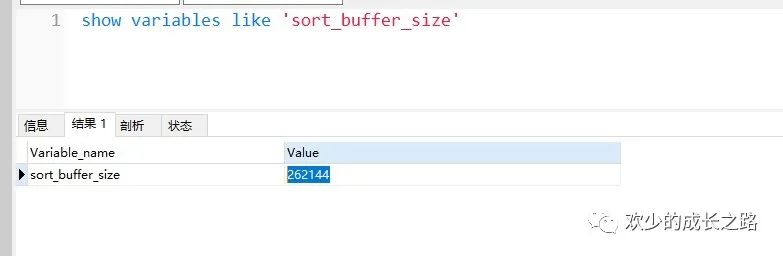
这个是MySQL开辟给排序的内存大小,如果小于这个值就在内存中完成。如果大于这个值就在磁盘临时文件中辅助排序。
可以通过这个参数 number_of_tmp_files 来决定是否使用了临时文件排序,它表示的是排序过程中使用的临时文件数。
他会把分成的每一个文件,先在文件中排序,最后再把所有文件再合并成一个有序的大文件。
当 sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files 的值就越大。
rowid算法
第二种排序算法,我们可以称为 rowid 排序。
默认的话还是采用上面那种算法,如果要采用 rowid 排序算法的话需要修改一个参数
SET max_length_for_sort_data = 16;
max_length_for_sort_data 是MySQL提供的一个判断采用哪种算法的参数。
如果单行的长度超过这个值,就认为太多,换一个rowid算法。否则就用默认算法。
由上述表的自定义我们可以得知,26+8+1=35。36大于16,所以会采用rowid算法
shipping_number 为 26 order_create_time为 8 status 为 1
rowid算法,执行流程 如下:
初始化 sort_buffer, 放入 order_create_time 和 id 这两个字段。从索引树 status上找到满足条件的id,也就是 1,2,3,.....4,5,6回到主键树上查找对应的order_create_time 和 id放入 sort_buffer中重复找到所有的id的对应的值,循环结束 对 sort_buffer中的数据按照字段order_create_time 进行排序。遍历排序结果取出所有满足条件的数据,并按照id回到原表中取出shipping_number,age,status字段返回给客户端
区别
默认算法与rowid的区别
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。 如果 MySQL 认为内存足够大,会优先选择默认算法排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
优化
优化可以分多层优化。
第一层优化就是给排序的字段加上索引,让他在索引树上查找数据时更快。 第二层优化就是通过根据排序的数据大小,来决定采用哪种算法,第二层也就是内存与磁盘的抉择。 第三层优化是从数据底层优化的。直接在插入数据的时候就按照列表的数据插入
第三层的方案主要有三种
id自增(越来越大,也是有序的) 雪花算法生成id(根据时间戳生成的,自然也是有序的) 利用组合索引(索引的有序性) 字段少的话可以考虑覆盖索引 覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
结尾
有些不懂的地方或者不对的地方,麻烦各位指出,一定修改优化!
非常欢迎大家加我个人微信有关后端方面的问题我们在群内一起讨论! 我们下期再见!
长按上方扫码二维码,加我微信,拉你进群
