
用 Python 删除文件中的乱码
当我们用 Python 来处理有乱码的文件时,经常会遇到编码错误,有时候不得不加一个 errors = 'ignore' 参数来忽略错误,今天分享一下如何用 Python 来删除这些乱码,得到一个干净的文件。
先说下思路:用二进制方式打开文件,这样就不会出现编码问题,然后读取每一个字节,只要这个字节不在我们使用编码的范围内,就把它踢掉,然后保存剩下的字节,我们得到的就是一个干净的文件。
比如说这样 ascii 编码的文件,它含有乱码:
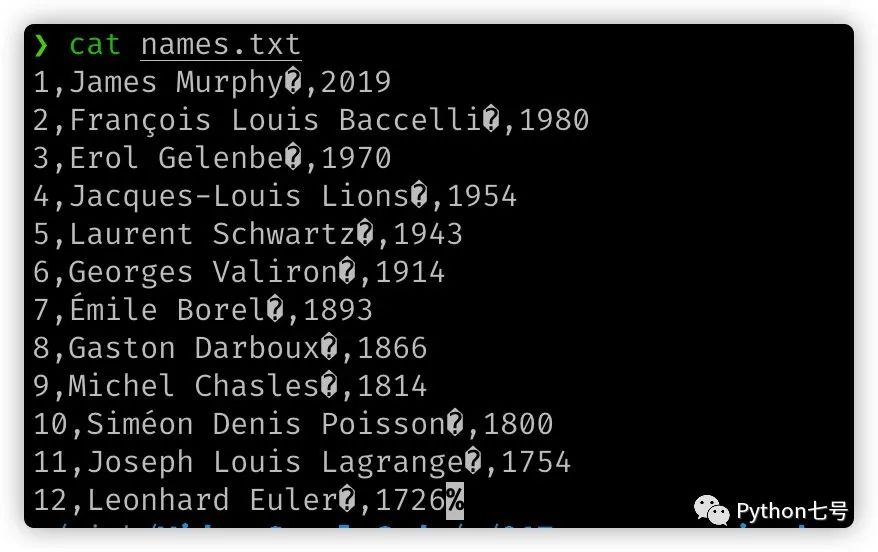
处理之后是这样的:
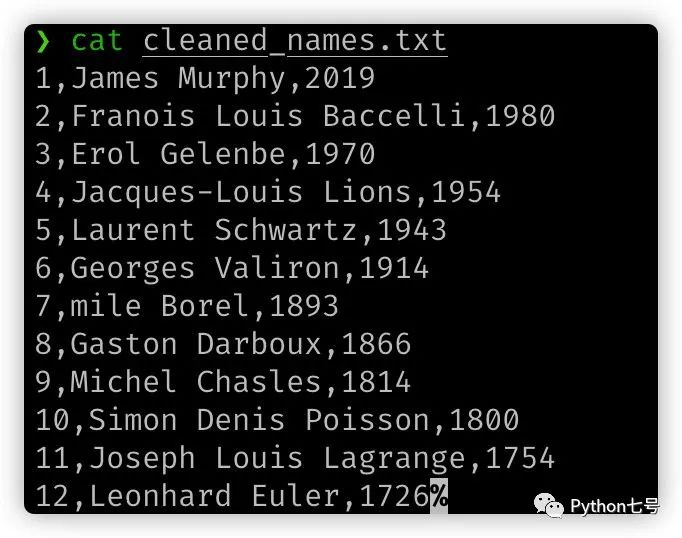
代码是这样写的:
import struct
def is_good_byte(b):
"""
可以自定义什么是好字节,比如 GBK 的字节范围可以在这里定义好
"""
return b <= 127
def clean_bytes(bs):
return filter(is_good_byte, bs)
def clean_file_bin():
with open("names.txt", mode = "rb") as reader:
with open("cleaned_names.txt", mode = "wb") as writer:
for line in reader:
for byte in clean_bytes(line):
writer.write(struct.pack('B',byte))
if __name__ == '__main__':
clean_file_bin()
上面这段代码是一个字节一个字节来处理的,如果是多字节编码,可以自行修改代码逻辑,比如一次读取 3 个字节,判断这三个字节是否一个合法的字节组合。
对于中英文混合的,比如:
>>> x
'abc中国'
>>> x.encode("GBK")
b'abc\xd6\xd0\xb9\xfa'
>>> for i in x.encode("GBK"):
... print(i)
...
97
98
99
214
208
185
250
>>>
需要综合判断,先判断是否英文字母,是的就放行,然后看接下来的两个字节是否在 GBK 的编码范围之内,是的就放行,不是就要删除,看看是删除一个字节,还是两个字节就要继续判断了。删除的依据就是不会造成更多乱码。
今天的分享就到这里,如果有收获请点赞哦。
评论