
面试题:推荐系统有哪些常用的评价标准

文 | 七月在线
编 | 小七
解析:
常用的评价标准:
一类是线上的评测,比如通过点击率、网站流量、A/B test等判断。这类评价标准在这里就不细说了,因为它们并不能参与到线下训练模型和选择模型的过程当中。
第二类是线下评测。评测标准很多,我挑几个常用的。我就拿给用户推荐阅读相关链接来举例好了。
1. 精度Precision:P(k)
P(k) = c/k
我们给某个用户推荐了k个链接,他/她点击了其中的c个链接,那么精度就是c/k。
2. 平均精度Average Precision: ap@n
n是被预测的链接的总数,m是用户点击的链接的总数。
例子1:我们一共推荐了10个链接,用户实际上点击了我们推荐当中的第1个和第4个链接,以及另外两个其他的链接,那么对于这个用户,
ap@10=(1/1+2/4)/4≈0.38
例子2:我们一共推荐了10个链接,用户实际上点击了我们推荐当中的第2个,第3个和第5个链接,以及另外三个其他的链接,那么对于这个用户,
ap@10=(1/2+2/3+3/5)/6≈0.29
例子3:我们一共推荐了10个链接,用户实际上点击了我们推荐当中的第2个,第7个,此外没有点击其他联系,那么对于这个用户,
ap@10=(1/2+2/7)/2≈0.39
例子4:我们一共推荐了5个链接,用户实际上点击了我们推荐当中的第1个,第2个和第4个,以及另外6个其他链接,那么对于这个用户,
ap@5=(1/1+2/2+3/4)/5≈0.55
3. 平均精度均值Mean Average Precision: MAP@n
MAP计算的是N个用户的平均精度的均值。
这个N是用户数量。比如说我们三个用户甲、乙、丙分别推荐了10个链接,
甲点击了我们推荐当中的第1个和第4个链接,以及另外两个其他的链接,那么(ap@10)1=(1/1+2/4)/4≈0.38.
乙点击了我们推荐当中的第3个链接,以及另外一个其他的链接,那么(ap@10)2=(1/3)/2≈0.17.
丙点击了我们推荐当中的第1个链接,第7个链接,以及另外三个其他的链接,那么(ap@10)3=(1/1+2/7)/5≈0.26.
那么这个模型的平均精度均值
MAP@10 = (0.38+0.17+0.26)/3 ≈ 0.27
更多请参考:http://sofasofa.io/forum_main_post.php?postid=1000292
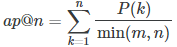
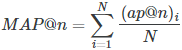
今日推荐:【知识图谱实战】
从零开始搭建平台,大佬实时授课
课程详情如下:




评论