
5分钟快速掌握 Adam 优化算法

梯度下降是一种优化算法,它使用目标函数的梯度来导航搜索空间。 可以通过使用称为Adam的偏导数的递减平均值,将梯度下降更新为对每个输入变量使用自动自适应步长。 如何从头开始实施Adam优化算法并将其应用于目标函数并评估结果。
梯度下降 Adam优化算法 Adam梯度下降 二维测试问题 Adam的梯度下降优化 Adam可视化
x(t)= x(t-1)–step* f'(x(t-1))m = 0 v = 0t=1开始的时间t内迭代执行,并且每次迭代都涉及计算一组新的参数值x,例如。从x(t-1)到x(t)。如果我们专注于更新一个参数,这可能很容易理解该算法,该算法概括为通过矢量运算来更新所有参数。首先,计算当前时间步长的梯度(偏导数)。g(t)= f'(x(t-1))beta1更新第一时刻。m(t)= beta1 * m(t-1)+(1 – beta1)* g(t)v(t)= beta2 * v(t-1)+(1 – beta2)* g(t)^ 2mhat(t)= m(t)/(1 – beta1(t))vhat(t)= v(t)/(1 – beta2(t))beta1(t)和beta2(t)指的是beta1和beta2超参数,它们在算法的迭代过程中按时间表衰减。可以使用静态衰减时间表,尽管该论文建议以下内容:beta1(t)= beta1 ^ tbeta2(t)= beta2 ^ tx(t)= x(t-1)– alpha * mhat(t)/(sqrt(vhat(t))+ eps)alpha(t)= alpha * sqrt(1 – beta2(t))/(1 – beta1(t)) x(t)= x(t-1)– alpha(t)* m(t)/(sqrt(v(t))+ eps)alpha:初始步长(学习率),典型值为0.001。 beta1:第一个动量的衰减因子,典型值为0.9。 beta2:无穷大范数的衰减因子,典型值为0.999。
Objective()函数实现了此功能# objective function
def objective(x, y):
return x**2.0 + y**2.0
# 3d plot of the test function
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# define range for input
r_min, r_max = -1.0, 1.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
f(0,0)= 0的熟悉的碗形状。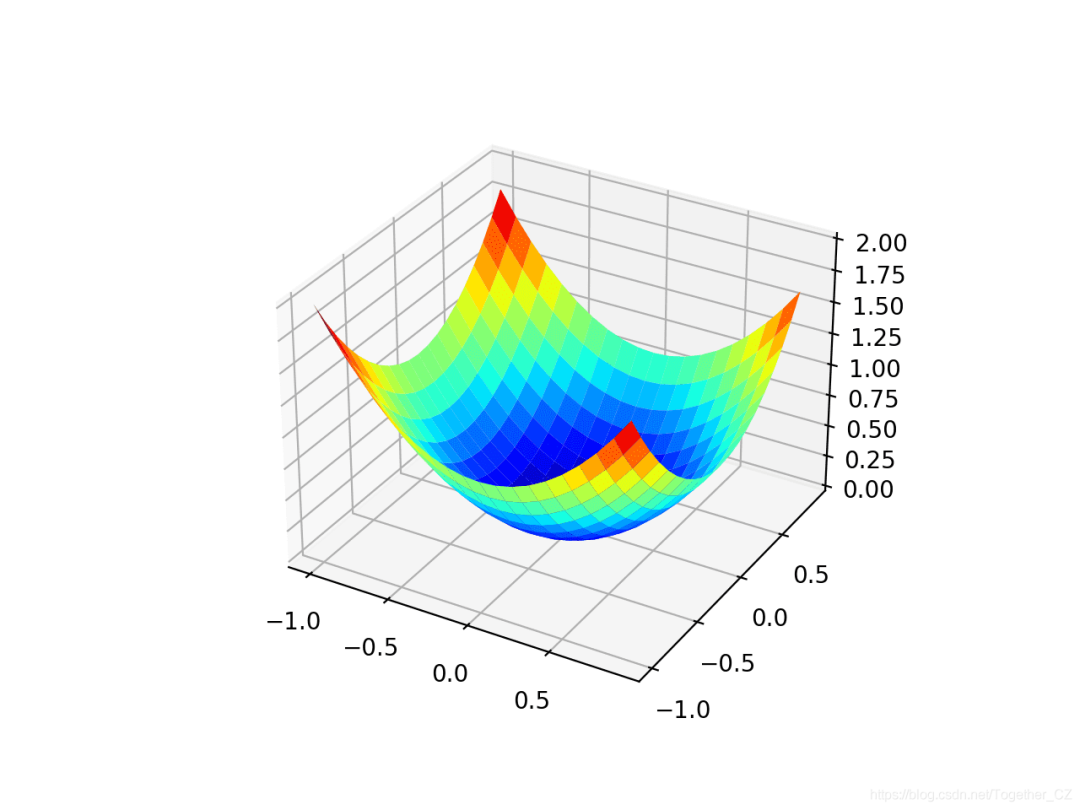
# contour plot of the test function
from numpy import asarray
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# define range for input
bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]])
# sample input range uniformly at 0.1 increments
xaxis = arange(bounds[0,0], bounds[0,1], 0.1)
yaxis = arange(bounds[1,0], bounds[1,1], 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a filled contour plot with 50 levels and jet color scheme
pyplot.contourf(x, y, results, levels=50, cmap='jet')
# show the plot
pyplot.show()
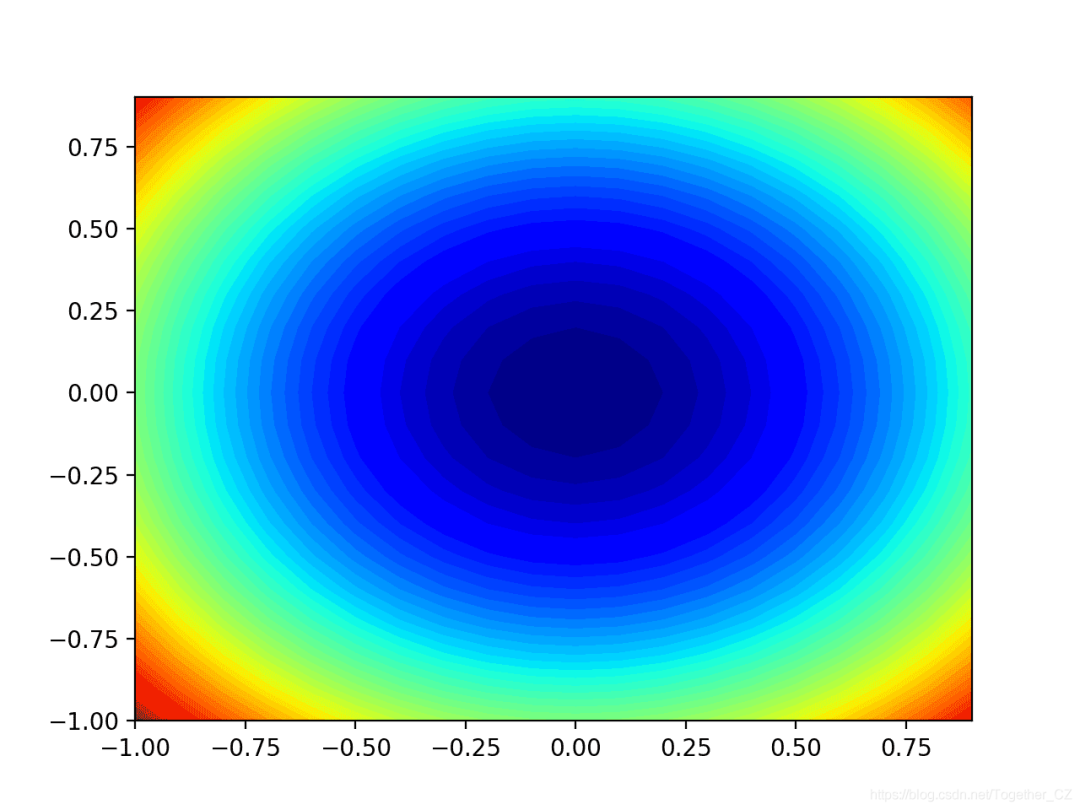
f(x)= x ^ 2f'(x)= x * 2x ^ 2的导数在每个维度上均为x * 2。 derived()函数在下面实现了这一点。# derivative of objective function
def derivative(x, y):
return asarray([x * 2.0, y * 2.0])
# generate an initial point
x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0])
score = objective(x[0], x[1])
# initialize first and second moments
m = [0.0 for _ in range(bounds.shape[0])]
v = [0.0 for _ in range(bounds.shape[0])]
...
# run iterations of gradient descent
for t in range(n_iter):
...
# calculate gradient
gradient = derivative(solution[0], solution[1])
# calculate gradient g(t)
g = derivative(x[0], x[1])
...
# build a solution one variable at a time
for i in range(x.shape[0]):
...
# m(t) = beta1 * m(t-1) + (1 - beta1) * g(t)
m[i] = beta1 * m[i] + (1.0 - beta1) * g[i]
# v(t) = beta2 * v(t-1) + (1 - beta2) * g(t)^2
v[i] = beta2 * v[i] + (1.0 - beta2) * g[i]**2
# mhat(t) = m(t) / (1 - beta1(t))
mhat = m[i] / (1.0 - beta1**(t+1))
# vhat(t) = v(t) / (1 - beta2(t))
vhat = v[i] / (1.0 - beta2**(t+1))
# x(t) = x(t-1) - alpha * mhat(t) / (sqrt(vhat(t)) + eps)
x[i] = x[i] - alpha * mhat / (sqrt(vhat) + eps)
# evaluate candidate point
score = objective(x[0], x[1])
# report progress
print('>%d f(%s) = %.5f' % (t, x, score))
adam()的函数中,该函数采用目标函数和派生函数的名称以及算法超参数,并返回在搜索及其评估结束时找到的最佳解决方案。# gradient descent algorithm with adam
def adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2, eps=1e-8):
# generate an initial point
x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0])
score = objective(x[0], x[1])
# initialize first and second moments
m = [0.0 for _ in range(bounds.shape[0])]
v = [0.0 for _ in range(bounds.shape[0])]
# run the gradient descent updates
for t in range(n_iter):
# calculate gradient g(t)
g = derivative(x[0], x[1])
# build a solution one variable at a time
for i in range(x.shape[0]):
# m(t) = beta1 * m(t-1) + (1 - beta1) * g(t)
m[i] = beta1 * m[i] + (1.0 - beta1) * g[i]
# v(t) = beta2 * v(t-1) + (1 - beta2) * g(t)^2
v[i] = beta2 * v[i] + (1.0 - beta2) * g[i]**2
# mhat(t) = m(t) / (1 - beta1(t))
mhat = m[i] / (1.0 - beta1**(t+1))
# vhat(t) = v(t) / (1 - beta2(t))
vhat = v[i] / (1.0 - beta2**(t+1))
# x(t) = x(t-1) - alpha * mhat(t) / (sqrt(vhat(t)) + eps)
x[i] = x[i] - alpha * mhat / (sqrt(vhat) + eps)
# evaluate candidate point
score = objective(x[0], x[1])
# report progress
print('>%d f(%s) = %.5f' % (t, x, score))
return [x, score]
# seed the pseudo random number generator
seed(1)
# define range for input
bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]])
# define the total iterations
n_iter = 60
# steps size
alpha = 0.02
# factor for average gradient
beta1 = 0.8
# factor for average squared gradient
beta2 = 0.999
# perform the gradient descent search with adam
best, score = adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2)
print('Done!')
print('f(%s) = %f' % (best, score))
# gradient descent optimization with adam for a two-dimensional test function
from math import sqrt
from numpy import asarray
from numpy.random import rand
from numpy.random import seed
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# derivative of objective function
def derivative(x, y):
return asarray([x * 2.0, y * 2.0])
# gradient descent algorithm with adam
def adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2, eps=1e-8):
# generate an initial point
x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0])
score = objective(x[0], x[1])
# initialize first and second moments
m = [0.0 for _ in range(bounds.shape[0])]
v = [0.0 for _ in range(bounds.shape[0])]
# run the gradient descent updates
for t in range(n_iter):
# calculate gradient g(t)
g = derivative(x[0], x[1])
# build a solution one variable at a time
for i in range(x.shape[0]):
# m(t) = beta1 * m(t-1) + (1 - beta1) * g(t)
m[i] = beta1 * m[i] + (1.0 - beta1) * g[i]
# v(t) = beta2 * v(t-1) + (1 - beta2) * g(t)^2
v[i] = beta2 * v[i] + (1.0 - beta2) * g[i]**2
# mhat(t) = m(t) / (1 - beta1(t))
mhat = m[i] / (1.0 - beta1**(t+1))
# vhat(t) = v(t) / (1 - beta2(t))
vhat = v[i] / (1.0 - beta2**(t+1))
# x(t) = x(t-1) - alpha * mhat(t) / (sqrt(vhat(t)) + eps)
x[i] = x[i] - alpha * mhat / (sqrt(vhat) + eps)
# evaluate candidate point
score = objective(x[0], x[1])
# report progress
print('>%d f(%s) = %.5f' % (t, x, score))
return [x, score]
# seed the pseudo random number generator
seed(1)
# define range for input
bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]])
# define the total iterations
n_iter = 60
# steps size
alpha = 0.02
# factor for average gradient
beta1 = 0.8
# factor for average squared gradient
beta2 = 0.999
# perform the gradient descent search with adam
best, score = adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2)
print('Done!')
print('f(%s) = %f' % (best, score))
>50 f([-0.00056912 -0.00321961]) = 0.00001
>51 f([-0.00052452 -0.00286514]) = 0.00001
>52 f([-0.00043908 -0.00251304]) = 0.00001
>53 f([-0.0003283 -0.00217044]) = 0.00000
>54 f([-0.00020731 -0.00184302]) = 0.00000
>55 f([-8.95352320e-05 -1.53514076e-03]) = 0.00000
>56 f([ 1.43050285e-05 -1.25002847e-03]) = 0.00000
>57 f([ 9.67123406e-05 -9.89850279e-04]) = 0.00000
>58 f([ 0.00015359 -0.00075587]) = 0.00000
>59 f([ 0.00018407 -0.00054858]) = 0.00000
Done!
f([ 0.00018407 -0.00054858]) = 0.000000
# gradient descent algorithm with adam
def adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2, eps=1e-8):
solutions = list()
# generate an initial point
x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0])
score = objective(x[0], x[1])
# initialize first and second moments
m = [0.0 for _ in range(bounds.shape[0])]
v = [0.0 for _ in range(bounds.shape[0])]
# run the gradient descent updates
for t in range(n_iter):
# calculate gradient g(t)
g = derivative(x[0], x[1])
# build a solution one variable at a time
for i in range(bounds.shape[0]):
# m(t) = beta1 * m(t-1) + (1 - beta1) * g(t)
m[i] = beta1 * m[i] + (1.0 - beta1) * g[i]
# v(t) = beta2 * v(t-1) + (1 - beta2) * g(t)^2
v[i] = beta2 * v[i] + (1.0 - beta2) * g[i]**2
# mhat(t) = m(t) / (1 - beta1(t))
mhat = m[i] / (1.0 - beta1**(t+1))
# vhat(t) = v(t) / (1 - beta2(t))
vhat = v[i] / (1.0 - beta2**(t+1))
# x(t) = x(t-1) - alpha * mhat(t) / (sqrt(vhat(t)) + ep)
x[i] = x[i] - alpha * mhat / (sqrt(vhat) + eps)
# evaluate candidate point
score = objective(x[0], x[1])
# keep track of solutions
solutions.append(x.copy())
# report progress
print('>%d f(%s) = %.5f' % (t, x, score))
return solutions
# seed the pseudo random number generator
seed(1)
# define range for input
bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]])
# define the total iterations
n_iter = 60
# steps size
alpha = 0.02
# factor for average gradient
beta1 = 0.8
# factor for average squared gradient
beta2 = 0.999
# perform the gradient descent search with adam
solutions = adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2)
# sample input range uniformly at 0.1 increments
xaxis = arange(bounds[0,0], bounds[0,1], 0.1)
yaxis = arange(bounds[1,0], bounds[1,1], 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a filled contour plot with 50 levels and jet color scheme
pyplot.contourf(x, y, results, levels=50, cmap='jet')
# plot the sample as black circles
solutions = asarray(solutions)
pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w')
# example of plotting the adam search on a contour plot of the test function
from math import sqrt
from numpy import asarray
from numpy import arange
from numpy.random import rand
from numpy.random import seed
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# derivative of objective function
def derivative(x, y):
return asarray([x * 2.0, y * 2.0])
# gradient descent algorithm with adam
def adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2, eps=1e-8):
solutions = list()
# generate an initial point
x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0])
score = objective(x[0], x[1])
# initialize first and second moments
m = [0.0 for _ in range(bounds.shape[0])]
v = [0.0 for _ in range(bounds.shape[0])]
# run the gradient descent updates
for t in range(n_iter):
# calculate gradient g(t)
g = derivative(x[0], x[1])
# build a solution one variable at a time
for i in range(bounds.shape[0]):
# m(t) = beta1 * m(t-1) + (1 - beta1) * g(t)
m[i] = beta1 * m[i] + (1.0 - beta1) * g[i]
# v(t) = beta2 * v(t-1) + (1 - beta2) * g(t)^2
v[i] = beta2 * v[i] + (1.0 - beta2) * g[i]**2
# mhat(t) = m(t) / (1 - beta1(t))
mhat = m[i] / (1.0 - beta1**(t+1))
# vhat(t) = v(t) / (1 - beta2(t))
vhat = v[i] / (1.0 - beta2**(t+1))
# x(t) = x(t-1) - alpha * mhat(t) / (sqrt(vhat(t)) + ep)
x[i] = x[i] - alpha * mhat / (sqrt(vhat) + eps)
# evaluate candidate point
score = objective(x[0], x[1])
# keep track of solutions
solutions.append(x.copy())
# report progress
print('>%d f(%s) = %.5f' % (t, x, score))
return solutions
# seed the pseudo random number generator
seed(1)
# define range for input
bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]])
# define the total iterations
n_iter = 60
# steps size
alpha = 0.02
# factor for average gradient
beta1 = 0.8
# factor for average squared gradient
beta2 = 0.999
# perform the gradient descent search with adam
solutions = adam(objective, derivative, bounds, n_iter, alpha, beta1, beta2)
# sample input range uniformly at 0.1 increments
xaxis = arange(bounds[0,0], bounds[0,1], 0.1)
yaxis = arange(bounds[1,0], bounds[1,1], 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a filled contour plot with 50 levels and jet color scheme
pyplot.contourf(x, y, results, levels=50, cmap='jet')
# plot the sample as black circles
solutions = asarray(solutions)
pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w')
# show the plot
pyplot.show()
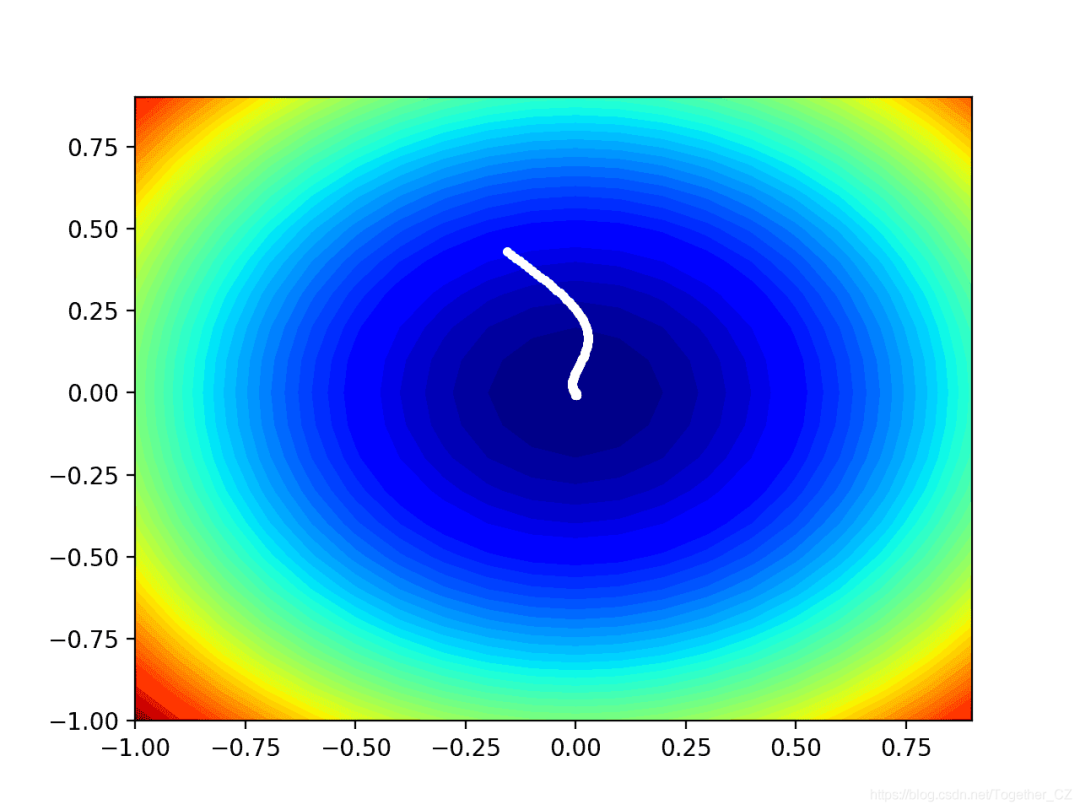
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论