
做动态图表找不到数据?手把手教你用Python轻松获取!

关于如何用Python制作酷炫的动态图表
之前转载过一篇文章,刷爆全网的动态条形图,原来5行Python代码就能实现!
既然有了Python这个制作动态条形图工具,缺的那便是数据了。
先看一下B站2019年「数据可视化」版块的情况,第一个视频超2百万的播放量,4万+的弹幕。
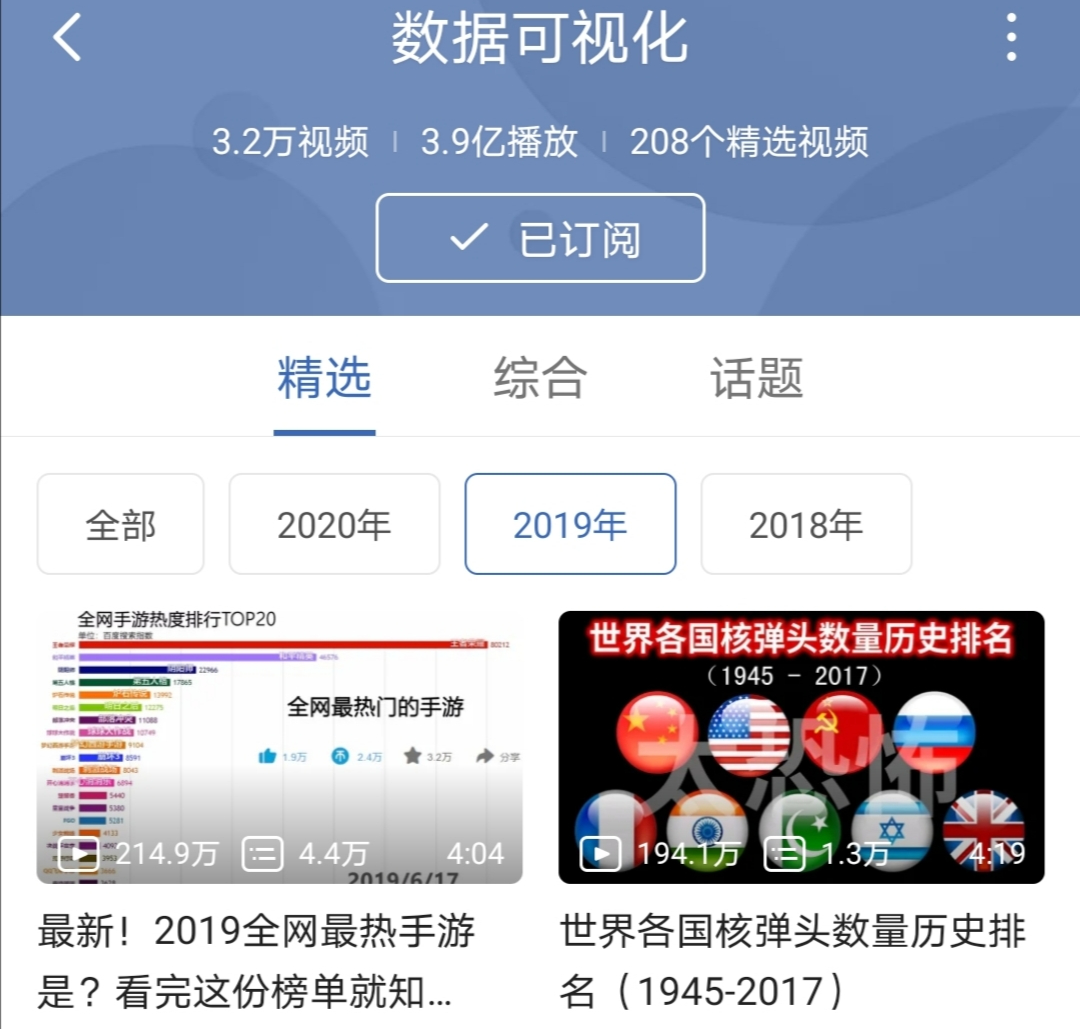
小F自己在B站上制作的几个视频,也是几十万的播放量,累计获得1万赞。
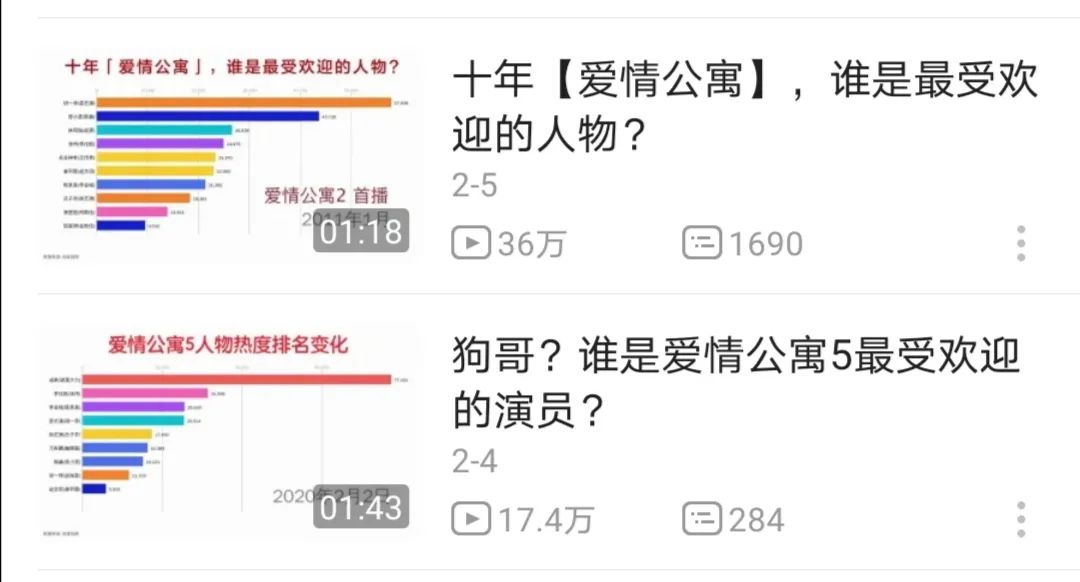
那么作者是用什么来衡量手游的热门程度呢,答案便是百度指数。
同样小F使用的也是百度指数,百度指数是以百度海量网民行为数据为基础的数据分享平台。
所以本期就来聊一聊可视化视频的数据获取,主要是「百度指数」和「微博指数」。
本来想加上「微信指数」的,发现电脑的抓包软件出了问题,所以就没有加上。
01. 百度指数
获取百度指数,首先需要登陆你的百度账号。
以关键词「王者荣耀」为例,时间自定义为2020-10-01~2020-10-10。
通过开发者工具,我们就能看到曲线图的数据接口。
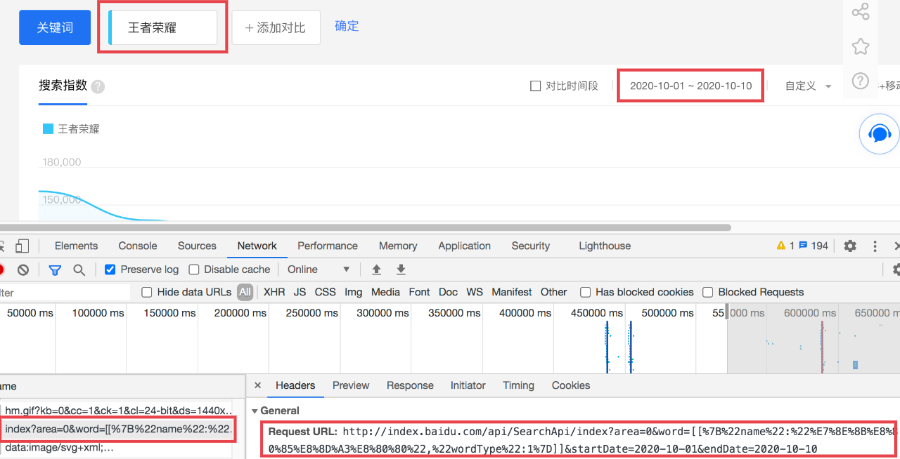
然而一看请求得到的结果,发现并没有数据,原因是这里使用了JS加密。
这可碰到小F的知识盲区了,果断选择去找度娘,各位有兴趣的同学也可自行百度。
最终找到解决方法,成功实现爬取,代码如下~
import time
import json
import execjs
import datetime
import requests
from urllib.parse import urlencode
def get_data(keywords, startDate, endDate, area):
"""
获取加密的参数数据
"""
# data_url = "http://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80%22,%22wordType%22:1%7D]]&startDate=2020-10-01&endDate=2020-10-10"
params = {
'word': json.dumps([[{'name': keyword, 'wordType': 1}] for keyword in keywords]),
'startDate': startDate,
'endDate': endDate,
'area': area
}
data_url = 'http://index.baidu.com/api/SearchApi/index?' + urlencode(params)
# print(data_url)
headers = {
# 复制登录后的cookie
"Cookie": '你的cookie',
"Referer": "http://index.baidu.com/v2/main/index.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# 获取data和uniqid
res = requests.get(url=data_url, headers=headers).json()
data = res["data"]["userIndexes"][0]["all"]["data"]
uniqid = res["data"]["uniqid"]
# 获取js函数中的参数t = "ev-fxk9T8V1lwAL6,51348+.9270-%"
t_url = "http://index.baidu.com/Interface/ptbk?uniqid={}".format(uniqid)
rep = requests.get(url=t_url, headers=headers).json()
t = rep["data"]
return {"data": data, "t": t}
def get_search_index(word, startDate, endDate, area):
"""
获取最终数据
"""
word = word
startDate = startDate
endDate = endDate
# 调用get_data获取data和uniqid
res = get_data(word, startDate, endDate, area)
e = res["data"]
t = res["t"]
# 读取js文件
with open('parsing_data_function.js', encoding='utf-8') as f:
js = f.read()
# 通过compile命令转成一个js对象
docjs = execjs.compile(js)
# 调用function方法,得到指数数值
res = docjs.call('decrypt', t, e)
# print(res)
return res
def get_date_list(begin_date, end_date):
"""
获取时间列表
"""
dates = []
dt = datetime.datetime.strptime(begin_date, "%Y-%m-%d")
date = begin_date[:]
while date <= end_date:
dates.append(date)
dt += datetime.timedelta(days=1)
date = dt.strftime("%Y-%m-%d")
return dates
def get_area():
areas = {"901": "山东", "902": "贵州", "903": "江西", "904": "重庆", "905": "内蒙古", "906": "湖北", "907": "辽宁", "908": "湖南", "909": "福建", "910": "上海", "911": "北京", "912": "广西", "913": "广东", "914": "四川", "915": "云南", "916": "江苏", "917": "浙江", "918": "青海", "919": "宁夏", "920": "河北", "921": "黑龙江", "922": "吉林", "923": "天津", "924": "陕西", "925": "甘肃", "926": "新疆", "927": "河南", "928": "安徽", "929": "山西", "930": "海南", "931": "台湾", "932": "西藏", "933": "香港", "934": "澳门"}
for value in areas.keys():
try:
word = ['王者荣耀']
time.sleep(1)
startDate = '2020-10-01'
endDate = '2020-10-10'
area = value
res = get_search_index(word, startDate, endDate, area)
result = res.split(',')
dates = get_date_list(startDate, endDate)
for num, date in zip(result, dates):
print(areas[value], num, date)
with open('area.csv', 'a+', encoding='utf-8') as f:
f.write(areas[value] + ',' + str(num) + ',' + date + '\n')
except:
pass
def get_word():
words = ['诸葛大力', '张伟', '胡一菲', '吕子乔', '陈美嘉', '赵海棠', '咖喱酱', '曾小贤', '秦羽墨']
for word in words:
try:
time.sleep(2)
startDate = '2020-10-01'
endDate = '2020-10-10'
area = 0
res = get_search_index(word, startDate, endDate, area)
result = res.split(',')
dates = get_date_list(startDate, endDate)
for num, date in zip(result, dates):
print(word, num, date)
with open('word.csv', 'a+', encoding='utf-8') as f:
f.write(word + ',' + str(num) + ',' + date + '\n')
except:
pass
get_area()
get_word()
得到的CSV文件结果如下,有两种形式的数据。
一种是多个关键词每日指数数据,另一种是一个关键词各省市每日指数数据。
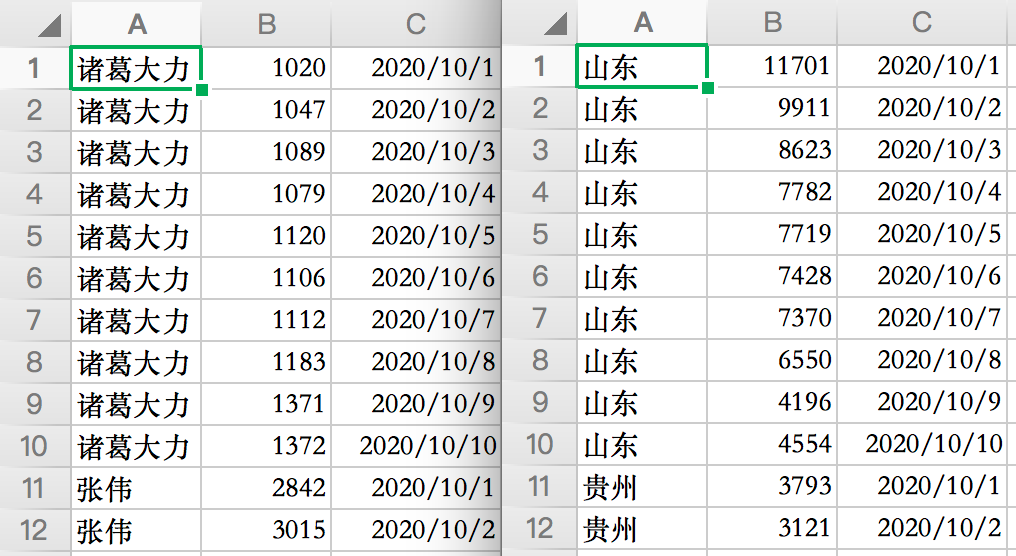
有了数据就可以用Python制作动图啦。
import pandas as pd
import bar_chart_race as bcr
# 读取数据
# df = pd.read_csv('word.csv', encoding='utf-8', header=None, names=['name', 'number', 'day'])
df = pd.read_csv('area.csv', encoding='utf-8', header=None, names=['name', 'number', 'day'])
# 数据处理,数据透视表
df_result = pd.pivot_table(df, values='number', index=['day'], columns=['name'], fill_value=0)
# 生成GIF
# bcr.bar_chart_race(df_result, filename='word.gif', title='爱情公寓5演职人员热度排行')
bcr.bar_chart_race(df_result, filename='area.gif', title='国内各省市王者荣耀热度排行')
5行Python代码,来看一下效果如何。
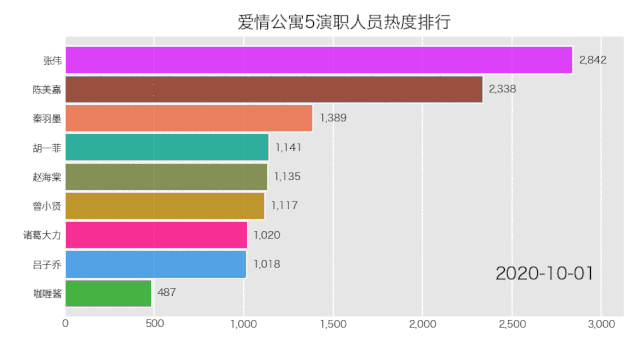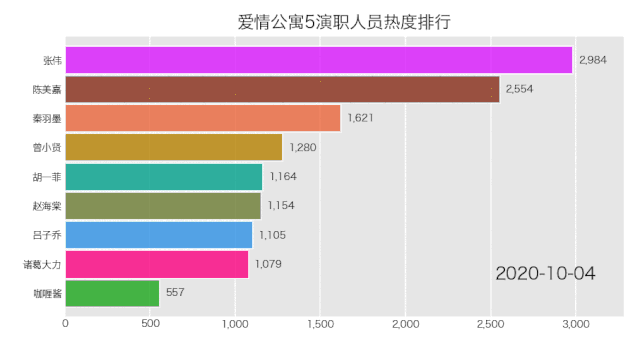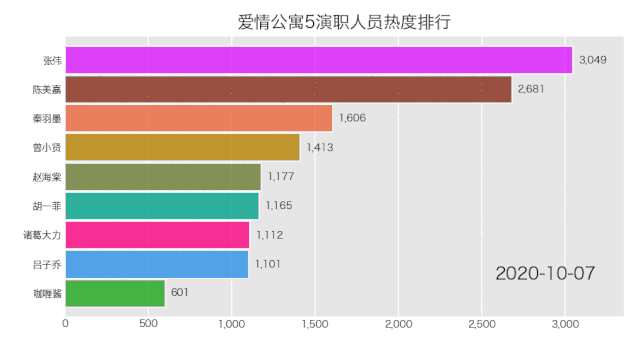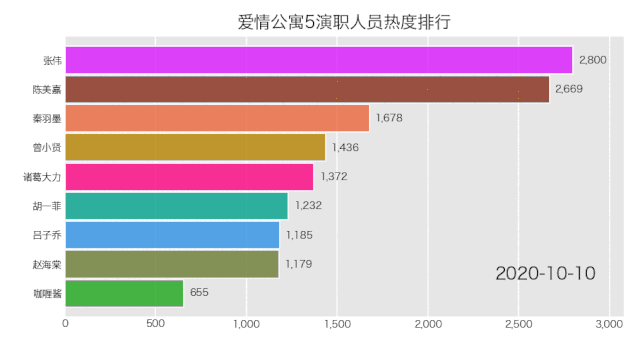
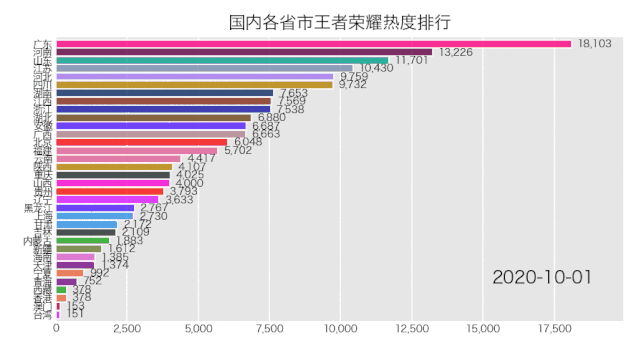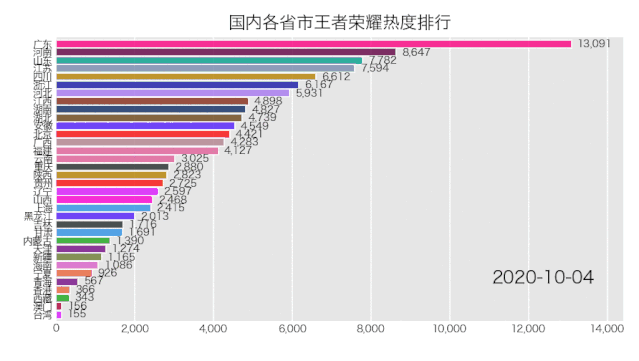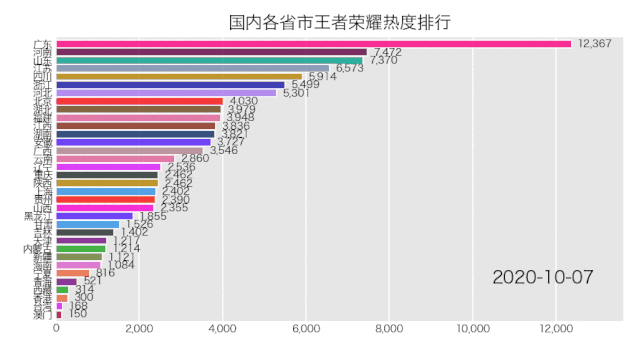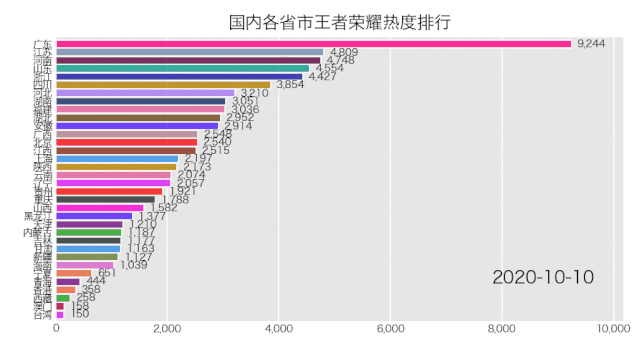
是成功实现了,就是配色有那么点渣,这个可自行修改颜色配置文件,让你的动图变得好看。
02. 微博指数
百度搜索新浪的微博指数,打开网站一看,发现网页版无法使用。

此时我们只需打开开发者工具,将你的浏览器模拟为手机端,刷新网页即可。
可以看到,微指数的界面出来了。
添加关键词,查看指数的数据接口。
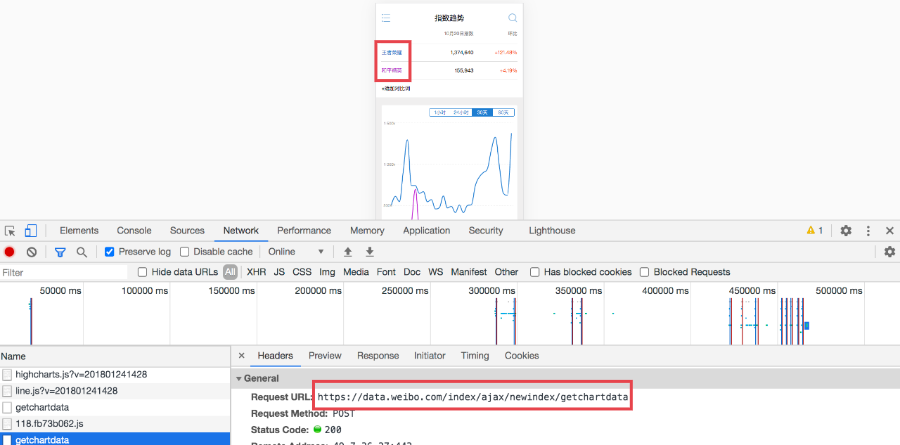
请求是Post方法,并且不需要登陆微博账号。
import re
import time
import json
import requests
import datetime
# 请求头信息
headers = """accept: application/json
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
content-length: 50
content-type: application/x-www-form-urlencoded
cookie: '你的cookie'
origin: https://data.weibo.com
referer: https://data.weibo.com/index/newindex?visit_type=trend&wid=1011224685661
sec-fetch-mode: cors
sec-fetch-site: same-origin
user-agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
x-requested-with: XMLHttpRequest"""
# 将请求头字符串转化为字典
headers = dict([line.split(": ",1) for line in headers.split("\n")])
print(headers)
# 数据接口
url = 'https://data.weibo.com/index/ajax/newindex/getchartdata'
# 获取时间列表
def get_date_list(begin_date, end_date):
dates = []
dt = datetime.datetime.strptime(begin_date, "%Y-%m-%d")
date = begin_date[:]
while date <= end_date:
dates.append(date)
dt += datetime.timedelta(days=1)
date = dt.strftime("%Y-%m-%d")
return dates
# 相关信息
names = ['汤唯', '朱亚文', '邓家佳', '乔振宇', '王学圻', '张艺兴', '俞灏明', '吴越', '梁冠华', '李昕亮', '苏可', '孙骁骁', '赵韩樱子', '孙耀琦', '魏巍']
# 获取微指数数据
for name in names:
try:
# 获取关键词ID
url_id = 'https://data.weibo.com/index/ajax/newindex/searchword'
data_id = {
'word': name
}
html_id = requests.post(url=url_id, data=data_id, headers=headers)
pattern = re.compile(r'li wid=\\\"(.*?)\\\" word')
id = pattern.findall(html_id.text)[0]
# 接口参数
data = {
'wid': id,
'dateGroup': '1month'
}
time.sleep(2)
# 请求数据
html = requests.post(url=url, data=data, headers=headers)
result = json.loads(html.text)
# 处理数据
if result['data']:
values = result['data'][0]['trend']['s']
startDate = '2019-01-01'
endDate = '2020-01-01'
dates = result['data'][0]['trend']['x']
# 保存数据
for value, date in zip(values, dates):
print(name, value, date)
with open('weibo.csv', 'a+', encoding='utf-8') as f:
f.write(name + ',' + str(value) + ',' + date + '\n')
except:
pass
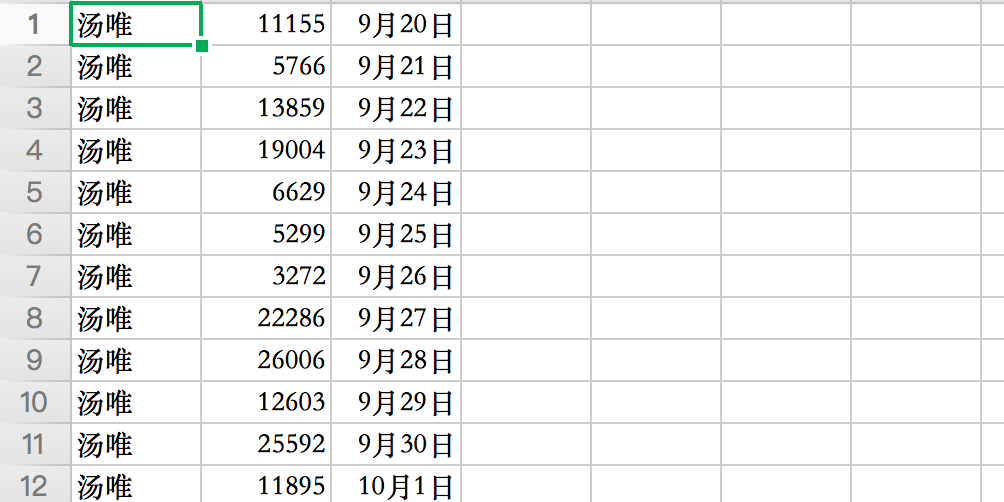
获取到的信息如下。
也来生成一个动态图表。
import pandas as pd
import bar_chart_race as bcr
# 读取数据
df = pd.read_csv('weibo.csv', encoding='utf-8', header=None, names=['name', 'number', 'day'])
# 数据处理,数据透视表
df_result = pd.pivot_table(df, values='number', index=['day'], columns=['name'], fill_value=0)
# print(df_result[:10])
# 生成GIF
bcr.bar_chart_race(df_result[:10], filename='weibo.gif', title='大明风华演职人员热度排行')
得到结果如下。
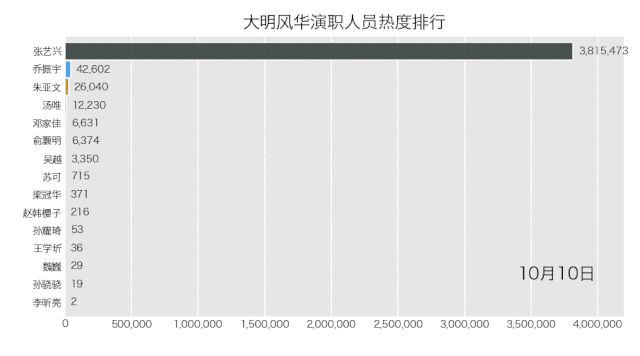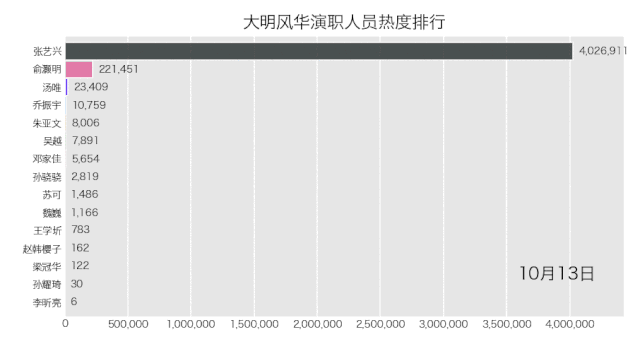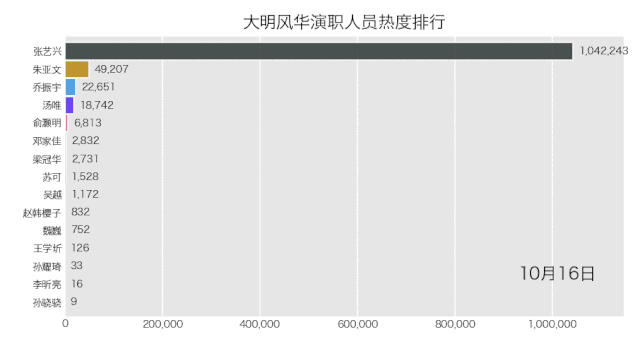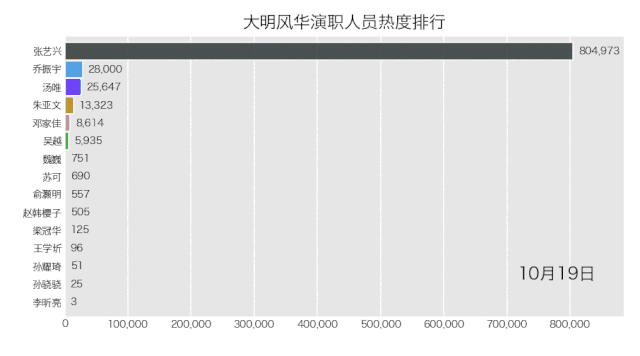
是不是也不难?
相关代码我已上传公众号,回复「指数」即可获取。
万水千山总是情,点个 ? 行不行。
-END-
添加早小起微信,备注进群进入技术交流群