
【机器学习】异常检测算法之(HBOS)-Histogram-based Outlier Score
HBOS全名为:Histogram-based Outlier Score。它是一种单变量方法的组合,不能对特征之间的依赖关系进行建模,但是计算速度较快,对大数据集友好,其基本假设是数据集的每个维度相互独立,然后对每个维度进行区间(bin)划分,区间的密度越高,异常评分越低。理解了这句话,基本就理解了这个算法。下面我专门画了两个图来解释这句话。
1、静态宽度直方图
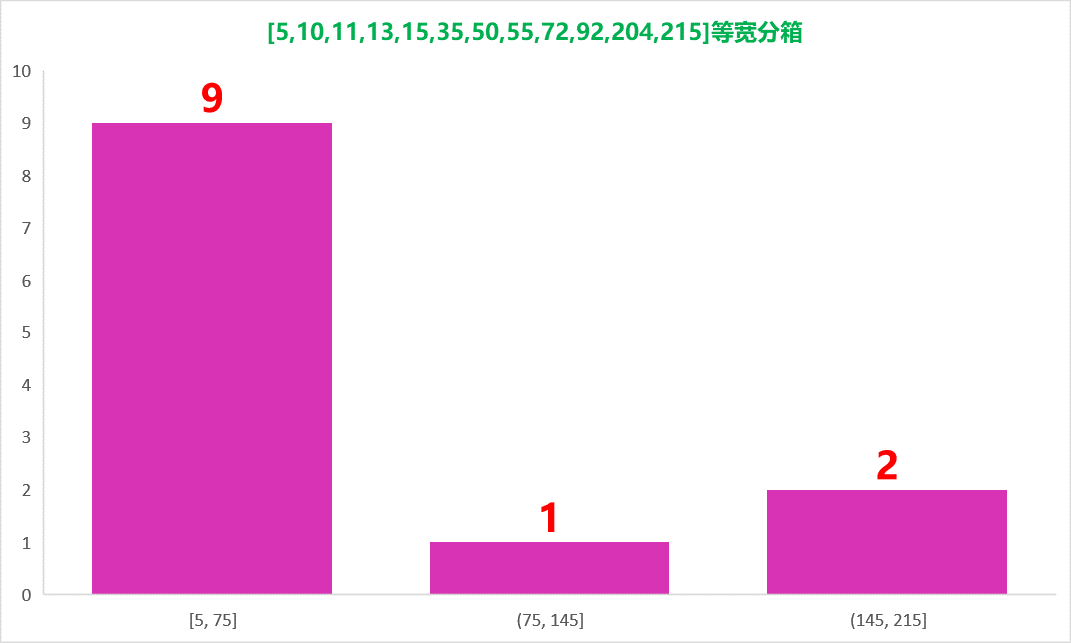

2、动态宽度直方图
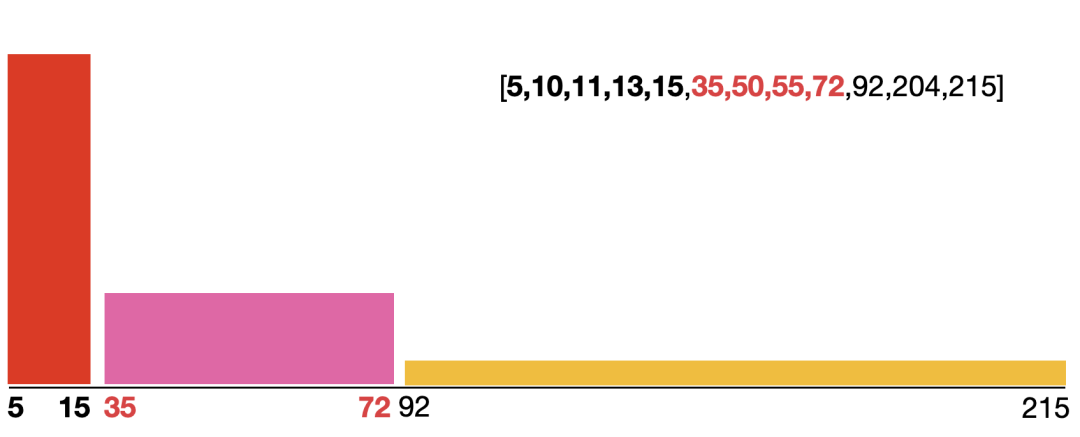
二、算法推导过程
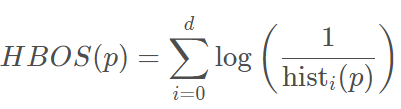
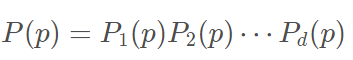
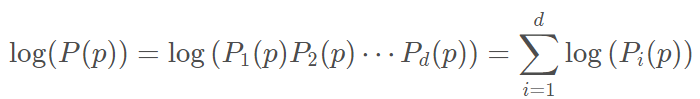
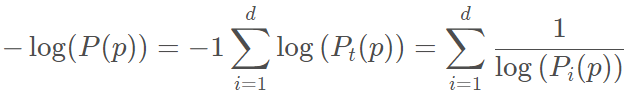

PyOD是一个可扩展的Python工具包,用于检测多变量数据中的异常值。它可以在一个详细记录API下访问大约20个离群值检测算法。
三、应用案例详解
1、基本用法
from pyod.models.hbosHBOSHBOS(n_bins=10,alpha=0.1,tol=0.5,contamination=0.1)
2、模型参数
#导入包from pyod.utils.data import generate_data,evaluate_print# 样本的生成X_train, y_train, X_test, y_test = generate_data(n_train=200, n_test=100, contamination=0.1)X_train.shape(200, 2)X_test.shape(100, 2)from pyod.models import hbosfrom pyod.utils.example import visualize# 模型训练clf = hbos.HBOS()clf.fit(X_train)y_train_pred = clf.labels_y_train_socres = clf.decision_scores_#返回未知数据上的分类标签 (0: 正常值, 1: 异常值)y_test_pred = clf.predict(X_test)# 返回未知数据上的异常值 (分值越大越异常)y_test_scores = clf.decision_function(X_test)print(y_test_pred)array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])print(y_test_scores)array([1.94607743, 1.94607743, 1.94607743, 3.18758465, 2.99449223,1.94607743, 3.18758465, 2.99449223, 1.94607743, 3.18758465,1.94607743, 1.94607743, 3.18758465, 1.94607743, 1.94607743,1.94607743, 3.18758465, 1.94607743, 2.99449223, 1.94607743,1.94607743, 1.94607743, 1.94607743, 3.18758465, 3.18758465,2.99449223, 1.94607743, 1.94607743, 1.94607743, 3.18758465,1.94607743, 2.99449223, 1.94607743, 1.94607743, 1.94607743,1.94607743, 2.99449223, 1.94607743, 1.94607743, 1.94607743,1.94607743, 1.94607743, 3.18758465, 1.94607743, 1.94607743,2.99449223, 2.99449223, 3.18758465, 2.99449223, 1.94607743,1.94607743, 1.94607743, 1.94607743, 1.94607743, 3.18758465,1.94607743, 3.18758465, 3.18758465, 1.94607743, 1.94607743,1.94607743, 2.99449223, 3.18758465, 2.99449223, 1.94607743,1.94607743, 3.18758465, 1.94607743, 1.94607743, 1.94607743,1.94607743, 1.94607743, 1.94607743, 2.99449223, 1.94607743,2.99449223, 1.94607743, 3.18758465, 3.18758465, 1.94607743,2.99449223, 2.99449223, 1.94607743, 1.94607743, 1.94607743,1.94607743, 2.99449223, 1.94607743, 3.18758465, 1.94607743,6.36222028, 6.47923046, 6.5608128 , 6.52101746, 6.36222028,6.52015473, 6.44010653, 5.30002108, 6.47923046, 6.51944504])# 模型评估clf_name = 'HBOS'evaluate_print(clf_name, y_test, y_test_scores)HBOS ROC:1.0, precision @ rank n:1.0# 模型可视化visualize(clf_name,X_train, y_train,X_test, y_test,y_train_pred,y_test_pred,show_figure=True,save_figure=False)
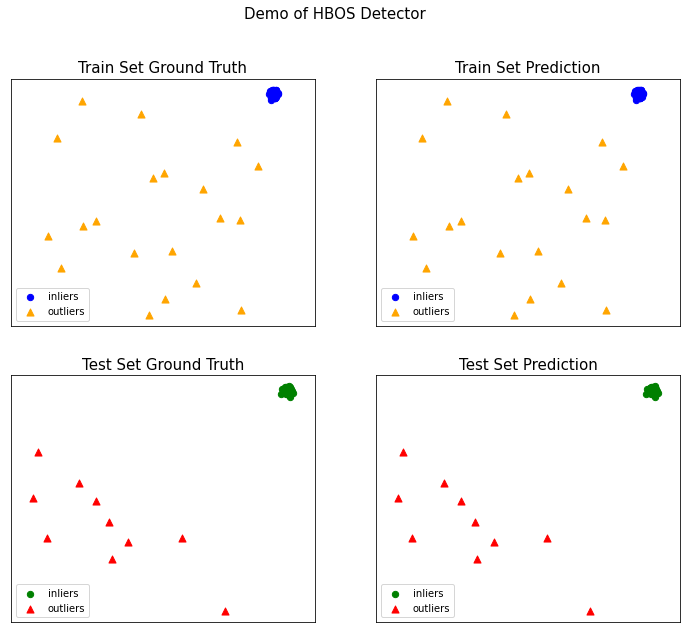
四、总 结
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码:
评论