
23个优秀的机器学习训练公开数据集
本文最初发布于 rubikscode.com 网站,经原作者授权由 InfoQ 中文站翻译并分享。
Iris 数据集的那些示例你是不是已经用腻了呢?不要误会我的意思,Iris 数据集作为入门用途来说是很不错的,但其实网络上还有很多有趣的公开数据集可以用来练习机器学习和深度学习。在这篇文章中,我会分享 23 个优秀的公开数据集,除了介绍数据集和数据示例外,我还会介绍这些数据集各自可以解决哪些问题。
以下是这 23 个公共数据集:
帕尔默企鹅数据集
共享单车需求数据集
葡萄酒分类数据集
波士顿住房数据集
电离层数据集
Fashion MNIST 数据集
猫与狗数据集
威斯康星州乳腺癌(诊断)数据集
Twitter 情绪分析和 Sentiment140 数据集
BBC 新闻数据集
垃圾短信分类器数据集
CelebA 数据集
YouTube-8M 数据集
亚马逊评论数据集
纸币验证数据集
LabelMe 数据集
声纳数据集
皮马印第安人糖尿病数据集
小麦种子数据集
Jeopardy! 数据集
鲍鱼数据集
假新闻检测数据集
ImageNet 数据集
这是迄今为止我最喜欢的数据集。我在最近写的书里的大多数示例都来自于它。简单来说,如果你在 Iris 数据集上做实验做腻了就可以尝试一下这一个。它由 Kristen Gorman 博士和南极洲 LTER 的帕尔默科考站共同创建。该数据集本质上是由两个数据集组成的,每个数据集包含 344 只企鹅的数据。
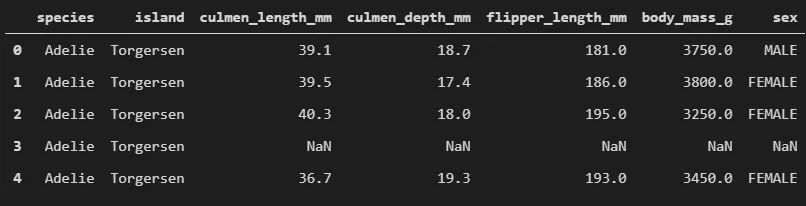
就像 Iris 一样,这个数据集里有来自帕尔默群岛 3 个岛屿的 3 种不同种类的企鹅,分别是 Adelie、Chinstrap 和 Gentoo。或许“Gentoo”听起来很耳熟,那是因为 Gentoo Linux 就是以它命名的!此外,这些数据集包含每个物种的 culmen 维度。这里 culmen 是鸟喙的上脊。在简化的企鹅数据中,culmen 长度和深度被重命名为变量 culmen_length_mm 和 culmen_depth_mm。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\penguins_size.csv")
data.head()
我们使用 Pandas 库来做数据可视化,并且加载的是一个更简单的数据集。
它是练习解决分类和聚类问题的好帮手。在这里,你可以尝试各种分类算法,如决策树、随机森林、SVM,或把它用于聚类问题并练习使用无监督学习。
在以下链接中可以获得有关 PalmerPenguins 数据集的更多信息:
介绍 (https://allisonhorst.github.io/palmerpenguins/articles/intro.html)
GitHub(https://github.com/allisonhorst/palmerpenguins)
Kaggle(https://www.kaggle.com/parulpandey/palmer-archipelago-antarctica-penguin-data)
这个数据集非常有趣。它对于初学者来说有点复杂,但也正因如此,它很适合拿来做练习。它包含了华盛顿特区“首都自行车共享计划”中自行车租赁需求的数据,自行车共享和租赁系统通常是很好的信息来源。这个数据集包含了有关骑行持续时间、出发地点、到达地点和经过时间的信息,还包含了每一天每小时的天气信息。

我们加载数据,看看它是什么样的。首先,我们使用数据集的每小时数据来执行操作:
data = pd.read_csv(f".\\Datasets\\hour.csv")
data.head()

每日数据是下面的样子:
data = pd.read_csv(f".\\Datasets\\day.csv")
data.head()

由于该数据集包含的信息种类繁多,因此非常适合练习解决回归问题。你可以尝试对其使用多元线性回归,或使用神经网络。
在以下链接中可以获得关于该数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/bike+sharing+dataset)
Kaggle(https://www.kaggle.com/c/bike-sharing-demand)
这是一个经典之作。如果你喜欢葡萄树或计划成为索马里人,肯定会更中意它的。该数据集由两个数据集组成。两者都包含来自葡萄牙 Vinho Verde 地区的葡萄酒的化学指标,一种用于红葡萄酒,另一种用于白葡萄酒。由于隐私限制,数据集里没有关于葡萄种类、葡萄酒品牌、葡萄酒售价的数据,但有关于葡萄酒质量的信息。

我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\winequality-white.csv")
data.head()

这是一个多类分类问题,但也可以被定义为回归问题。它的分类数据是不均衡的(例如,正常葡萄酒的数量比优质或差的葡萄酒多得多),很适合针对不均衡数据集的分类练习。除此之外,数据集中所有特征并不都是相关的,因此也可以拿来练习特征工程和特征选择。
以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://www.vinhoverde.pt/en/about-vinho-verde)
UCI(https://archive.ics.uci.edu/ml/datasets/Wine+Quality)
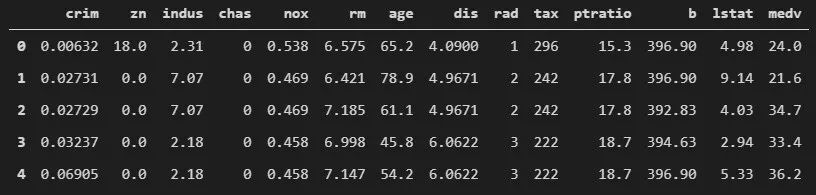
虽然我说过会尽量不推荐其他人都推荐的那种数据集,但这个数据集实在太经典了。许多教程、示例和书籍都使用过它。这个数据集由 14 个特征组成,包含美国人口普查局收集的关于马萨诸塞州波士顿地区住房的信息。这是一个只有 506 个样本的小数据集。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\boston_housing.csv")
data.head()
该数据集非常适合练习回归任务。请注意,因为这是一个小数据集,你可能会得到乐观的结果。
从以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://www.cs.toronto.edu/\~delve/data/boston/bostonDetail.html)
Kaggle(https://www.kaggle.com/c/boston-housing)
这也是一个经典数据集。它实际上起源于 1989 年,但它确实很有趣。该数据集包含由拉布拉多鹅湾的雷达系统收集的数据。该系统由 16 个高频天线的相控阵列组成,旨在检测电离层中的自由电子。一般来说,电离层有两种类型的结构:“好”和“坏”。这些雷达会检测这些结构并传递信号。数据集中有 34 个自变量和 1 个因变量,总共有 351 个观测值。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\ionsphere.csv")
data.head()
这显然是一个二元(2 类)分类问题。有趣的是,这是一个不均衡的数据集,所以你也可以用它做这种练习。在这个数据集上实现高精度也非易事,基线性能在 64% 左右,而最高精度在 94% 左右。
从以下链接中可以找到关于这个数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/Ionosphere)
MNIST 数据集是用于练习图像分类和图像识别的著名数据集,然而它有点被滥用了。如果你想要一个简单的数据集来练习图像分类,你可以试试 Fashion MNIST。它曾被《机器学习终极指南》拿来做图像分类示例。
本质上,这个数据集是 MNIST 数据集的变体,它与 MNIST 数据集具有相同的结构,也就是说它有一个 60,000 个样本的训练集和一个 10,000 个服装图像的测试集。所有图像都经过尺寸归一化和居中。图像的大小也固定为 28×28,这样预处理的图像数据被减到了最小水平。它也可作为某些框架(如 TensorFlow 或 PyTorch)的一部分使用。
我们加载数据,看看它是什么样的:

它最适合图像分类和图像生成任务。你可以使用简单的卷积神经网络(CNN)来做尝试,或者使用生成对抗网络(GAN)使用它来生成图像。
从以下链接中可以找到关于这个数据集的更多信息:
GitHub(https://github.com/zalandoresearch/fashion-mnist)
Kaggle(https://www.kaggle.com/zalando-research/fashionmnist)
这是一个包含猫狗图像的数据集。这个数据集包含 23,262 张猫和狗的图像,用于二值图像分类。在主文件夹中,你会找到两个文件夹 train1 和 test。
train1 文件夹包含训练图像,而 test 文件夹包含测试图像。请注意,图像名称以 cat 或 dog 开头。这些名称本质上是我们的标签,这意味着我们将使用这些名称定义目标。
我们加载数据,看看它是什么样的:

这个数据集有两重目标。首先,它可用于练习图像分类以及对象检测。其次,你可以在这里面找到无穷无尽的可爱图片。
以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://www.microsoft.com/en-us/download/details.aspx?id=54765)
Kaggle(https://www.kaggle.com/c/dogs-vs-cats)
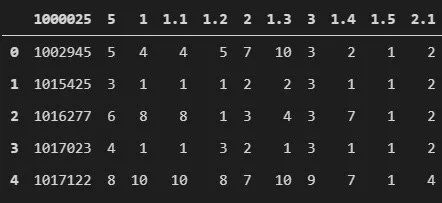
机器学习和深度学习技术在医疗保健领域中的应用正在稳步增长。如果你想练习并了解使用此类数据的效果,这个数据集是一个不错的选择。在该数据集中,数据是通过处理乳房肿块的细针穿刺(FNA)的数字化图像提取出来的。该数据集中的每个特征都描述了上述数字化图像中发现的细胞核的特征。
该数据集由 569 个样本组成,其中包括 357 个良性样本和 212 个恶性样本。这个数据集中有三类特征,其中实值特征最有趣。它们是从数字化图像中计算出来的,包含有关区域、细胞半径、纹理等信息。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\breast-cancer-wisconsin.csv")
data.head()
这个医疗保健数据集适合练习分类和随机森林、SVM 等算法。
从以下链接中可以找到关于这个数据集的更多信息:
Kaggle(https://www.kaggle.com/uciml/breast-cancer-wisconsin-data)
UCI(https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
在过去几年中,情绪分析成为了一种监控和了解客户反馈的重要工具。这种对消息和响应所携带的潜在情绪基调的检测过程是完全自动化的,这意味着企业可以更好更快地了解客户的需求并提供更好的产品和服务。
这一过程是通过应用各种 NLP(自然语言处理)技术来完成的。这些数据集可以帮助你练习此类技术,实际上非常适合该领域的初学者。Sentiment140 包含了使用 Twitter API 提取的 1,600,000 条推文。它们的结构略有不同。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\training.1600000.processed.noemoticon.csv")
data.head()
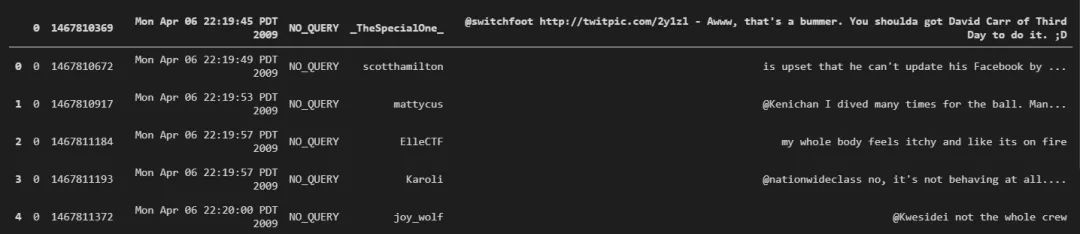
如前所述,这是一个用于情绪分析的数据集。情绪分析是最常见的文本分类工具。该过程会分析文本片段以确定其中包含的情绪是积极的、消极的还是中性的。了解品牌和产品引发的社会情绪是现代企业必不可少的工具之一。
从以下链接中可以找到关于这个数据集的更多信息:
Kaggle(https://www.kaggle.com/c/twitter-sentiment-analysis2)
Kaggle(https://www.kaggle.com/kazanova/sentiment140)
我们再来看这个类别中另一个有趣的文本数据集。该数据集来自 BBC 新闻。它由 2225 篇文章组成,每篇文章都有标签。所有文章分成 5 个类别:科技、商业、政治、娱乐和体育。这个数据集没有失衡,每个类别中的文章数量都是差不多的。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\BBC News Train.csv")
data.head()

自然,这个数据集最适合用于文本分类练习。你也可以更进一步,练习分析每篇文章的情绪。总的来说,它适用于各种 NLP 任务和实践。
从以下链接中可以找到关于这个数据集的更多信息:
Kaggle(https://www.kaggle.com/c/learn-ai-bbc)
垃圾消息检测是互联网中最早投入实践的机器学习任务之一。这种任务也属于 NLP 和文本分类工作。所以,如果你想练习解决这类问题,Spam SMS 数据集是一个不错的选择。它在实践中用得非常多,非常适合初学者。
这个数据集最棒的一点是,它是从互联网的多个来源构建的。例如,它从 Grumbletext 网站上提取了 425 条垃圾短信,从新加坡国立大学的 NUS SMS Corpus(NSC)随机选择了 3,375 条短信,还有 450 条短信来自 Caroline Tag 的博士论文等。数据集本身由两列组成:标签(ham 或 spam)和原始文本。
我们加载数据,看看它是什么样的:
ham What you doing?how are you?
ham Ok lar... Joking wif u oni...
ham dun say so early hor... U c already then say...
ham MY NO. IN LUTON 0125698789 RING ME IF UR AROUND! H*
ham Siva is in hostel aha:-.
ham Cos i was out shopping wif darren jus now n i called him 2 ask wat present he wan lor. Then he started guessing who i was wif n he finally guessed darren lor.
spam FreeMsg: Txt: CALL to No: 86888 & claim your reward of 3 hours talk time to use from your phone now! ubscribe6GBP/ mnth inc 3hrs 16 stop?txtStop
spam Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ to 82277. B
spam URGENT! Your Mobile No 07808726822 was awarded a L2,000 Bonus Caller Prize on 02/09/03! This is our 2nd attempt to contact YOU! Call 0871-872-9758 BOX95QU
顾名思义,该数据集最适合用于垃圾邮件检测和文本分类。它也经常用在工作面试中,所以大家最好练习一下。
从以下链接中可以找到关于这个数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/sms+spam+collection)
Kaggle(https://www.kaggle.com/uciml/sms-spam-collection-dataset)
如果你想研究人脸检测解决方案、构建自己的人脸生成器或创建深度人脸伪造模型,那么这个数据集就是你的最佳选择。该数据集拥有超过 20 万张名人图像,每张图像有 40 个属性注释,为你的研究项目提供了一个很好的起点。此外,它还涵盖了主要的姿势和背景类别。
我们加载数据,看看它是什么样的:

我们可以用这个数据集解决多种问题。比如,我们可以解决各种人脸识别和计算机视觉问题,它可用来使用不同的生成算法生成图像。此外,你可以使用它来开发新颖的深度人脸伪造模型或深度伪造检测模型。
从以下链接中可以找到关于这个数据集的更多信息:
介绍 (http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
这是最大的多标签视频分类数据集。它来自谷歌,拥有 800 万个带有注释和 ID 的 YouTube 分类视频。这些视频的注释由 YouTube 视频注释系统使用 48000 个视觉实体的词汇表创建。该词汇表也可供下载。
请注意,此数据集可用作 TensorFlow 记录文件。除此之外,你还可以使用这个数据集的扩展——YouTube-8M Segments 数据集。它包含了人工验证的分段注释。
你可以使用以下命令下载它们:
mkdir -p ~/yt8m/2/frame/train
cd ~/yt8m/2/frame/train
curl data.yt8m.org/download.py | partition=2/frame/train mirror=us python
你可以使用这个数据集执行多种操作。比如可以使用它跟进谷歌的竞赛,并开发准确分配视频级标签的分类算法。你还可以用它来创建视频分类模型,也可以用它练习所谓的时间概念定位,也就是找到并分享特定的视频瞬间。
从以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://arxiv.org/abs/1609.08675)
下载 (http://research.google.com/youtube8m/)
情绪分析是最常见的文本分类工具。这个过程会分析文本片段以确定情绪倾向是积极的、消极的还是中性的。在监控在线会话时了解你的品牌、产品或服务引发的社会情绪是现代商业活动的基本工具之一,而情绪分析是实现这一目标的第一步。该数据集包含了来自亚马逊的产品评论和元数据,包括 1996 年 5 月至 2018 年 10 月的 2.331 亿条评论。
这个数据集可以为任何产品创建情绪分析的入门模型,你可以使用它来快速创建可用于生产的模型。
从以下链接中可以找到关于这个数据集的更多信息:
介绍和下载 (https://jmcauley.ucsd.edu/data/amazon/)
这是一个有趣的数据集。你可以使用它来创建可以检测真钞和伪造钞票的解决方案。该数据集包含了从数字化图像中提取的许多指标。数据集的图像是使用通常用于印刷检查的工业相机创建的,图像尺寸为 400x400 像素。这是一个干净的数据集,包含 1372 个示例且没有缺失值。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\data_banknote_authentication.csv")
data.head()
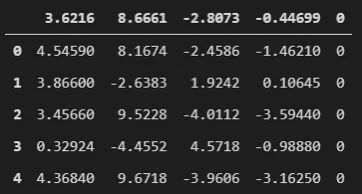
它是练习二元分类和应用各种算法的绝佳数据集。此外,你可以修改它并将其用于聚类,并提出将通过无监督学习对这些数据进行聚类的算法。
从以下链接中可以找到关于这个数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/banknote+authentication#)
Kaggle(https://www.kaggle.com/ritesaluja/bank-note-authentication-uci-data)
LabelMe 是另一个计算机视觉数据集。LabelMe 是一个带有真实标签的大型图像数据库,用于物体检测和识别。它的注释来自两个不同的来源,其中就有 LabelMe 在线注释工具。
简而言之,有两种方法可以利用这个数据集。你可以通过 LabelMe Matlab 工具箱下载所有图像,也可以通过 LabelMe Matlab 工具箱在线使用图像。
标记好的数据如下所示:

它是用于对象检测和对象识别解决方案的绝佳数据集。
从以下链接中可以找到关于这个数据集的更多信息:
介绍和下载 (http://labelme.csail.mit.edu/Release3.0/index.php)
如果你对地质学感兴趣,会发现这个数据集非常有趣。它是利用声纳信号制成的,由两部分组成。第一部分名为“sonar.mines”,包含 111 个模式,这些模式是使用在不同角度和不同条件下从金属圆柱体反射的声纳信号制成的。
第二部分名为“sonar.rocks”,由 97 个模式组成,同样是通过反射声纳信号制成,但这次反射的是岩石上的信号。它是一个不均衡数据集,包含 208 个示例、60 个输入特征和一个输出特征。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\sonar.csv")
data.head()

该数据集非常适合练习二元分类。它的制作目标是检测输入是地雷还是岩石,这是一个有趣的问题,因为最高的输出结果达到了 88% 的准确率。
从以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://www.is.umk.pl/projects/datasets.html#Sonar)
UCI(https://archive.ics.uci.edu/ml/datasets/Connectionist+Bench+(Sonar,+Mines+vs.+Rocks))
这是另一个用于分类练习的医疗保健数据集。它来自美国国家糖尿病、消化和肾脏疾病研究所,其目的是根据某些诊断指标来预测患者是否患有糖尿病。
该数据集包含 768 个观测值,具有 8 个输入特征和 1 个输出特征。它不是一个均衡的数据集,并且假设缺失值被替换为 0。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\pima-indians-dataset.csv")
data.head()
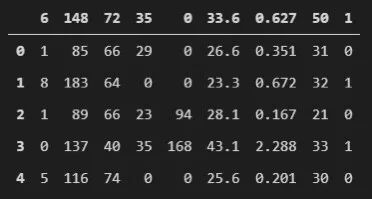
它是另一个适合练习二元分类的数据集。
从以下链接中可以找到关于这个数据集的更多信息:
介绍 (https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.names)
Kaggle(https://www.kaggle.com/uciml/pima-indians-diabetes-database)
这个数据集非常有趣和简单。它特别适合初学者,可以代替 Iris 数据集。该数据集包含属于三种不同小麦品种的种子信息:Kama、Rosa 和 Canadian。它是一个均衡的数据集,每个类别有 70 个实例。种子内部内核结构的测量值是使用软 X 射线技术检测的。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\seeds_dataset.csv")
data.head()
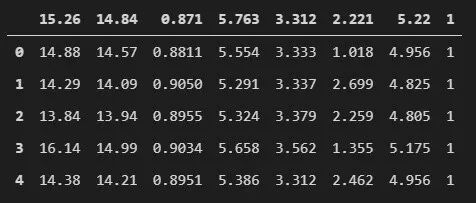
这个数据集有利于提升分类技能。
从以下链接中可以找到关于这个数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/seeds)
Kaggle(https://www.kaggle.com/jmcaro/wheat-seedsuci)
这个数据集很不错,包含 216,930 个 Jeopardy 问题、答案和其他数据。它是可用于你 NLP 项目的绝佳数据集。除了问题和答案,该数据集还包含有关问题类别和价值的信息。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\joepardy.csv")
data.head()

这是一个丰富的数据集,可用于多种用途。你可以运行分类算法并预测问题的类别或问题的价值。不过你可以用它做的最酷的事情可能是用它来训练 BERT 模型。
从以下链接中可以找到关于这个数据集的更多信息:
Kaggle(https://www.kaggle.com/tunguz/200000-jeopardy-questions)
从本质上讲这是一个多分类问题,然而,这个数据集也可以被视为一个回归问题。它的目标是使用提供的指标来预测鲍鱼的年龄。这个数据集不均衡,4,177 个实例有 8 个输入变量和 1 个输出变量。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\abalone.csv")
data.head()
该数据集可以同时构建为回归和分类任务。这是一个很好的机会,可以使用多元线性回归、SVM、随机森林等算法,或者构建一个可以解决这个问题的神经网络。
从以下链接中可以找到关于这个数据集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/abalone)
Kaggle(https://www.kaggle.com/rodolfomendes/abalone-dataset)
我们生活在一个狂野的时代。假新闻、深度造假和其他类型的欺骗技术都成了我们日常生活的一部分,无论我们喜欢与否。这个数据集提供了另一个非常适合练习的 NLP 任务。它包含标记过的真实和虚假新闻,以及它们的文本和作者。
我们加载数据,看看它是什么样的:
data = pd.read_csv(f".\\Datasets\\fake_news\\train.csv")
data.head()

这是另一个 NLP 文本分类任务。
从以下链接中可以找到关于这个数据集的更多信息:
Kaggle(https://www.kaggle.com/c/fake-news/overview)
最后这个数据集是计算机视觉数据集中的王者——ImageNet。该数据集是用来衡量所有新的深度学习和计算机视觉技术创新的基准。没有它,深度学习的世界就不会变成今天这样的状态。ImageNet 是一个按照 WordNet 层次结构组织的大型图像数据库。这意味着每个实体都用一组称为 -synset 的词和短语来描述。每个同义词集分配了大约 1000 个图像。基本上,层次结构的每个节点都由成百上千的图像描述。

它是学术和研究界的标准数据集。它的主要任务是图像分类,但你也可以将其用于各种任务。
从以下链接中可以找到关于这个数据集的更多信息:
官方网站 (https://image-net.org/)
在本文中,我们探索了 23 个非常适合机器学习应用实践的数据集。感谢你的阅读!
Nikola M. Zivkovic 是下列书籍的作者:《机器学习终极指南》和《面向程序员的深度学习》。他喜欢分享知识,还是一位经验丰富的演讲者。他曾在许多聚会、会议上发表演讲,并在诺维萨德大学担任客座讲师。
原文链接:
https://rubikscode.net/2021/07/19/top-23-best-public-datasets-for-practicing-machine-learning
往期精彩: