
10张图让你彻底理解回调函数
不知你是不是也有这样的疑惑,我们为什么需要回调函数这个概念呢?直接调用函数不就可以了?回调函数到底有什么作用?程序员到底该如何理解回调函数?
这篇文章就来为你解答这些问题,读完这篇文章后你的武器库将新增一件功能强大的利器。
一切要从这样的需求说起
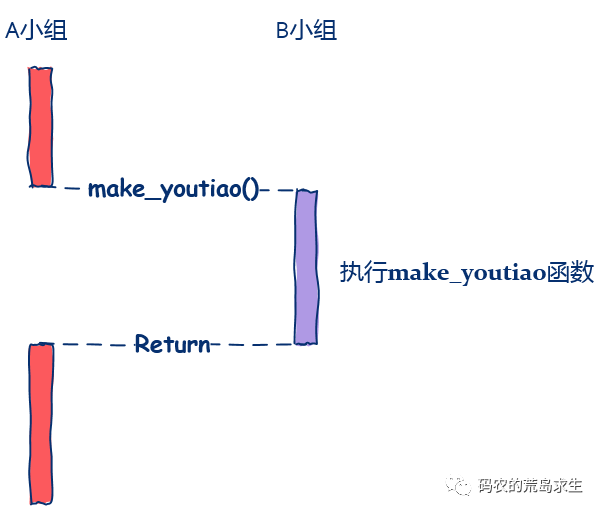
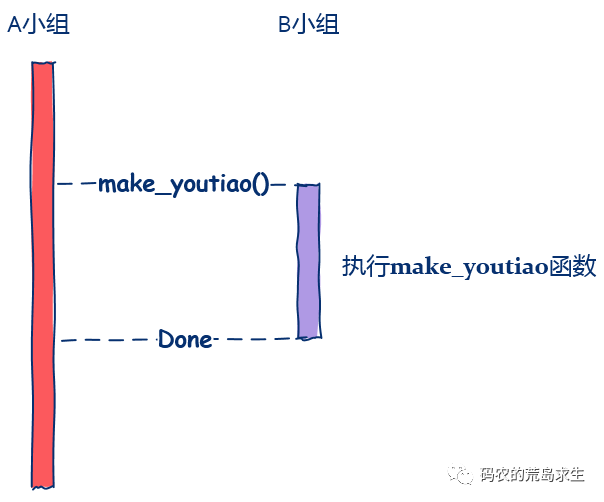
调用make_youtiao() 等待该函数执行完成 该函数执行完后继续后续流程
保存当前被执行函数的上下文 开始执行make_youtiao()这个函数 make_youtiao()执行完后,控制转回到调用函数中
现实并不容易
为什么我们需要回调callback
make_youtiao(10000);sell();
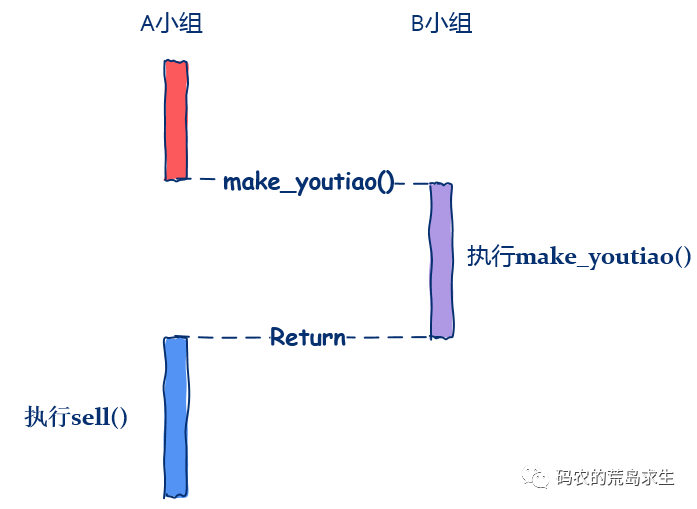
make_youtiao(10000, sell);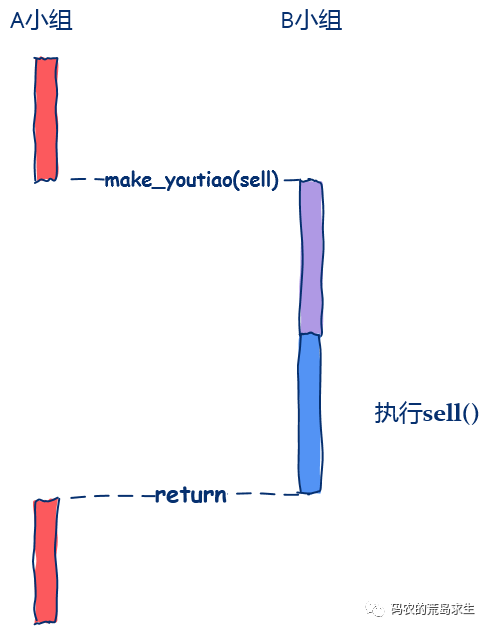
void make_youtiao(int num, func call_back) {// 制作油条call_back(); //执行回调}
void make_youtiao(int num) {real_make_youtiao(num);sell(); //执行回调}
void make_youtiao(int num) {real_make_youtiao(num);if (Team_B) {sell(); // 执行回调} else if (Team_D) {store(); // 放到仓库}}
异步回调
make_youtiao(10000, sell);// make_youtiao函数返回前什么都做不了
void make_youtiao(int num, func call_back) {real_make_youtiao(num);call_back(); //执行回调}
void make_youtiao(int num, func call_back) {// 在新的线程中执行处理逻辑create_thread(real_make_youtiao,num,call_back);}

make_youtiao(10000, sell);// 立刻返回// 执行后续流程
新的编程思维模式
调用某个函数,获取结果 处理获取到的结果
res = request();handle(res);
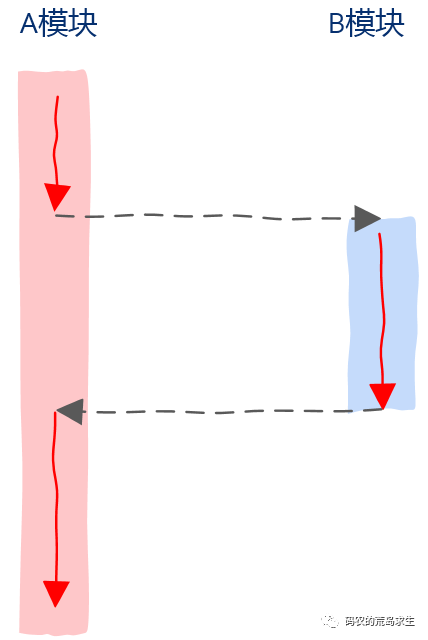
request(handle);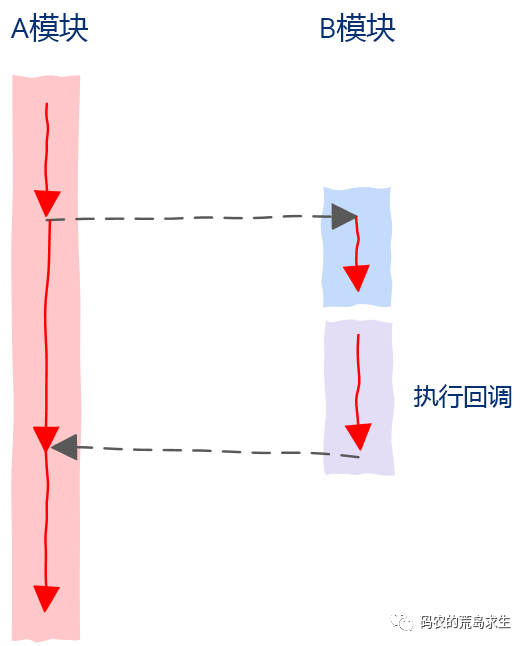
第一部分是我们来处理的,也就是调用request之前的部分 第二部分不是我们处理的,而是在其它线程、进程、甚至另一个机器上处理的。
正式定义
在计算机科学中,回调函数是指一段以参数的形式传递给其它代码的可执行代码。
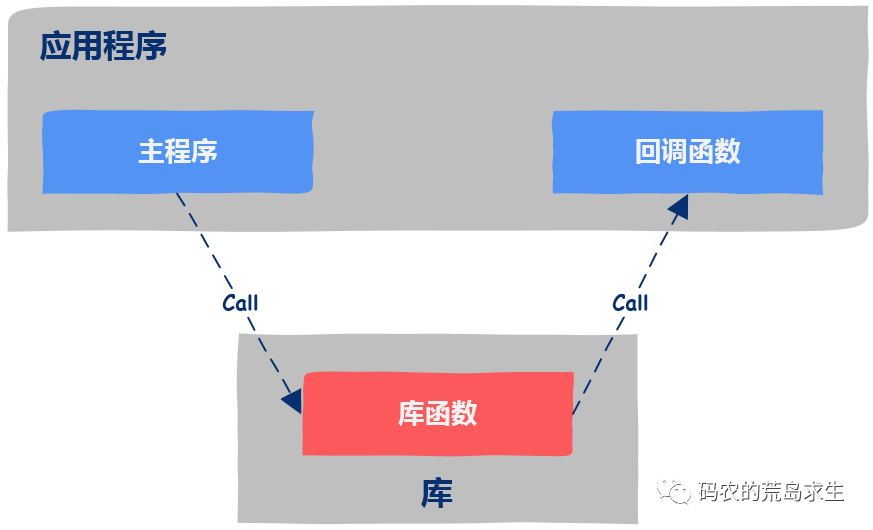
回调的类型
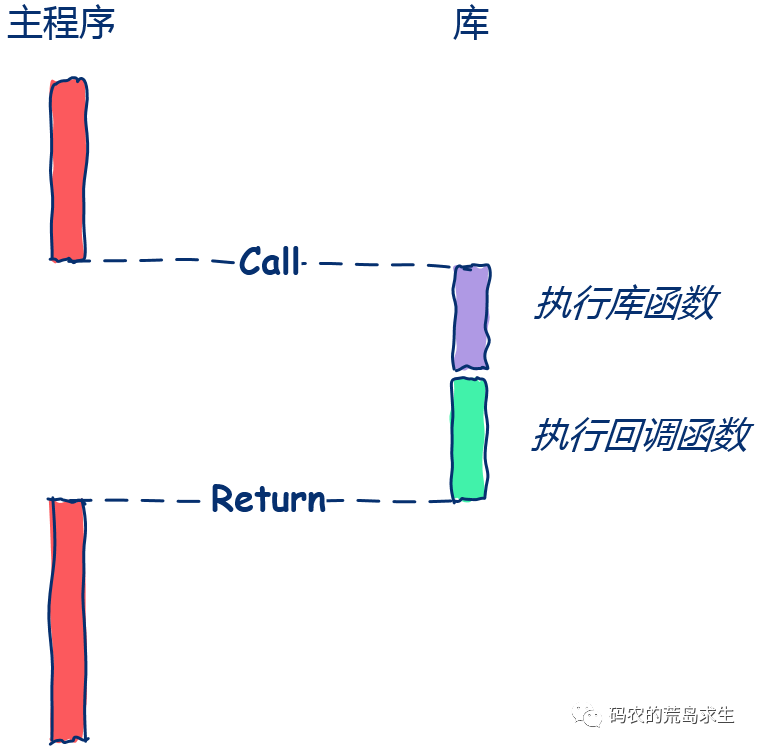
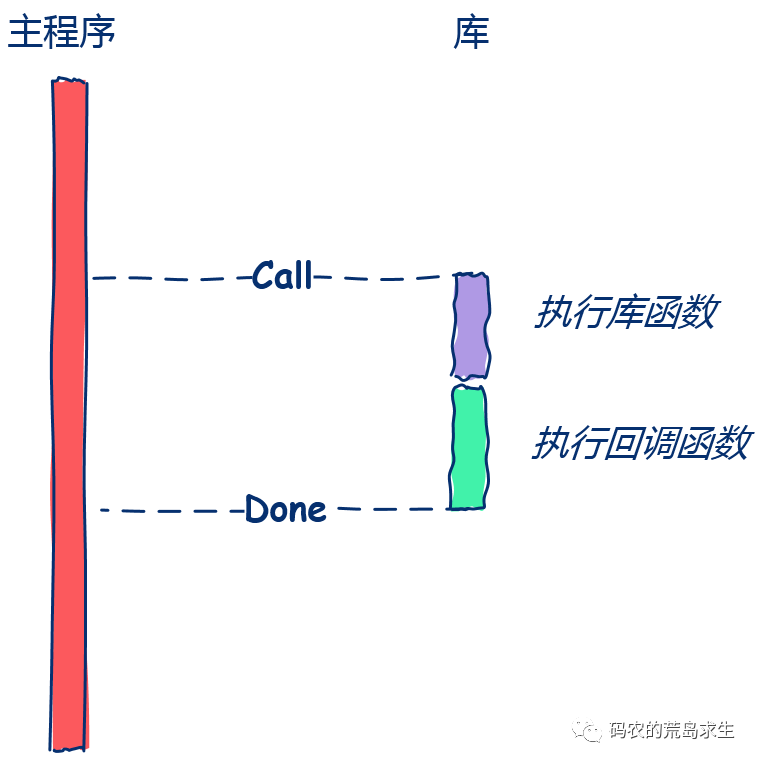
回调对应的编程思维模式
常规模式:调用完S服务后后我去执行X任务, 回调模式:调用完S服务后你接着再去执行X任务,
为什么异步回调越来越重要
回调地狱,callback hell
a = GetServiceA();b = GetServiceB(a);c = GetServiceC(b);d = GetServiceD(c);
GetServiceA(function(a){GetServiceB(a, function(b){GetServiceC(b, function(c){GetServiceD(c, function(d) {....});});});});
总结
·END·

评论