
和大家聊聊大数据的过去,现在和未来
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群
 相信身处于大数据领域的读者多少都能感受到,大数据技术的应用场景正在发生影响深远的变化: 随着实时计算、Kubernetes 的崛起和 HTAP、流批一体的大趋势,之前相对独立的大数据技术正逐渐和传统的在线业务融合。关于该话题,笔者早已如鲠在喉,但因拖延症又犯迟迟没有动笔,最终借最近参加多项会议收获不少感悟的契机才能克服懒惰写下这片文章。
相信身处于大数据领域的读者多少都能感受到,大数据技术的应用场景正在发生影响深远的变化: 随着实时计算、Kubernetes 的崛起和 HTAP、流批一体的大趋势,之前相对独立的大数据技术正逐渐和传统的在线业务融合。关于该话题,笔者早已如鲠在喉,但因拖延症又犯迟迟没有动笔,最终借最近参加多项会议收获不少感悟的契机才能克服懒惰写下这片文章。
本文旨在简单回顾大数据的历史,然后概括当前的主要发展趋势以及笔者的思考,最后不免主观地展望未来。
过去:先进与落后并存
大数据起源于 21 世纪初 Web 2.0[1] 带来的互联网爆发性增长,当时 Google、雅虎等头部公司的数据量级已经远超单机可处理,并且其中大部分数据是网页文本这样的非结构化、半结构化数据,用传统的数据库基本无法处理,因此开始探索新型的数据存储和计算技术。在 2003-2006 年里,Google 发布了内部研发成果的论文,即被称为 Google 三驾马车的 GFS、MapReduce 和 Bigtable 论文。在此期间,雅虎基于 GFS/MapReduce 论文建立了开源的 Hadoop 项目,奠定了后续十多年大数据发展的基础,也在同时大数据一词被广泛被用于描述这类数据量过大或过于复杂而无法通过传统单机技术处理的系统[2]。
然而,虽然以 MapReduce 作为代表的通用数据存储计算框架在搜索引擎场景获得巨大成功,但是在于之存在竞争关系的数据库社区看来,MapReduce 是一次巨大的倒退(”A major step backwards”)[3]。主要原因大致如下:
编程模型的巨大倒退,缺乏 schema 和高级数据访问语言 实现非常原始,基本是暴力遍历而不是使用索引 理念落后,是 25 年前的技术实现 缺少当时 DBMS 标配的大部分特性,比如事务、数据更新 与当时 DBMS 用户依赖的工具不兼容
在笔者看来,这篇论文直言不讳地指出了大数据系统的不足,时至今日仍非常有指导意义。而此后的十多年,也正是大数据系统逐渐完善弥补这些缺陷的过程,比如 Hive/Spark 填补了高级编程模型的空白,Parquet/ORC 等存储格式给文件添加了索引,如今的数据湖又在实现缺失的 ACID 事务特性。不过值得一提的是,这些批评是对于通用数据库场景而言,因为搜索引擎场景针对的是无结构化/非结构化数据,而且 Google 搜索本身就是一个巨大的倒排索引(因此无需额外索引)。
由于大数据系统特性上的种种不足和技术栈的独立性,大数据在过去的十多年中虽然发展迅猛,各种项目百花齐放,但应用场景仍很大程度上局限在数据仓库、机器学习等数据准确性要求没有那么高的场景下。其中很多项目也在设计之初就定位在某些细分应用场景而不是通用场景,比如 Hive 定位为数据仓库,Storm 定位为对于离线数据仓库的实时增量补充[5]。虽然这可以视为支持大数据量级而做的 trade-off,但客观上也造成了大数据生态圈的非常复杂,要完整地用好大数据,通常要引入至少十余个组件,无论对于大数据团队还是用户而言都有较高的门槛。
现在:百花齐放与融合统一
所谓天下大势分久必合,一方面大数据生态中各类组件独立的开发使用成本在业务稳定后已经成为不可小觑的开支,另一方面技术发展也使得不少组件有共享底层设施或技术栈的基础,因此 “融合” 将是当下最为明显的趋势,具体分为几个方向: 计算的流批一体、存储的流批一体、在离线服务混部、HTAP。
计算的流批一体
计算的流批一体指的是用同一套计算框架同时来实现流计算和批计算,目标是解决 Lambda 架构离线批处理和实时流处理两个不同编程模型的重复数据管道的问题。
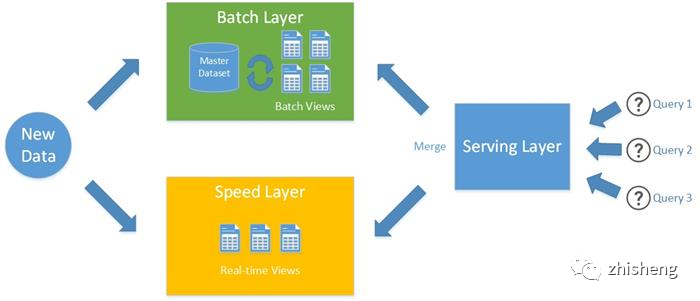
之所以会形成这样的架构,主要原因是实时流计算发展早期无法提供准确一次的语义(Exactly-Once Semantics),在出现异常重试或数据延迟的情况下很容易导致数据少算或多算,因此需要依赖成熟可靠的离线批计算来定时修正数据。两者在数据准确性上的差别主要来源于:离线批计算的数据是有界的(因此不用考虑数据是否完整)且允许较高延迟,因而几乎不需要在数据准确性和延迟间做 trade-off;而实时流计算非常依赖输入数据的低延迟,如果某个时间点产生的业务数据没有及时被处理,那么它很可能被错误地算入下个统计计算窗口,可能导致前后两个窗口的数据都不准确。
然而,2015 年 Google Dataflow Model 论文的发布[6]厘清了流处理和批处理的对立统一的关系,即批处理是流处理的特例,这为流批一体的大趋势奠定了基础。本文不打算过于深入 Dataflow Model 内容,简单来说,论文引入了对于流处理至关重要的两个概念:Watermark 和 Accumulation Mode(结果累积模式)。Watermark 由数据本身的业务时间提取而成(这被称为 Event Time 时间特性),表示对输入数据的业务时间的估计。依据 Watermark 而不是数据处理时间来触发计算,这样可以很大程度上解决流计算对延迟的依赖问题。另一方面,Accumulation Mode 定义了流计算不同执行产生的结果之间的关系,从而使得流计算可以先输出不完整的中间结果,然后再逐步修正,最终收敛至准确结果。
在开源界,最早采用流批一体计算模型的计算框架 Flink/Beam 等,在经过几年的迭代后流批一体已经逐渐达到生产可用,并陆续在前沿的公司落地。由于流批一体涉及到大量业务改造,在目前 Lambda 架构已经稳定运行多年的情况下,推动存量业务的改造的主要动力来源有:
降本增效。避免同时建设两套数据管道的机器和人力成本。
对齐口径。批处理的 schema 与流处理的 schema 可能存在不一致,比如同一个指标在批处理可能是天粒度,而流处理是分钟粒度。这样的不一致导致同时使用流和批的结果时容易出错。
值得注意的是,流批一体并不是将 Lambda 架构中的离线管道改为与实时管道相同的引擎,并与之前一样双跑,而是令作业可以灵活在两种模式上自由切换。通常来说,对延迟不敏感的业务可以用批的模式执行来提高资源利用率,而当业务变为延迟敏感时可以无缝切换为实时流处理模式。而在需要修正实时计算结果时,也可以直接采用 Kappa 架构[7]的方式复制一个作业以批模式来重刷部分数据。
存储的流批一体
众所周知,批处理中常读写文件系统,用文件作为存储抽象;而流处理中常读写消息队列,用队列作为存储抽象。在 Lambda 架构中,我们常常要将同时数据写入 HDFS、S3 等文件系统或对象存储供批处理使用,并写入 Kafka 等消息队列供流处理使用。尽管消息队列通过只保留最近一段时间的数据来减少数据存储成本,但这样两套系统的冗余仍造成很大的机器资源开销和人力资源成本。在计算的流批一体大趋势下,存储的流批一体的推进自然也是顺水推舟。
不过不同于计算有 Dataflow Model 这样能让业界达成 “批处理是流处理特例” 共识的重量级论文,存储的流批一体仍处在基于文件系统和基于消息队列两种流派不相伯仲的状况。基于文件来实现队列特性的代表是 Iceberg/Hudi/DeltaLake 等数据湖,而以队列来实现文件特性的代表是 Pulsar/Prevega 等新型消息队列系统。
在笔者看来,文件存储和队列存储经过一定的改进都可以满足流批一体的需求,比如 Pulsar 支持将数据归档到分级存储并可选择 Segment(文件) API 或 Message(队列) API 来读取,而 Iceberg 支持文件的批量读取或流式地监听文件。然而结合计算的流批一体而言,两者在写入更新 API 方面有根本的不同,并且该不同点进一步导致了两者的许多不同特性:
更新方式。虽然文件和队列在大数据场景下通常都是以 Append 方式写入,但文件支持对已经写入数据的更新,而队列则不允许直接更新,而是通过写入新数据加 Compact 删除旧数据的方式来间接更新。这意味着在批处理中读写队列或在流处理中读写文件都有一些不自然(下文会详细说明)。在数据湖等基于文件的存储中,流式读取通常以监听 Changelog 的方式实现;而在基于队列的存储中,批处理要重算更新结果,则无法直接删除或覆盖之前已经写入队列的结果,要么转为 Changelog 要么重建一个新队列。版本控制。由于更新方式的不同,文件中的数据是可变的,而队列中的数据是不可变的。文件表示某个时间点的状态,因此数据湖需要版本控制以增加回溯的功能;而相对地,队列则表示一段时间内状态变化的事件,本来有 Event Sourcing 的能力,因此不需要版本控制。并行写入。文件有唯一的写锁,只允许单个进程写入。数据湖通常以整个目录作为一个表暴露给用户,如果有多并行写入,则在该目录下为每个并行进程新增基于文件的快照进行隔离(MVCC)。而相对地,队列本来就支持并行写入,因此无需快照隔离。其实这个差异也是由于两者不同的更新方式导致的,因为队列 Append-Only 的方式保证了并发写入也不会导致数据丢失,而文件则不然。
通过上述的分析,相信不少读者已经隐约感觉到:基于文件的存储类似流表二象性中的表,适合用于保存可以被查询的可变状态(计算的最终结果或中间结果),而基于队列的存储类似表示流表二象性中的流,适合用于保存被流计算引擎读取的事件流(Changelog 数据)。
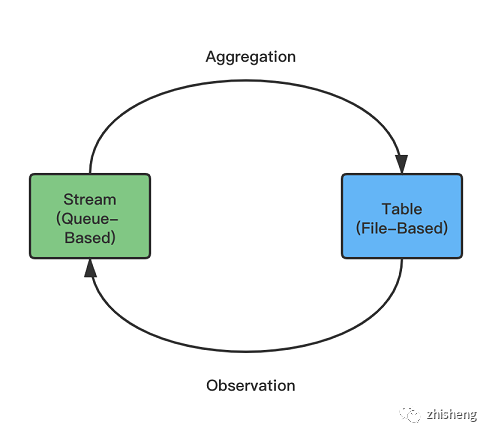
虽然流表二象性能使得两者可以交替使用,但若使用不当会导致数据在流表两种状态间进行不必要的转换,并给下游业务造成额外的麻烦。具体来讲,如果文件系统中存的是 Changelog 数据,那么下游进行流式读取(监听)时,读到的是 Changelog 的 Changelog,完全不合理。相对地,如果消息队列存的是非 Changelog 数据,那么该队列则丢失了更新的能力,任何更新都会导致消息不同版本的同时存在。由于目前 Changelog 类型一般由 CDC 或者流计算的聚合、Join 产生,还未推广到一般的 MQ 使用场景,所以后一种问题更常发生。但笔者认为,Changelog 是更加流原生的格式,未来大概会标准化并普及到队列存储中,目前非 Changelog 的数据则可以被看作是 Append-Only 业务的特例。
上述的结论可以被应用到当前热门的实时数仓建设中。除了 Lambda 架构,当前实时数仓架构主要有 Kappa 架构和实时 OLAP 变体两种[9],无论哪种通常都使用 Kafka/Pulsar 等 MQ 作为 ODS/DWD/DWS 等中间层的存储,OLAP 数据库或 OLTP 数据库作为 ADS 应用层的储存。这样的架构主要问题在于不够灵活,比如若想直接基于 DWD 层做一些 Ad-hoc 分析,那么常要将 DWD 层 MQ 中的数据再导出到数据库再做查询。
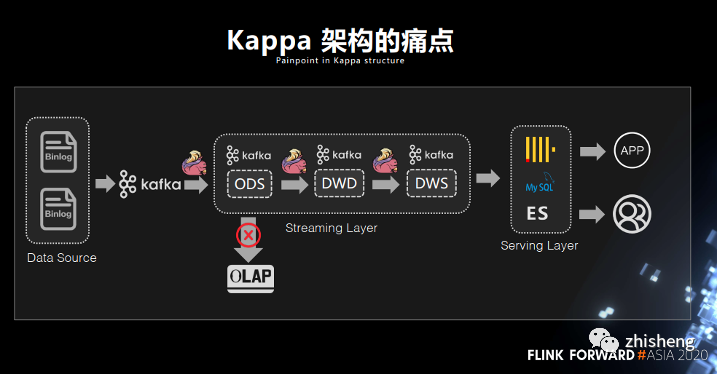
可能有读者会问,如果使用 Flink 直接读 MQ 数据来算呢?其实是可以的,因为像 Pulsar 也提供了无限期的存储,但效率会比较低,主要原因是 MQ 无法提供索引来实现谓词下推等优化[10],另外经过聚合或者 Join 的数据是 Changelog 格式,数据流中会包含旧版本的冗余数据。因此业界有新的趋势是用 Iceberg 等数据湖来代替 MQ 作为数仓中间层的存储,这样的优点是能比较好地对接离线数仓及其长久以来的业务模式,而代价则是数据延迟可能变为近实时。以本文 “文件适合存储状态” 的观点来讲,实时数仓中需要被业务查询的表的确更适合用文件存储,因为业务需要的是状态,而不关心变更历史。
在离线混部
在离线混部指的是将在线业务与大数据场景的实时、离线业务混合部署在相同的物理集群上,目的是提高机器的利用率。由于历史原因,在线业务和大数据业务的技术栈是相对独立的,因而理所当然地分开部署: 在线业务使用为 k8s/Mesos 代表的集群管理器,而大数据业务通常使用 Hadoop 生态原生的 YARN 作为集群管理器。然而随着集群规模的扩大,资源利用率不足的问题日益突显,例如通常 CPU 平均占用不足 20%。解决问题的最佳办法便是打破不同业务独立集群的边界实现混部,并利用业务资源的潮汐现象和优先级进行动态的资源分配。实际上很多公司在离线混部已经有多年的探索,而最近一两年 k8s 的迅猛发展大大加速了业务(包括大数据)上云的进度,因而在离线混部再次成为热点。
在离线混部技术的难点主要是统一集群管理器、资源隔离和资源调度这几点,下文逐点展开。
首先,统一在离线的集群管理器是混部的基础。目前大多数公司是 k8s 与 YARN 并存的状态,但在云原生的大趋势下,大数据组件也逐步对 k8s 提供头等的支持,看起来 k8s 一统集群资源只是时间问题。不过 k8s 的要做到这点也绝非一路平坦,一是 k8s 的一级调度设计并不能很好地满足很多批计算作业的复杂调度,二是 k8s 当前能掌控的集群规模一般在 5000 节点左右,比起 YARN 差了一个量级[11]。因此在当前阶段,业界大多是选择 YARN on k8s 的方式来渐进式地迁移。常见的做法是在 k8s pod 里启动 NM,让 YARN 部分 NM 节点运行在 k8s 上。
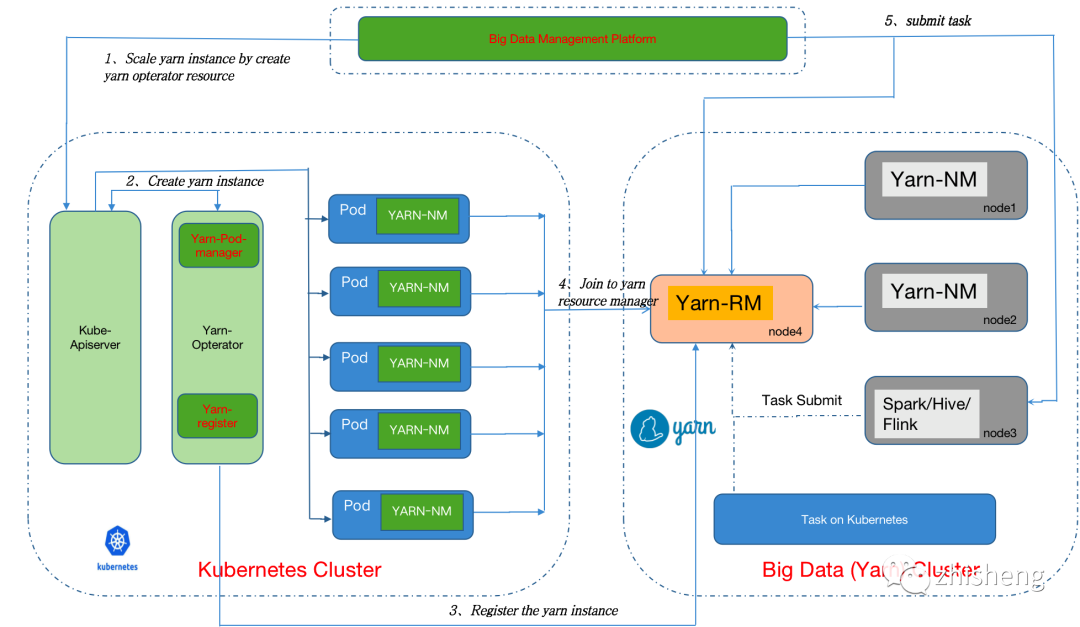
然后,资源隔离是混部的核心。虽然 k8s 提供资源管理,但是仅限于 CPU、内存两个维度,而网络和磁盘 IO 却暂未纳入考虑[12]。这对于在混部大数据业务而言显然是不够的,因为大数据业务可以很轻松地将机器的网络或磁盘打满,严重影响在线业务。要达到生产的资源隔离,通常需要 Linux 内核级别的支持,这超出本文的范围和笔者的知识储备,不再详述。
最后,资源调度是服务质量的保证。调度器需要考虑物理节点的资源异构、同类业务充分打散分布和业务的部署偏好来优化调度,优化效率并最大程度避免相互干扰。此外,集群调度器会按照优先级来进行资源超发。在业务低峰期,空闲的资源可以用于跑优先级低、延迟不敏感的离线作业,然而在业务出现突发流量或发现在线作业受到离线作业干扰时,集群调度器需要快速让离线作业退出并让出资源。
HTAP
HTAP 全称是 Hybrid Transactional Analytical Processing (混合事务分析处理),即同时支持在线事务查询和分析查询。前文所说的计算和存储的流批一体是实时和离线技术栈上的融合,在离线混部是大数据业务与在线业务运维管理上的融合,而 HTAP 就是最终的大数据和在线业务技术栈上的融合。自 2014 年 Gartner 提出该概念后,HTAP 成为了数据库领域最为热门的方向。除了简化 OLTP 和 OLAP 两套技术栈的复杂架构外,HTAP 还有一个重要的需求背景: 随着数据场景从企业内部决策支持,到用作为线上增值服务的算法模型输入(比如推荐、广告),再到直接作为面向用户的数据服务(比如淘宝生意参谋、滴滴行车轨迹等),OLTP 和 OLAP 的边界正变得越来越模糊。
HTAP 从架构来看分为两类: 单系统同时服务于 OLTP 和 OLAP,或有两套系统分别服务于 OLTP 和 OLAP。现在业界比较热门的 TiDB、OceanBase 和 Google 的 F1 Lightning 都属于后者。在这类系统中,OLTP 和 OLAP 分别有独立的存储和计算引擎,并依靠内建的同步机制来将 OLTP 系统中的行存数据同步到 OLAP 系统转为适合分析业务的列存数据。在此之上,查询优化器对外提供统一的查询入口,将不同类型的查询分别路由到合适的系统中。
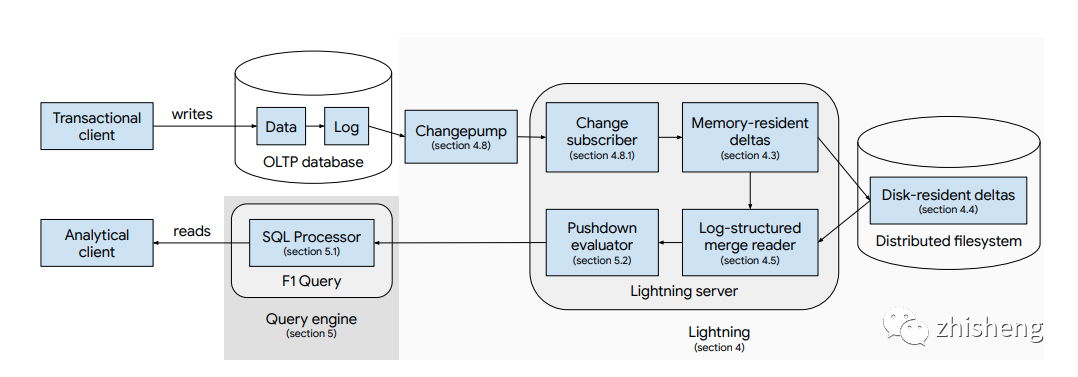
比起传统的基于 Hadoop 生态的数据仓库,HTAP 的优点是:
内置可靠的数据同步机制,避免建立 OLTP 库到数据仓库的复杂 ETL 管道,同时也提高了数据一致性(比如 TiDB 和 F1 Lightning 都提供与 OLTP 一致的可重复读一致性)。
对用户友好的统一查询接口,屏蔽了底层引擎的复杂性,大大降低了 OLAP 的门槛。这使得在有授权的情况下,线上业务团队能利用 OLAP 进行轻量级数据分析,而数据分析团队也能利用 OLTP 进行快速的点查。
数据安全性更有保障。将数据在不同组件间移动容易造成权限不一致和安全漏洞,而 HTAP 可以复用 OLTP 的数据权限和避免数据跨组件访问来避免这些问题。
虽然 HTAP 的愿景非常美好,但要构建经得起业务检验的 HTAP 系统并不容易。数据库和大数据领域先后有多次尝试,不过目前算得上成功的案例屈指可数,其主要难点在于:
OLTP 和 OLAP 资源的隔离。由于 OLAP 常包含一些资源密集的复杂查询,OLTP 和 OLAP 公用的组件很容易产生资源竞争,从而干扰优先级更高的 OLTP 查询。在早些年的案例中,共享计算和存储的 HTAP 都不能获得很好的效果,因此最近的 HTAP 数据库都在硬件级别进行两者负载的隔离,也就是独立的存储和计算。
数据同步机制如何确保数据一致性和新鲜度(freshness)。不同于基于 Hadoop 的数据仓库通常允许小时级别的数据延迟和不一致窗口,HTAP 通常承诺强一致性以保证一个查询无论被路由到 OLTP 系统还是 OLAP 系统都能获得一致结果,这对数据同步机制的性能和容错性都提出很高的要求。目前在 HTAP 领域称得上 State of the art 的两个数据库里,F1 Lightning 使用无入侵的 CDC 方式进行同步,TiDB 基于 Raft 算法进行数据复制。前者松耦合,但实现比较复杂;后者更加简洁优雅,但会受 OLTP 设计的约束,比如复制的数据块大小需要与 OLTP 一致[16]。
如何利有机结合 OLTP 和 OLAP 工作负载。目前的 HTAP 像同一个门面后的两套独立系统,一个查询要么交给 OLTP 处理,要么交给 OLAP 处理,并没有产生 1 + 1 > 2 的化学反应。IBM 指出,真正的 OLAP 是在同一个事务里高效地处理 OLTP 和 OLAP 两种工作负载[15]。要做到这点,靠数据同步的 HTAP 架构大概难以做到,需要从分布式事务算法层面来解决。
尽管 HTAP 还未被广泛应用,但可以预见未来将在很大程度上影响数据仓库架构。在数据规模不大、分析需求简单的场景下,HTAP 将成为最为流行的解决方案。
未来:回归本质
“融合” 是大数据当前发展的大势,这点从历史的发展规律角度可以窥见其必然性。对于新出现的技术挑战,在最初的探索期各类解决方案总是层出不穷,其中采用 Greenfield 方式的解决方案可能会将已有的基础推倒重来,相比原有技术带来一定的退化(Regression)。退化限制了新技术的应用场景,导致新旧两种技术的双轨制,但只要核心功能没有太大变化,这样的割裂这往往只是暂时的。
回顾大数据的发展历史,“大数据” 一词原本用于描述数据规模、多样性和处理性能给数据管理带来的挑战,而后续被用于描述为处理这类问题而构建的数据系统,即 “大数据系统”。由于这类系统基于与传统数据不同的基础构建,并舍弃后者标配的事务特性,导致难以应用到线上业务,通常只用于数据仓库、机器学习等对数据延迟、数据准确性要求稍微低一点的场景,而这类业务场景又逐渐被称为 “大数据业务”。
然而,大数据技术本质是数据密集型的分布式系统,而随着分布式系统的发展和普及,大数据系统在功能特性和业务场景的限制终将被打破,与新出现的以 Spanner 为代表的 NewSQL 分布式数据库并无明显界限。届时,”大数据” 一词也许会和很多 buzzword 一样逐渐消失在历史的长河,回归到通用的分布式系统的本质。水平扩展、优秀容错性、高可用的分布式特性将成为各种系统的标配,无论在 OLTP 或者 OLAP 场景。
参考
Wikipedia - Web 2.0 Wikipedia - Big data MapReduce: A major step backwards 3D Data Management: Controlling Data Volume, Velocity, and Variety How to beat the CAP theorem 为什么阿里云要做流批一体? Questioning the Lambda Architecture Stream is the new file 基于 Flink 的典型 ETL 场景实现方案 Flink + Iceberg 全场景实时数仓的建设实践 谈谈 Kubernetes 的问题和局限性 Kubernetes#27000: limiting bandwidth and iops per container TiDB: A Raft-based HTAP Database F1 Lightning: HTAP as a Service Hybrid Transactional/Analytical Processing: A Survey 读论文 - F1 Lightning: HTAP as a Service
本文作者:Paul Lin
本文链接:2021/06/23/浅谈大数据的过去、现在和未来/
--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇