
Python+OpenCV+百度智能云
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
转自 | 马少爷
一、人脸识别——人数识别+标记
1.导入模块
import timeimport base64import cv2import requests
time模块:计时
base64模块:由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成 ASCII字符的一种方法。
cv2模块:本程序中要用到opencv的框选模块
requests模块:使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作
def gettoken():token = ""if token == "":APP_ID = '*****' # 你的APP_IDAPI_KEY = '*****' # 你的API_KEYSECRET_KEY = '*****' # 你的SECRET_KEY# client_id 为官网获取的AK, client_secret 为官网获取的SKhost = 'https://aip.baidubce.com/oaut/2.0/token?grant_type=client_credentials' + '&client_id=' + API_KEY + '&client_secret=' + SECRET_KEY# print(host)response = requests.get(host)# if response:# for item in response.json().items(): # 逐项遍历response.json()----字典# print(item)token = response.json()["access_token"]print(">>成功获取到token")return token
需要注意的是:这里获取的token你可以自己输出一下,如果是24.*****(一长串)就说明对了。
def read_pic(name):f = open(name, "rb")base64_data = base64.b64encode(f.read())s = base64_data.decode()print(">>图片读取成功")return s
# 人脸检测与属性分析def face_nums(picture):token = gettoken()request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"params = {"image": picture,"image_type": "BASE64","quality_control": "NORMAL","max_face_num": 10}request_url = request_url + "?access_token=" + tokenheaders = {'content-type': 'application/json'}response = requests.post(request_url, data=params, headers=headers).json()if response:print(">>成功获取到response")# for item in response.items(): # 遍历response# print(item)else:print("response == NULL")if response["error_code"] == 0:num = response["result"]["face_num"]print("图中人数为:%d" % num)print(">>人数检测完成\n")else:print("出错了")return response
5.人脸标记
得到上一步的response(其为字典结构),我们试着将其输出看看:
for item in response.items(): # 遍历responseprint(item)
得到输出结果:
('error_code', 0)('error_msg', 'SUCCESS')('log_id', 579201101157)('timestamp', 1612106758)('cached', 0)('result', {'face_num': 4, 'face_list': [{'face_token': 'fa26f3aa9227ef72c65dccc2cef4e09b', 'location': {'left': 331.56, 'top': 158.35, 'width': 101, 'height': 101, 'rotation': -20}, 'face_probability': 1, 'angle': {'yaw': 14.84, 'pitch': 0.53, 'roll': -19.51}}, {'face_token': '2f0747b582fa60572fa7340c3bdf081c', 'location': {'left': 245.17, 'top': 136.09, 'width': 70, 'height': 70, 'rotation': -23}, 'face_probability': 1, 'angle': {'yaw': 19.23, 'pitch': 11.06, 'roll': -28.17}}, {'face_token': '19ff570779608d83977781f2f20dfe25', 'location': {'left': 172.71, 'top': 95.36, 'width': 52, 'height': 52, 'rotation': 0}, 'face_probability': 1, 'angle': {'yaw': 0.81, 'pitch': 2.76, 'roll': -4.04}}, {'face_token': 'ad478dbf67ec8ca57657d41b520e09ae', 'location': {'left': 121.06, 'top': 49.85, 'width': 53, 'height': 47, 'rotation': 9}, 'face_probability': 1, 'angle': {'yaw': -0.72, 'pitch': 8.11, 'roll': 7.21}}]})
我们仔细分析一下,不要觉得他很复杂,其实就是一个字典里套字典的形式。其result键下就是我们需要的的信息,包括人数,人脸坐标,还有旋度,俯仰角等。所以我们把需要的人数和人脸坐标提取出来,通过cv2.rectangle()函数将人脸框选出来(注意,此函数里的所有参数只能为int类型,我们从字典中得到的数字为字符串类型,所以需要转换一下)。
实现代码:
def face_load(response, frame):num = response["result"]["face_num"]load = response["result"]["face_list"]# print(load)# for item in load.items():# print(item)for i in range(num): # 使用遍历把所有的人脸都标出框location = load[i]['location'] # 获取人脸坐标# print(location)cv2.rectangle(frame, (int(location['left']), int(location['top'])),(int(location['width'] + location['left']), int(location['height'] + location['top'])),(0, 0, 255), 2) # opencv的标框函数cv2.imshow('人脸检测', frame)cv2.waitKey(1) # 刷新界面 不然只会呈现灰色print('运行时间是{}'.format(time.time() - t1))time.sleep(3) # 暂停3秒 展示图片
def main():# p1 = read_pic("we.jpeg")p1 = read_pic("Hero.jpg")response = face_nums(p1)frame = cv2.imread("Hero.jpg")# frame = cv2.imread("we.jpeg")cv2.waitKey(0)# print("frame为:\n", frame)face_load(response, frame)
7.运行结果
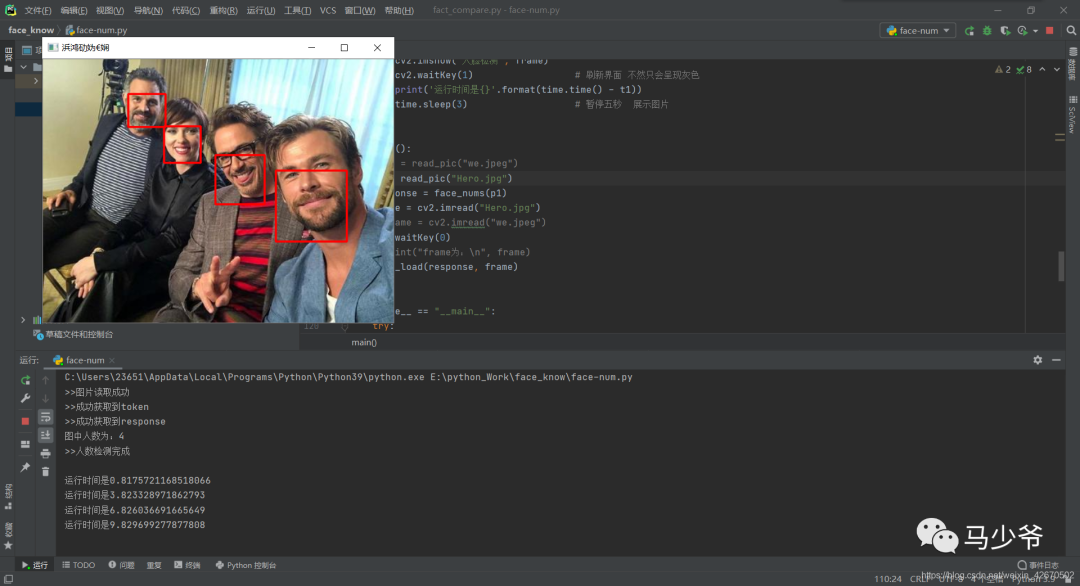
8.总结
1、官方人脸检测API文档
https://cloud.baidu.com/doc/FACE/s/yk37c1u4t
2.官方常见问题及排查API文档
https://cloud.baidu.com/doc/FACE/s/Zk5eyn5x3
3.官方常见错误码API文档
https://cloud.baidu.com/doc/FACE/s/5k37c1ujz
4.注意事项&解决方案:
(1)post参数中,body中image和image_type为必要参数,其他根据自己的需要添加
(2)请求体格式化:Content-Type为application/json,通过json格式化请求体。
(3)Base64编码:请求的图片需经过Base64编码,图片的base64编码指将图片数据编码成一串字符串,使用该字符串代替图像地址。您可以首先得到图片的二进制,然后用Base64格式编码即可。需要注意的是,图片的base64编码是不包含图片头的,如data:image/jpg;base64,
(4)图片格式:现支持PNG、JPG、JPEG、BMP,不支持GIF图片
(5)cv2.rectangle()函数里的所有参数只能为int类型,我们从字典中得到的数字为字符串类型,所以需要转换一下
(6)cv2.imshow()之后必须加cv2.waitKey(),否则打开时间过短会报错
例如:
cv2.imshow('人脸检测', frame)cv2.waitKey(1)
二、人脸融合
1.导入模块
import base64import jsonimport requests
base64模块:由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成 ASCII字符的一种方法。
json模块:JSON的数据格式其实就是python里面的字典格式,里面可以包含方括号括起来的数组,也就是python里面的列表。
requents模块:进行网络请求时,变得人性化,模仿浏览器的访问网页并获得反执等
2.获取token
def gettoken():token = ""if token == "":APP_ID = '【】' # 你的APP_IDAPI_KEY = '【】' # 你的API_KEYSECRET_KEY = '【】' # 你的SECRET_KEY# client_id 为官网获取的AK, client_secret 为官网获取的SKhost = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials' + \'&client_id=' + API_KEY + \'&client_secret=' + SECRET_KEY# print(host)response = requests.get(host)# if response:# for item in response.json().items(): # 逐项遍历response.json()----字典# print(item)token = response.json()["access_token"]print(">>成功获取到token")return token
这里首先要在百度智能云获取到自己的APP_ID、API_KEY、SECRET_KEY
3.获取图片base64
# 3.获取图片base64 -- base64是图片的一种格式,所以要先打开图片,然后转成base64编码才能用def read_pic(name):f = open(name, "rb")base64_data = base64.b64encode(f.read())s = base64_data.decode()print(">>图片读取成功")return s
# 4.保存base64到本机def save_pic(data):# image_data = base64.decode()# f = open("mix.jpg","wb")# f.write(image_data)imagedata = base64.b64decode(data)file = open('E:\\python_Work\\face_know\\mix.jpg', "wb")file.write(imagedata)print(">>图片保存完成")
# 5.图片融合def mix(template, target):token = gettoken()url = "https://aip.baidubce.com/rest/2.0/face/v1/merge"request_url = url + '?access_token=' + tokenparams = {"image_template": {"image": template,"image_type": "BASE64","quality_control": "NORMAL"},"image_target": {"image": target,"image_type": "BASE64","quality_control": "NORMAL"},"merge_degree": "HIGH"}params = json.dumps(params)headers = {"content-type": "application/json"}result = requests.post(request_url, data=params, headers=headers).json()if result["error_code"] == 0:res = result["result"]["merge_image"]save_pic(res)print(">>人脸融合完成")else:print(str(result[' error_code ']) + result['error_msg'])
根据官方文档要求,访问方式为post,先设置访问请求头(headers)和主要内容(body),
请求地址在这块:
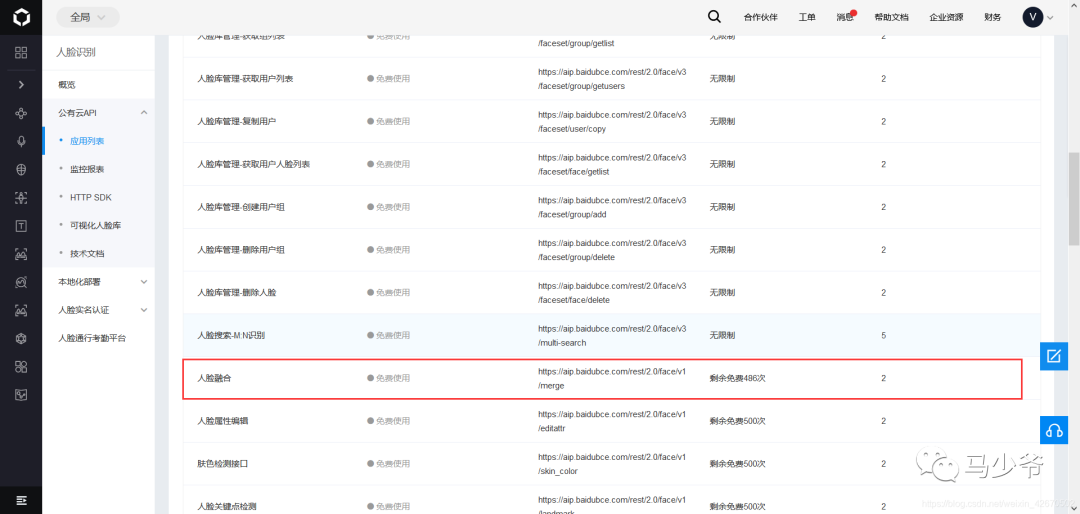
# 6.功能测试# 主函数def main():image1 = read_pic("Picture1.jpg")image2 = read_pic("Picture2.jpg")mix(image2, image1)if __name__ == "__main__":try:main()print(">>程序执行完成")except Exception as result:print("出错原因:%s" % result)
Picture2.jpg(大家都爱的千玺,侵删)

合成效果如图:

8.总结
注意事项&解决方案:
(1)post参数中,body中image和image_type为必要参数,其他根据自己的需要添加
(2)请求体格式化:Content-Type为application/json,通过json格式化请求体。
(3)Base64编码:请求的图片需经过Base64编码,图片的base64编码指将图片数据编码成一串字符串,使用该字符串代替图像地址。您可以首先得到图片的二进制,然后用Base64格式编码即可。需要注意的是,图片的base64编码是不包含图片头的,如data:image/jpg;base64;
(4)一共有500次调用限制,谨慎使用,其他调通了在来这块访问,不然等程序调完,次数也不多了
三、人脸识别——视频人脸锁定
1.导入模块
import sysimport cv2
def videocapture():cap = cv2.VideoCapture(0) # 生成读取摄像头对象width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取视频的宽度height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取视频的高度fps = cap.get(cv2.CAP_PROP_FPS) # 获取视频的帧率fourcc = int(cap.get(cv2.CAP_PROP_FOURCC)) # 视频的编码# 定义视频对象输出writer = cv2.VideoWriter("video_result.mp4", fourcc, fps, (width, height))while cap.isOpened():ret, frame = cap.read() # 读取摄像头画面cv2.imshow('teswell', frame) # 显示画面key = cv2.waitKey(24)writer.write(frame) # 视频保存# 按Q退出if key == ord('q'):breakcap.release() # 释放摄像头cv2.destroyAllWindows() # 释放所有显示图像窗口
def CatchUsbVideo(window_name, camera_idx):cv2.namedWindow(window_name)# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头cap = cv2.VideoCapture("video.mp4")# 告诉OpenCV使用人脸识别分类器#classfier = cv2.CascadeClassifier(r"./haarcascade_frontalface_alt2.xml")classfier = cv2.CascadeClassifier(r"F:\OpenCV\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml")# 识别出人脸后要画的边框的颜色,RGB格式color = (0, 255, 0)while cap.isOpened():ok, frame = cap.read() # 读取一帧数据if not ok:break# 将当前帧转换成灰度图像grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))if len(faceRects) > 0: # 大于0则检测到人脸for faceRect in faceRects: # 单独框出每一张人脸x, y, w, h = faceRectcv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)# 显示图像cv2.imshow(window_name, frame)c = cv2.waitKey(10)if c & 0xFF == ord('q'):break# 释放摄像头并销毁所有窗口cap.release()cv2.destroyAllWindows()
这里需要注意,haarcascade_frontalface_alt2.xml文件的路径,在自己的安装路径里,在下图这个位置,记得替换为自己的路径
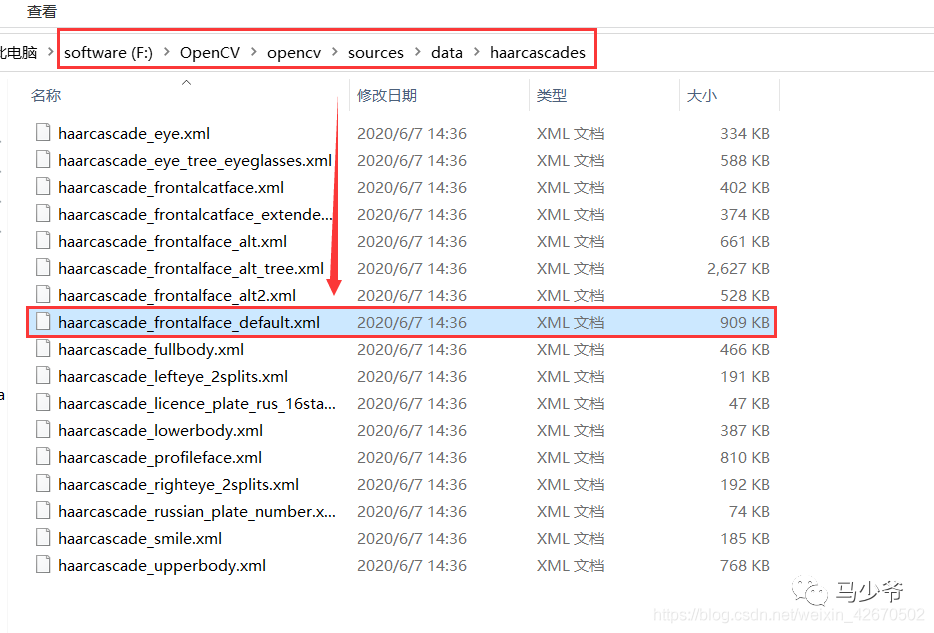
if __name__ == '__main__':#videocapture()try:if len(sys.argv) != 1:print("Usage:%s camera_id\r\n" % (sys.argv[0]))else:CatchUsbVideo("识别人脸区域",0)except Exception as Error:print(Error)

唯一问题是,最后显示名称因为是中文,会出现如图乱码,暂时不知道解决方案
6.总结
本设计需要注意的是:
1.是否需要调用本地摄像头,如果不用,本地应该有需要检测的视频(我试了下,gif也可以)
2.haarcascade_frontalface_alt2.xml文件路径要设置好
四、人脸识别——人脸相似度对比
1.导入模块
from aip import AipFaceimport base64import matplotlib.pyplot as plt
""" 你的APPID,API_KEY和SECRET_KEY """APP_ID = '【】' # 你的APP_IDAPI_KEY = '【】' # 你的API_KEYSECRET_KEY = '【】' # 你的SECRET_KEY# 封装成函数,返回获取的client对象def get_client(APP_ID, API_KEY, SECRET_KEY):"""返回client对象:param APP_ID::param API_KEY::param SECRET_KEY::return:"""return AipFace(APP_ID, API_KEY, SECRET_KEY)
pic1 = "T.jpg"pic2 = "Y.jpg"client = get_client(APP_ID, API_KEY, SECRET_KEY)result = client.match([{'image': str(base64.b64encode(open(pic1, 'rb').read()), 'utf-8'),'image_type': 'BASE64',},{'image': str(base64.b64encode(open(pic2, 'rb').read()), 'utf-8'),'image_type': 'BASE64',}])print(result)if result['error_msg'] == 'SUCCESS':score = result['result']['score']print('两张图片相似度:', score)else:print('错误信息:', result['error_msg'])pc1 = plt.imread(pic1)pc2 = plt.imread(pic2)plt.imshow(pc1)plt.show()plt.imshow(pc2)plt.show()
4、结果测试
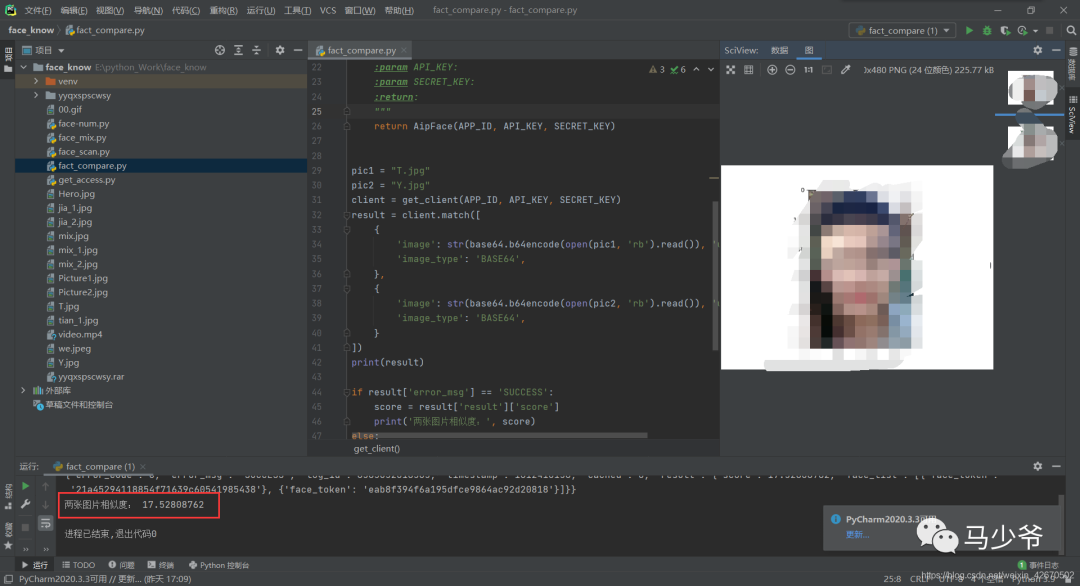
参考文献:
https://blog.csdn.net/weixin_42670502
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!