
在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
人工智能与算法学习
共 5794字,需浏览 12分钟
·
2023-10-29 08:53
该论文介绍了一种名为 ReMax 的新算法,专为基于人类反馈的强化学习(RLHF)而设计。ReMax 在计算效率(约减少 50% 的 GPU 内存和 2 倍的训练速度提升)和实现简易性(6 行代码)上超越了最常用的算法 PPO,且性能没有损失。

-
论文链接:https://arxiv.org/abs/2310.10505 -
作者:李子牛,许天,张雨舜,俞扬,孙若愚,罗智泉 -
机构:香港中文大学(深圳),深圳市大数据研究院,南京大学,南栖仙策 -
开源代码:https://github.com/liziniu/ReMax




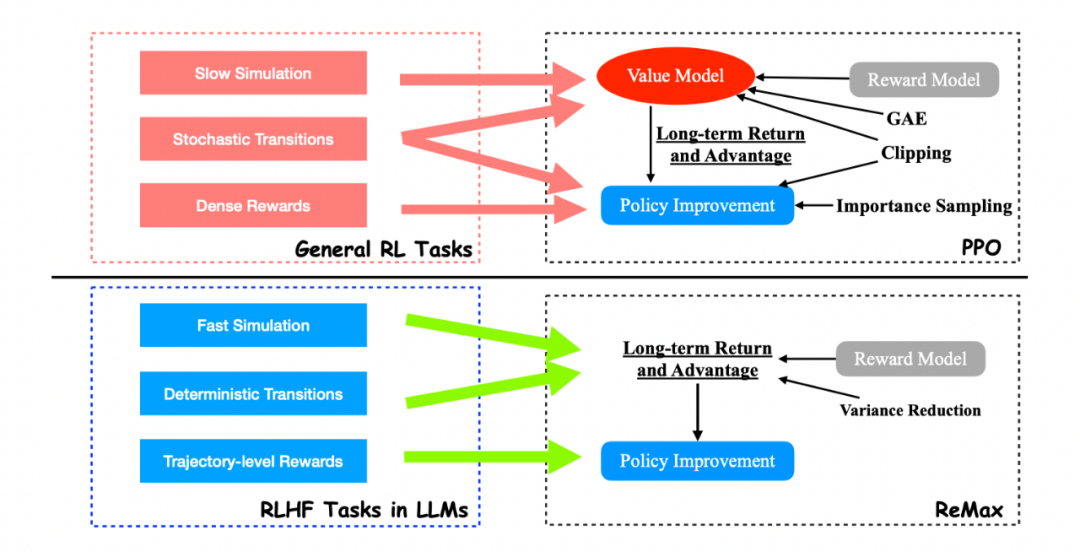

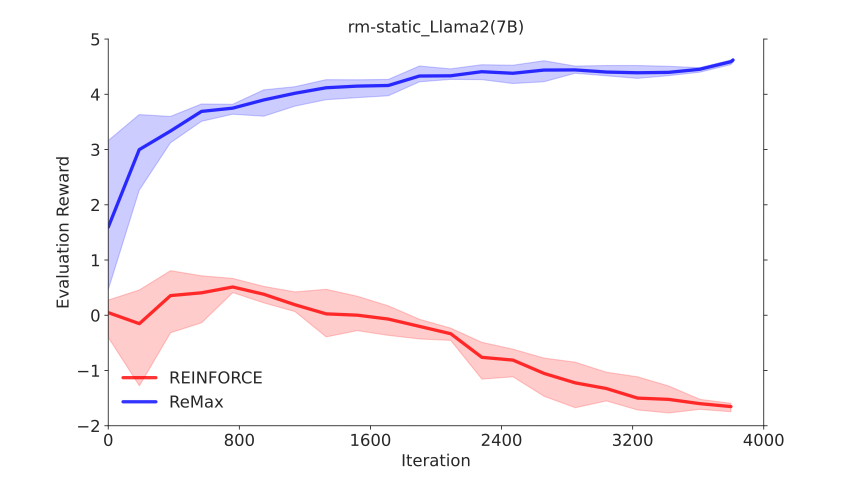
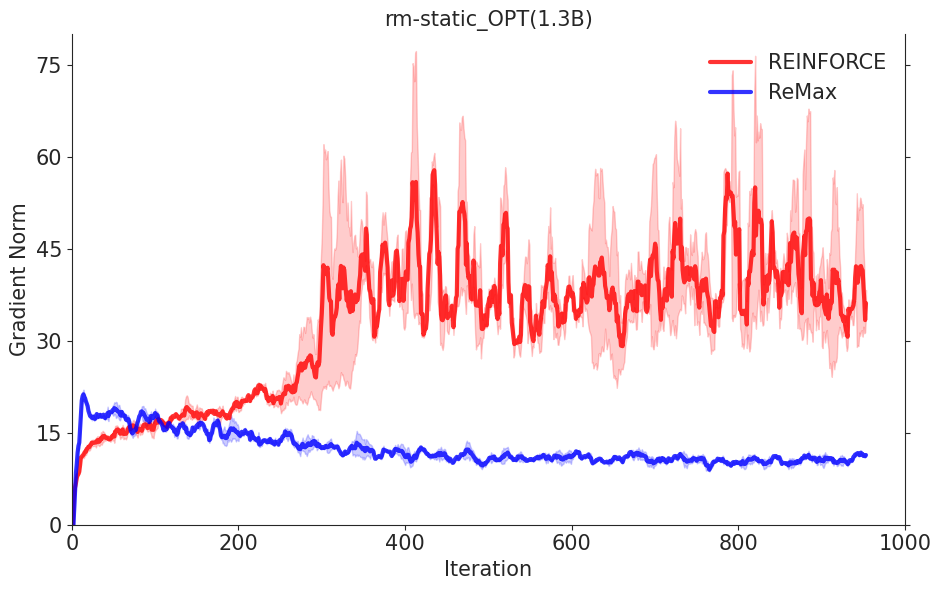
REINFORCE可以在计算层面利用好RLHF任务的三个性质,因为REINFORCE直接利用一个响应的奖励来进行优化,不需要像一般的RL算法一样需要知道中间步骤的奖励和值函数。然而,由于策略的随机性, REINFORCE梯度估计器存在高方差问题(在Richard Sutton的RL书里有指出),这一问题会影响模型训练的有效性,因此REINFORCE在RLHF任务中的效果较差,见下面两张图片。
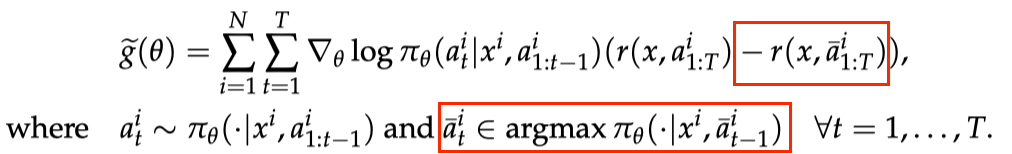
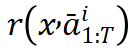 可以看作为期望奖励
可以看作为期望奖励
 的好的近似。在理想情形下(
的好的近似。在理想情形下(
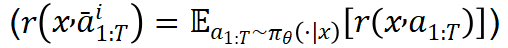 ),对于随机变量
),对于随机变量
 ,
,
 ,因此我们能够期望估计器
,因此我们能够期望估计器
 具有更小的方差。
具有更小的方差。

-
ReMax 的核心部分可以用 6 行代码来实现。相比之下,PPO 要额外引入重要性采样(importance sampling),广义优势估计(generalized advantage estimation,GAE),价值模型学习等额外模块。 -
ReMax 的超参数很少。相比之下,PPO 有额外的超参数,例如重要性采样剪切阈值(importance sampling clipping ratio)、GAE 系数、价值模型学习率,离策略训练轮次(off-policy training epoch)等,这些超参数都需要花大量时间去调优。 -
ReMax 能理论上节省约 50% 内存。相比于 PPO,ReMax 成功移除了所有和价值模型相关的部件,大大减小了内存开销。通过计算,我们发现相比于 PPO,ReMax 能节省约 50% 内存。
-
ReMax 可以像 PPO 一样有效地最大化奖励
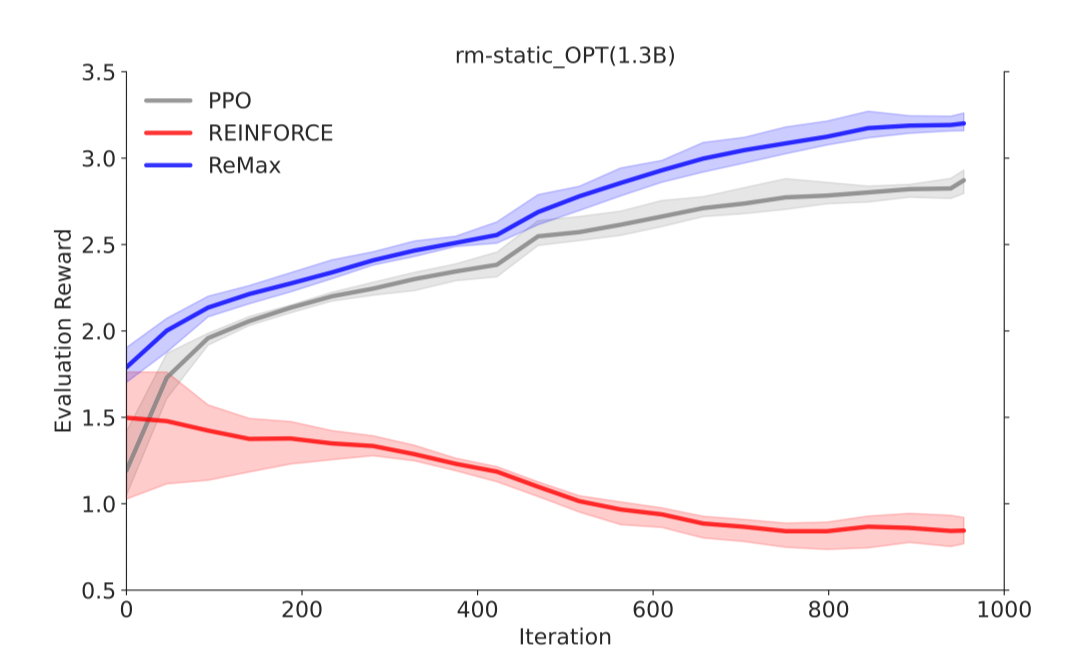
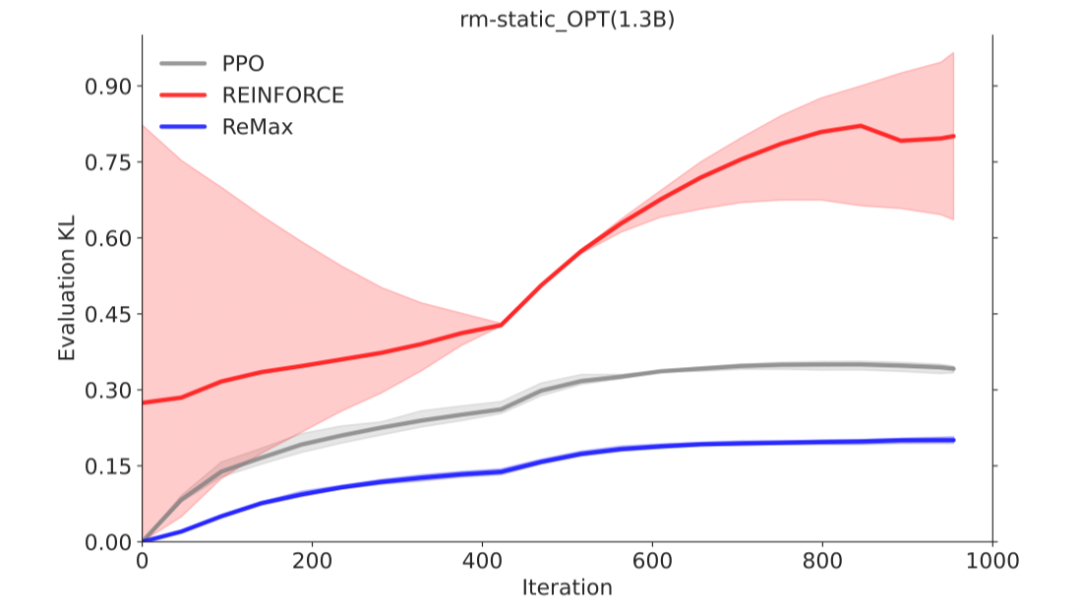
-
在 GPT-4 评估下(LIMA Test Questions),ReMax 得到的策略比 SFT 和 PPO 会更好
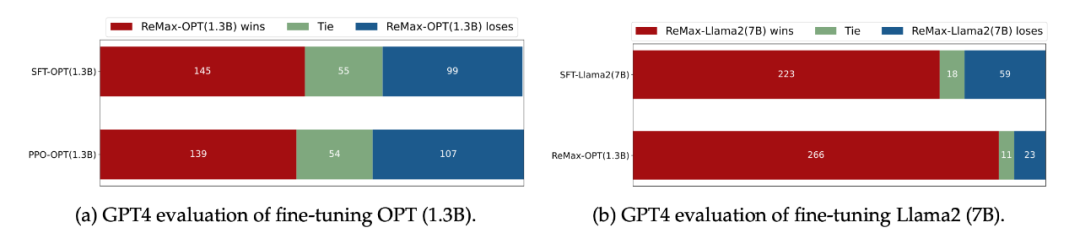
-
ReMax 能节省近 50% 的 GPU 内存。ReMax 移除掉了价值模型和它的训练部分(梯度,优化器,激活值),从而极大节省了 GPU 内存需求。考虑 Llama2-7B,PPO 无法在 8xA100-40GB 的机器上跑起来,但是 ReMax 可以。

-
ReMax 能加快 2 倍的训练速度。在每一轮中,ReMax 调用 2 次生成(generation),1 次反向传播(backpropagation);而 PPO 使用 1 次生成,2 次反向传播。对于大模型而言,生成会比反向传播的时间小,从而 ReMax 可以实现理论上接近 2 倍的训练加速。
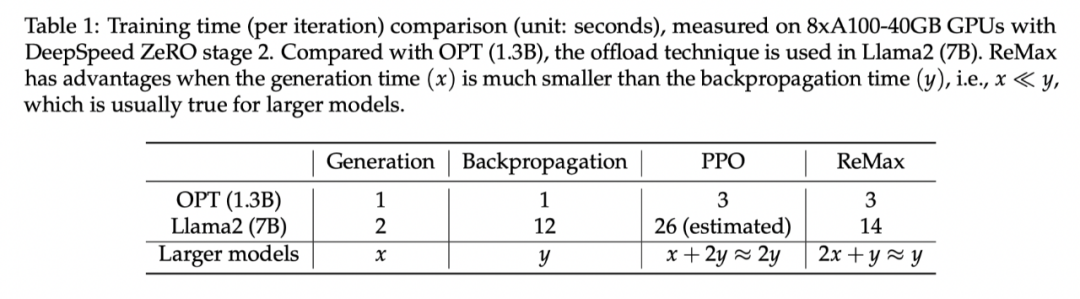
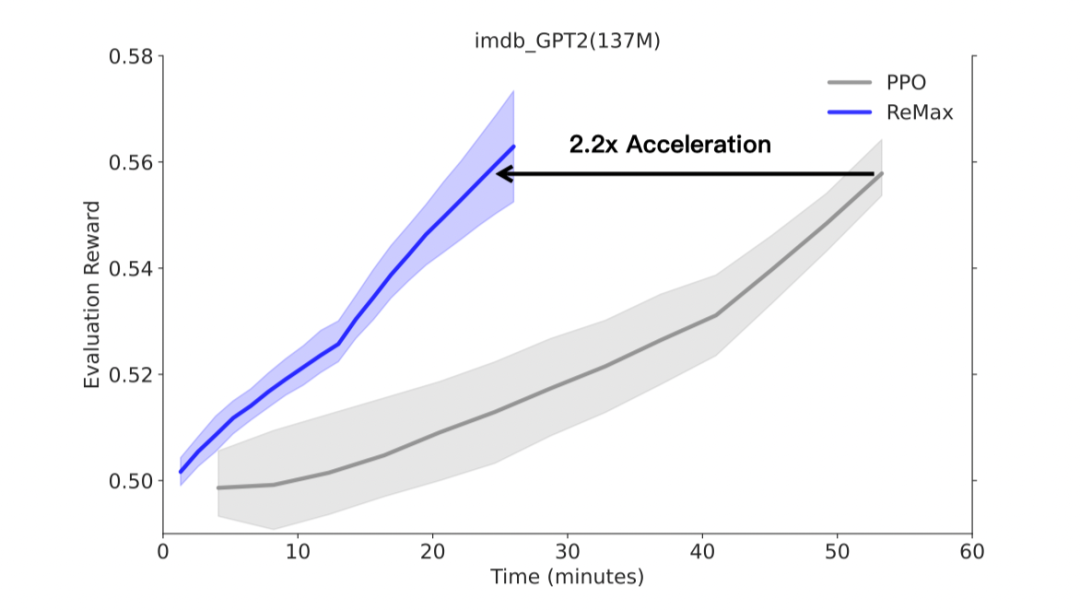
-
更简单的实现: ReMax 的核心部分 6 行代码即可实现。这与 PPO 中的众多复杂的代码构建块形成鲜明对比。 -
更少的内存开销:由于移除了价值模型及其全部训练组件,相比 PPO,ReMax 节省了大约 50% 的 GPU 内存。 -
更少的超参数: ReMax 成功移除了所有和价值模型训练相关的超参数,其中包括:GAE 系数、价值模型学习率、重要性采样时期、小批量(mini-batch)大小。这些超参数往往对问题敏感且难以调整。我们相信 ReMax 对 RLHF 研究者更加友好。 -
更快的训练速度:在 GPT2(137M)的实验中,我们观察到 ReMax 在真实运行时间方面相比于 PPO 有 2.2 倍的加速。加速来自 ReMax 每次迭代中较少的计算开销。通过我们的计算,该加速优势在更大的模型上也能维持(假设在足够大的内存下 PPO 可以被成功部署)。 -
优异的性能:如前所示,ReMax在中等规模实验中与PPO实现了相当的性能,并且有时甚至超越它(可能是由于 ReMax 更容易找到合适的超参数)。我们推测这种良好的性能可以拓展到更大规模的模型中。
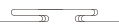
分享
收藏
点赞
在看

评论
60个最新开源Transformer压缩方法,让你的模型更高效!
大家在实际部署Transformer时,都需要压缩模型来减少内存和计算成本。而Transformer模型结合了注意力和前馈网络,往往需要特定压缩技术来提升性能。本文总结了不同情况下的60种Transformer模型压缩方法与开源代码。分为量化、剪枝、知识蒸馏三大类。这60种都是近3年内非常新颖的创新
AI人工智能初学者
0
60个最新开源Transformer压缩方法,让你的模型更高效!
大家在实际部署Transformer时,都需要压缩模型来减少内存和计算成本。而Transformer模型结合了注意力和前馈网络,往往需要特定压缩技术来提升性能。本文总结了不同情况下的60种Transformer模型压缩方法与开源代码。分为量化、剪枝、知识蒸馏三大类。这60种都是近3年内非常新颖的创新
机器学习初学者
0