
基于LLM大模型的向量数据库企业级应用实践
▼最近直播超级多,预约保你有收获
近期直播:《基于 LLM 大模型的向量数据库企业级应用实践》
—1—
为什么说向量数据库是每个人必备的技能?
— 2 —
向量数据库的技术架构和选型
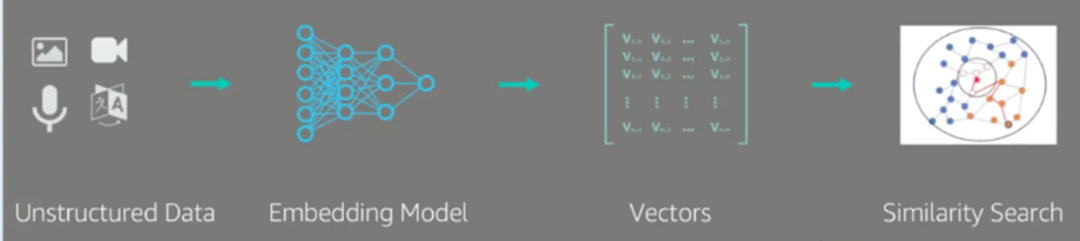
向量数据库为了提供更高的性能和更稳定的服务,会采用弹性微服务分布式高扩展分层架构,按照请求生命周期,划分为接入层、计算层、存储层(如下)。

接入层对用户的 CRUD 请求进行翻译转换,并提供多种类型的查询接口(比如:标量查询、向量查询、自然语言查询等)。
计算层对用户的 CRUD 请求进行标量/向量计算,包括数据的 Embedding 向量化、向量分割、向量相似度计算、向量数据召回、向量结果精排返回等,基于向量的计算是比较消耗资源,采用 GPU 机器来加速。
存储层是向量数据库最重要的一层,提供标量/向量的持久化存储,包括对象存储(Object Store)、键值对存储(Key-Value Store)、向量化存储(Vector Index)。
目前市面上向量数据库百花齐放百家争鸣,国产的有 Milvus、Tencent Cloud VectorDB、Zilliz Cloud 等,海外有 Pinecone、Redis、FAISS、PgVector、Elasticsearch Cloud等。
如何选型?一切脱离业务场景谈向量数据架构选型都是耍流氓,今晚20点直播我们会深度聊聊这个话题,欢迎预约。
—3 —
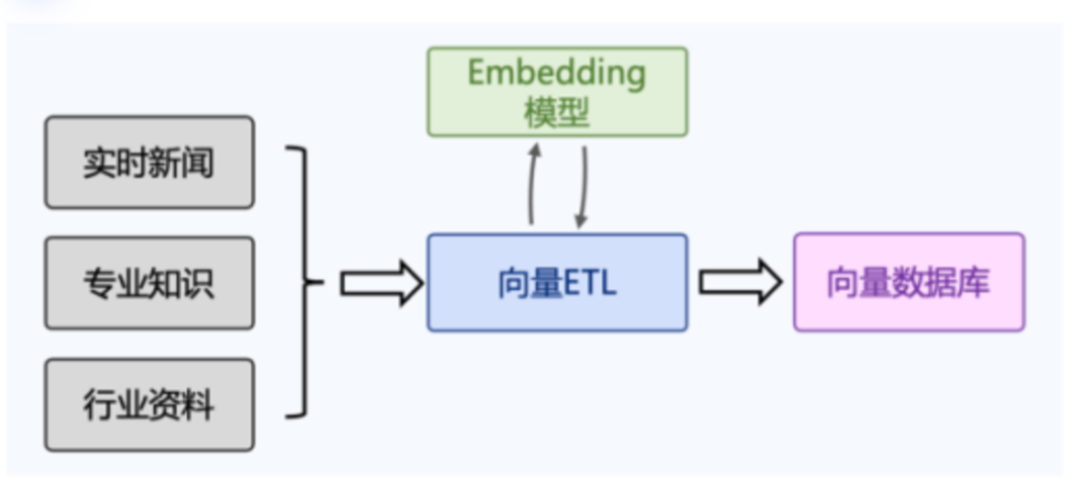
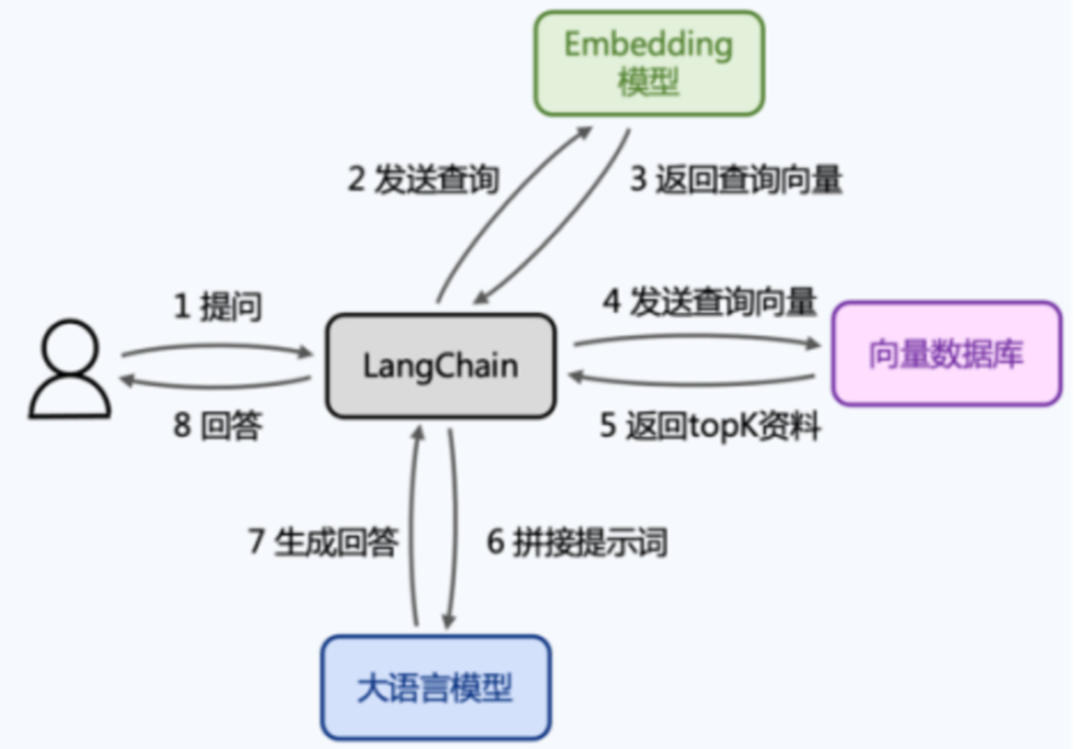
向量数据库的有哪些使用场景?

— 4—
免费超干货 LLM 大模型直播
为了帮助同学们掌握好 LLM 大模型的向量数据库企业级应用实战,今晚8点,我和陈东老师会开一场直播和同学们深度聊聊向量数据库技术架构剖析、大模型离不开向量数据库的技术侧剖析、利用向量数据库构建企业知识库案例实战,请同学点击下方按钮预约直播,咱们今晚8点不见不散哦~~
END