
原来这就是比 ThreadLocal 更快的玩意
数数 ThreadLocal 的缺点。 应该如何针对 ThreadLocal 缺点改进? FastThreadLocal 的原理。 FastThreadLocal VS ThreadLocal 的实操。
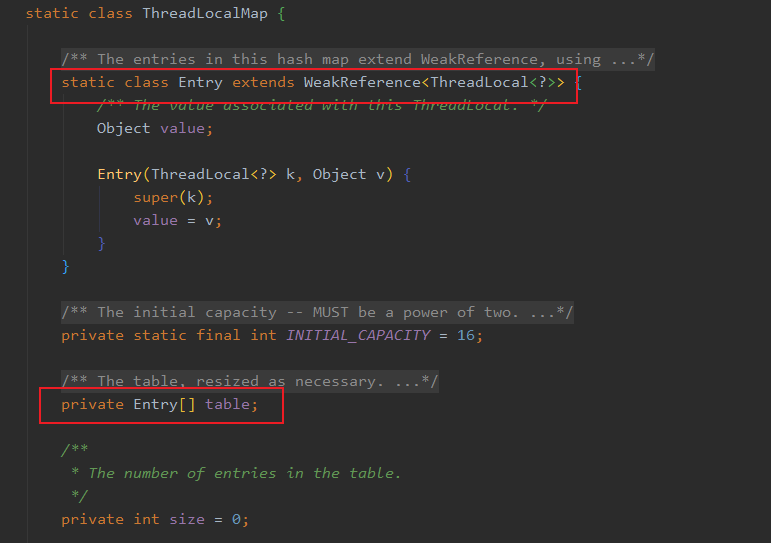
数数 ThreadLocal 的缺点
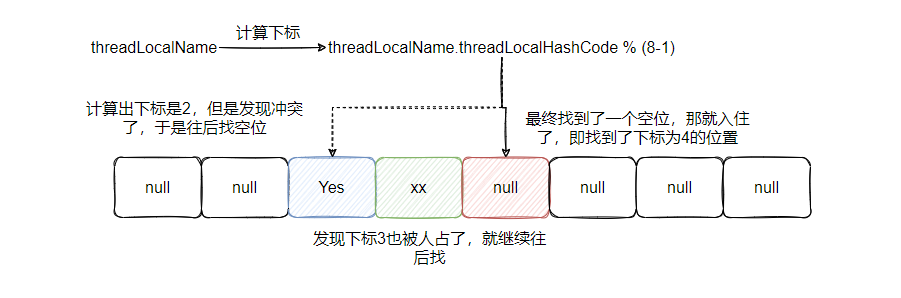
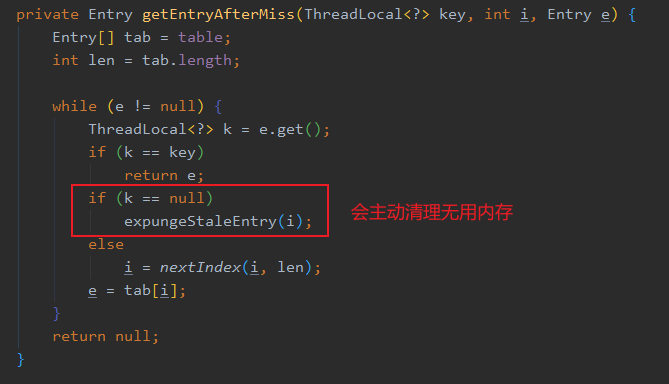
应该如何针对 ThreadLocal 缺点改进
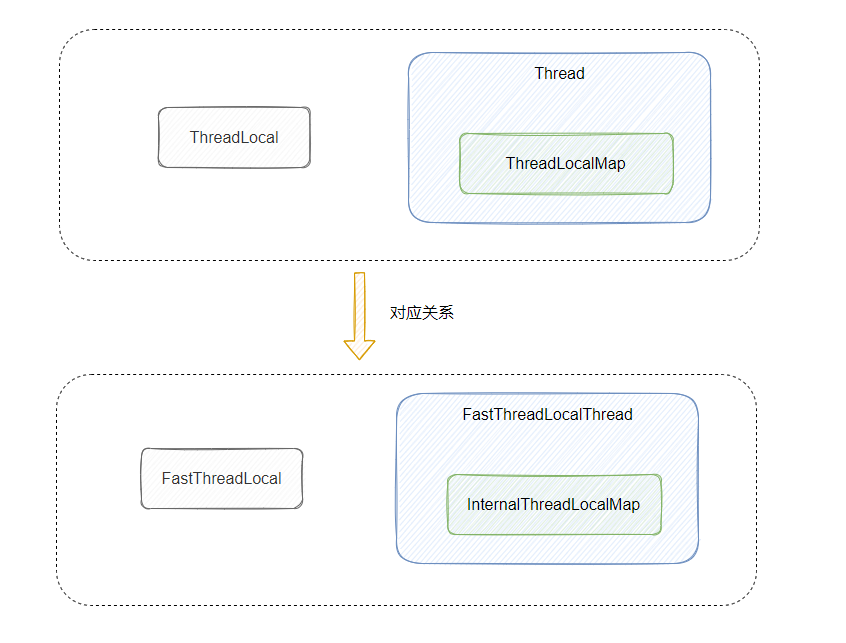
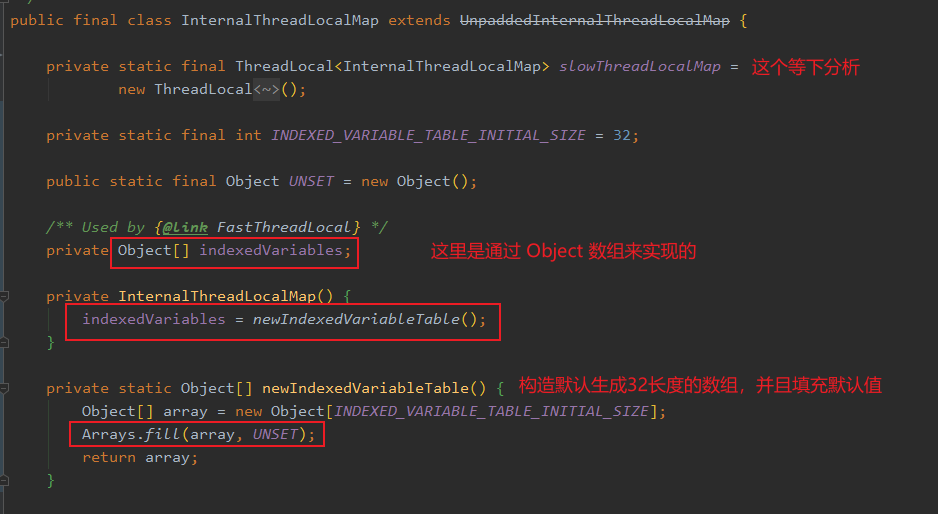
FastThreadLocal 的原理
以下 Netty 基于 4.1 版本分析

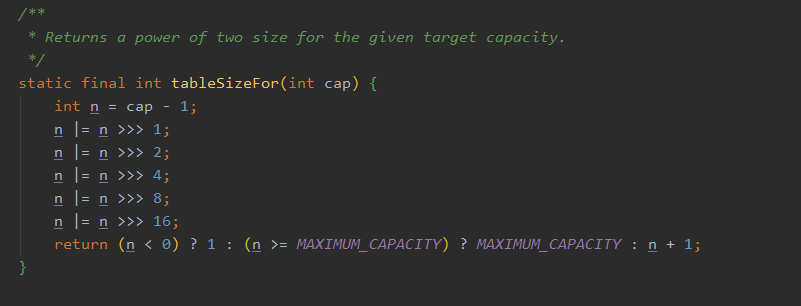
InternalThreadLocalMap.nextVariableIndex() 赋值的,盲猜一下,这个肯定是用原子类递增实现的。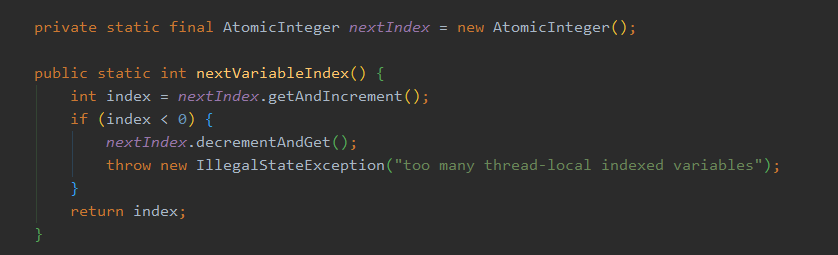
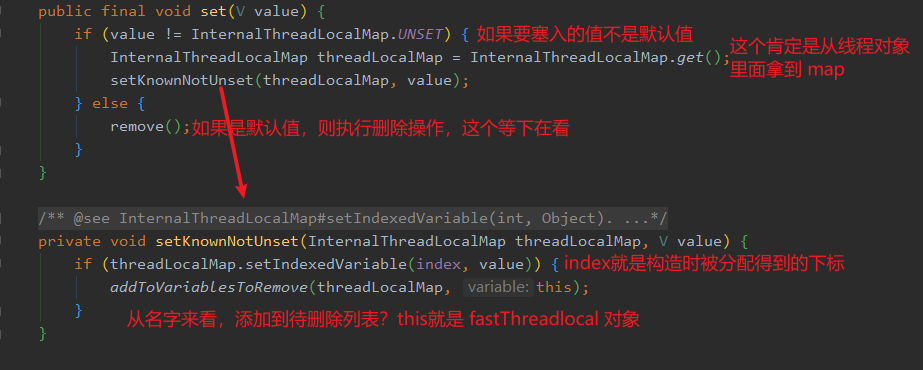
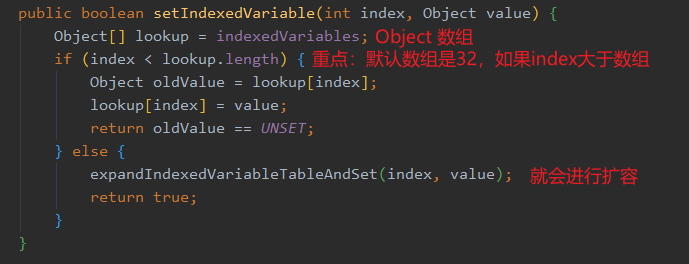
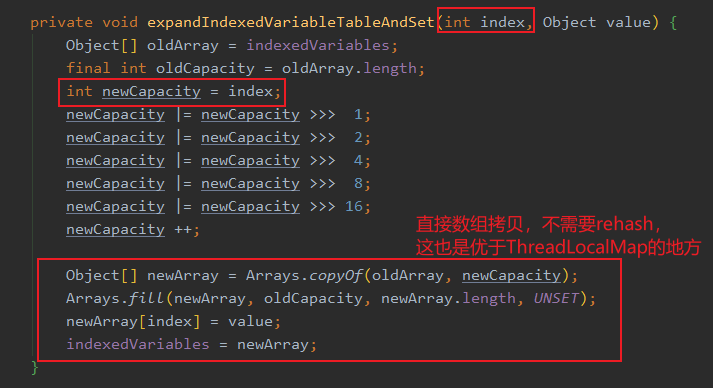
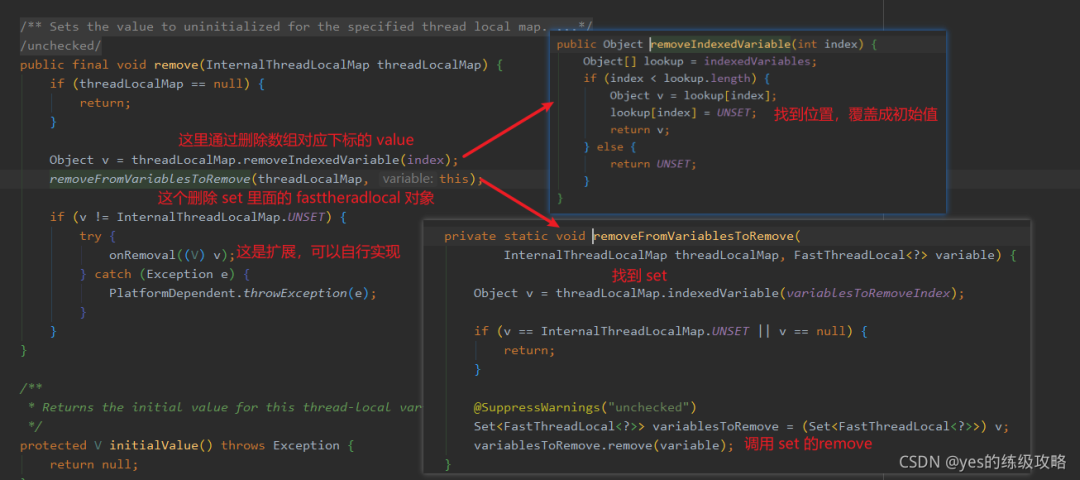
setKnownNotUnset。setIndexedVariable 方法: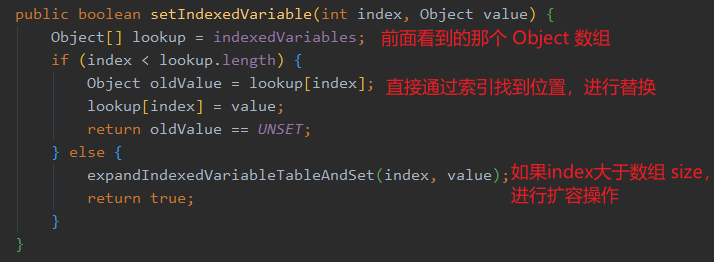
addToVariablesToRemove 方法,这个方法又有什么用呢?
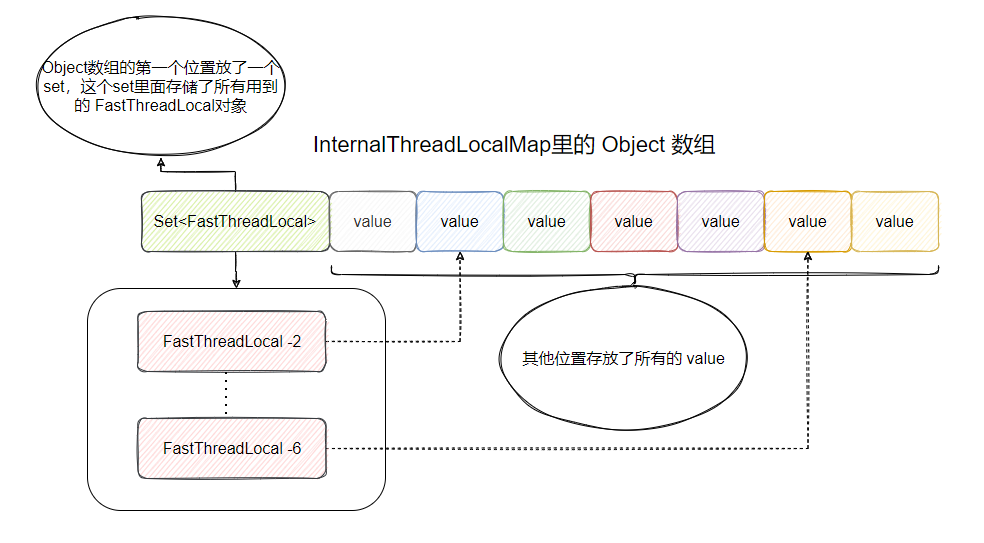
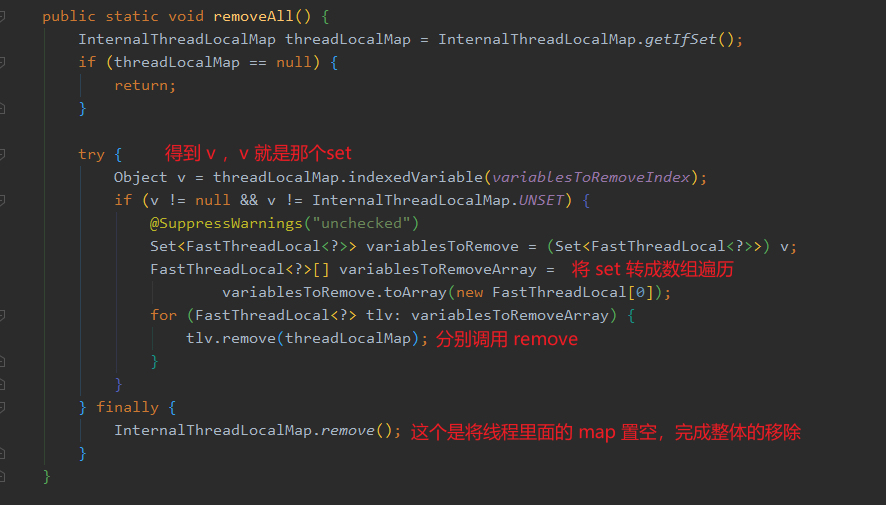
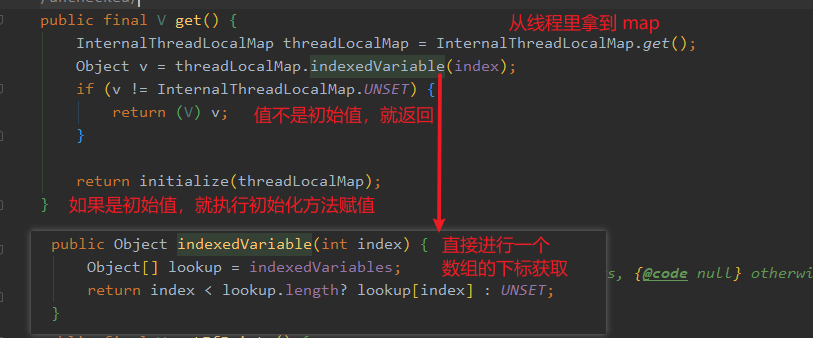
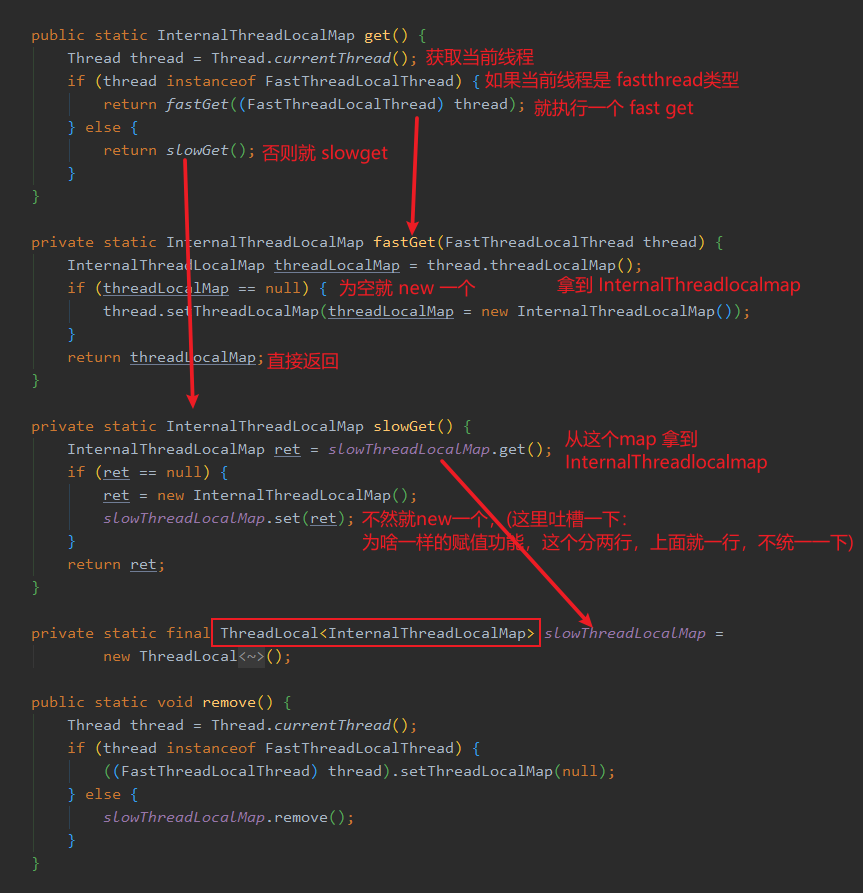
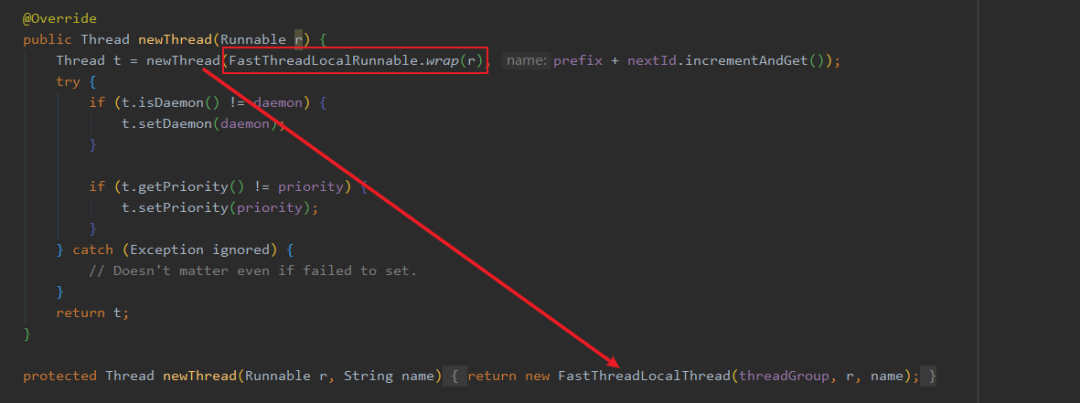
InternalThreadLocalMap.get(),这里面做了一个兼容。不过我要先介绍一下 FastThreadLocalThread ,就是这玩意替代了 Thread。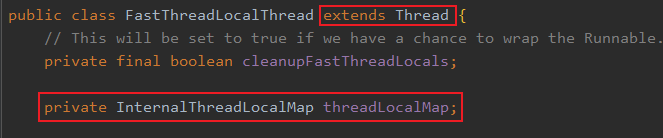
FastThreadLocal<String> threadLocal = new FastThreadLocal<String>();
Thread t = new FastThreadLocalThread(new Runnable() { //记得要 new FastThreadLocalThread
public void run() {
threadLocal.get();
....
}
});
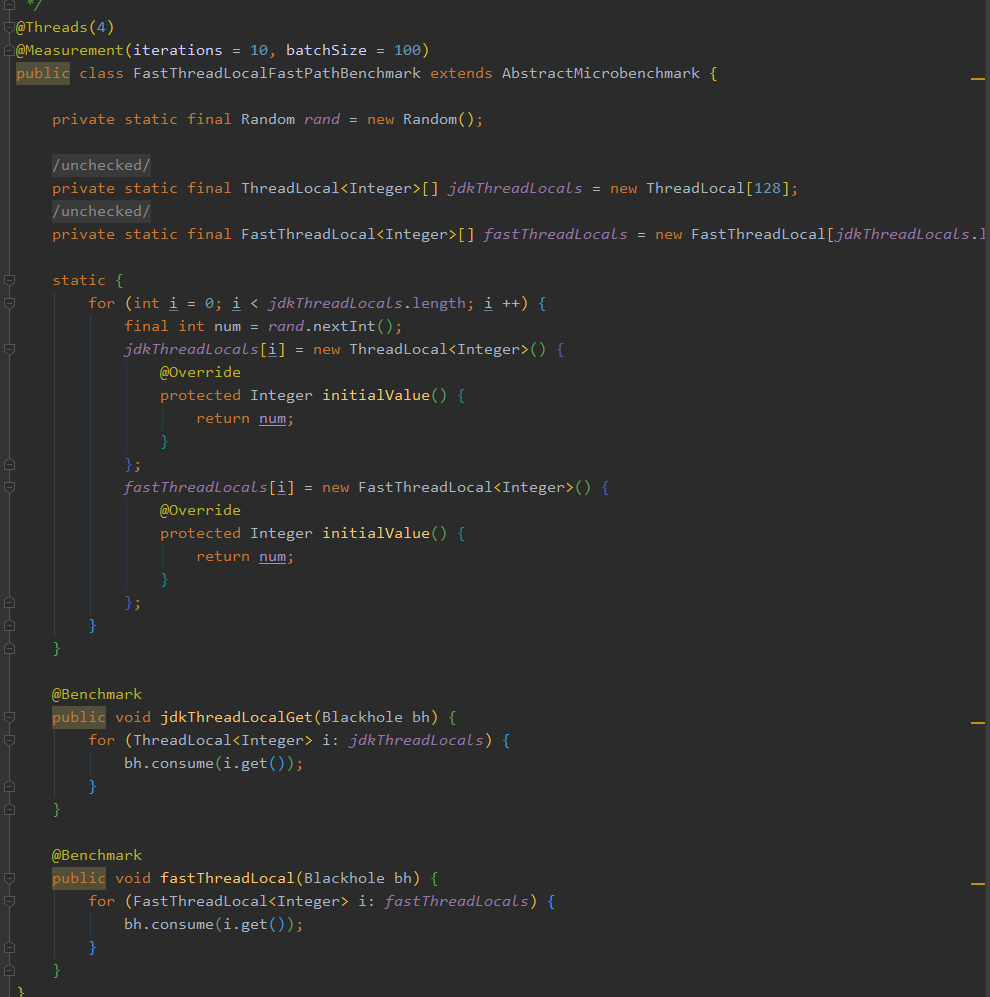
FastThreadLocal VS ThreadLocal



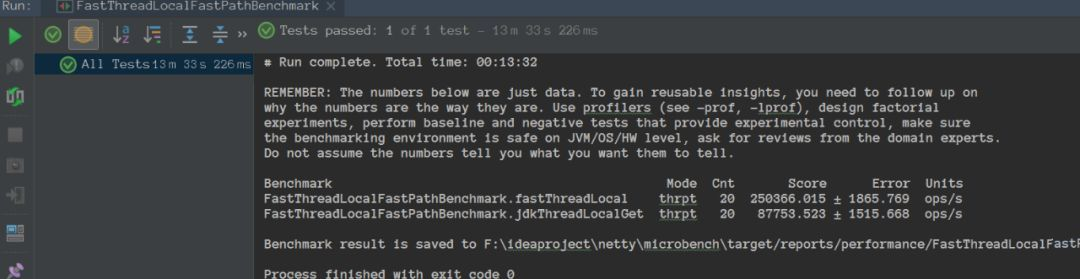
最后
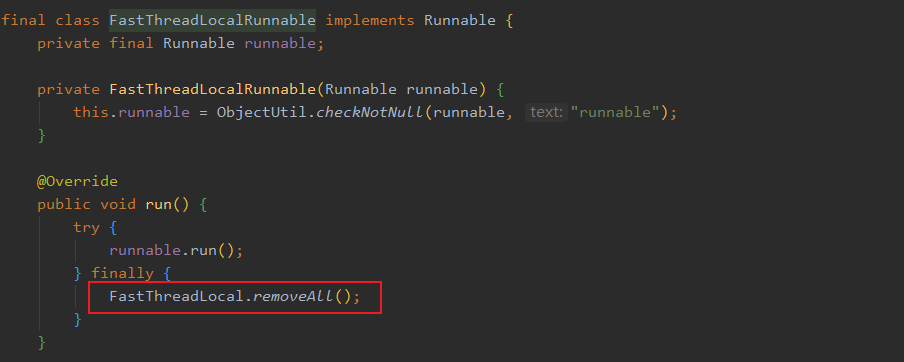
FastThreadLocal 通过分配下标直接定位 value ,不会有 hash 冲突,效率较高。 FastThreadLocal 采用空间换时间的方式来提高效率。 FastThreadLocal 需要配套 FastThreadLocalThread 使用,不然还不如原生 ThreadLocal。 FastThreadLocal 使用最好配套 FastThreadLocalRunnable,这样执行完任务后会主动调用 removeAll 来移除所有 FastThreadLocal ,防止内存泄漏。 FastThreadLocal 的使用也是推荐用完之后,主动调用 remove。

有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论