
GPT-5出世,需5万张H100!全球H100总需求43万张, 英伟达GPU陷短缺风暴
【导读】GPT-5的训练,需要5万张H100加持。英伟达GPU已成为各大AI公司开发大模型的首选利器。然而,Sam Altaman自曝GPU很缺,竟不希望太多人用ChatGPT。
「谁将获得多少H100,何时获得H100,都是硅谷中最热门的话题。」
OpenAI联合创始人兼职科学家Andrej Karpathy近日发文,阐述了自己对英伟达GPU短缺的看法。

近来,社区广为流传的一张图「我们需要多少张GPU」,引发了众多网友的讨论。

根据图中内容所示:
– Inflection使用了3500和H100,来训练与GPT-3.5能力相当的模型
另外,根据马斯克的说法,GPT-5可能需要30000-50000个H100。
此前,摩根士丹利曾表示GPT-5使用25000个GPU,自2月以来已经开始训练,不过Sam Altman之后澄清了GPT-5尚未进行训。
不过,Altman此前表示,
我们的GPU非常短缺,使用我们产品的人越少越好。
如果人们用的越少,我们会很开心,因为我们没有足够的GPU。

在这篇名为「Nvidia H100 GPU:供需」文章中,深度剖析了当前科技公司们对GPU的使用情况和需求。
文章推测,小型和大型云提供商的大规模H100集群容量即将耗尽,H100的需求趋势至少会持续到2024年底。

那么,GPU需求真的是遇到了瓶颈吗?
各大公司GPU需求:约43万张H100
当前,生成式AI爆发仍旧没有放缓,对算力提出了更高的要求。
一些初创公司都在使用英伟达昂贵、且性能极高的H100来训练模型。
马斯克说,GPU在这一点上,比药物更难获得。
Sam Altman说,OpenAI受到GPU的限制,这推迟了他们的短期计划(微调、专用容量、32k上下文窗口、多模态)。

Karpathy 发表此番言论之际,大型科技公司的年度报告,甚至都在讨论与GPU访问相关的问题。
上周,微软发布了年度报告,并向投资者强调,GPU是其云业务快速增长的「关键原材料」。如果无法获得所需的基础设施,可能会出现数据中心中断的风险因素。

这篇文章据称是由HK发帖的作者所写。

他猜测,OpenAI可能需要50000个H100,而Inflection需要22,000个,Meta可能需要 25k,而大型云服务商可能需要30k(比如Azure、Google Cloud、AWS、Oracle)。
Lambda和CoreWeave以及其他私有云可能总共需要100k。他写道,Anthropic、Helsing、Mistral和Character 可能各需要10k。
作者表示,这些完全是粗略估计和猜测,其中有些是重复计算云和从云租用设备的最终客户。

整体算来,全球公司需要约432000张H100。按每个H100约35k美元来计算,GPU总需求耗资150亿美元。
这其中还不包括国内,大量需要像H800的互联网公司。
还有一些知名的金融公司,比如Jane Street、JP Morgan、Two Sigma等,每家都在进行部署,从数百张A/H100开始,扩展到数千张A/H100。

包括OpenAI、Anthropic、DeepMind、谷歌,以及X.ai在内的所有大型实验室都在进行大型语言模型的训练,而英伟达的H100是无可替代的。
H100为什么成首选?
H100比A100更受欢迎,成为首选,部分原因是缓存延迟更低和FP8计算。
因为它的效率高达3倍,但成本只有(1.5-2倍)。考虑到整体系统成本,H100的性能要高得多。
从技术细节来说,比起A100,H100在16位推理速度大约快3.5倍,16位训练速度大约快2.3倍。
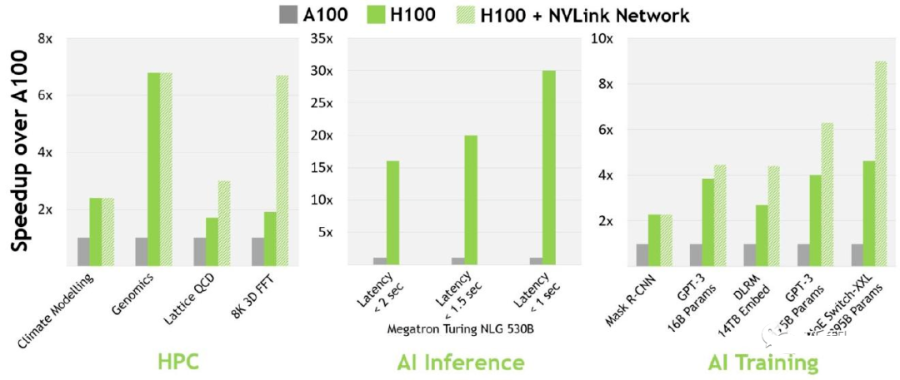
A100 vs H100速度

H100训练MoE
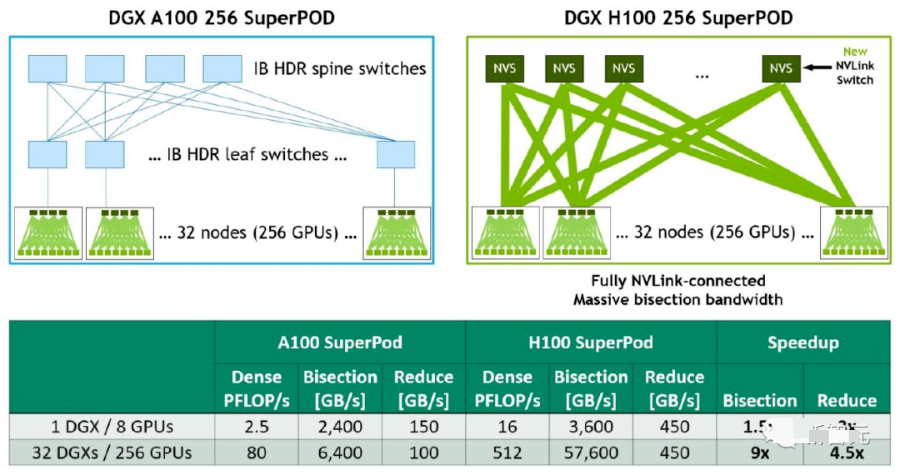
H100大规模加速
大多数公司购买H100,并将其用于训练和推理,而A100主要用于推理。
但是,由于成本、容量、使用新硬件和设置新硬件的风险,以及现有的软件已经针对A100进行了优化,有些公司会犹豫是否要切换。
GPU 并不短缺,而是供应链问题
英伟达的一位高管表示,问题不在于 GPU 短缺,而在于这些 GPU 如何进入市场。
英伟达正在正在开足马力生产GPU,但是这位高管称,GPU的产能最主要受到的是供应链的限制。
芯片本身可能产能充足,但是其他的组件的产能不足会严重限制GPU的产能。
这些组件的生产要依赖整个世界范围内的其他供应商。
不过需求是可以预测的,所以现在问题正在逐渐得到解决。
GPU芯片的产能情况
首先,英伟达只与台积电合作生产H100。英伟达所有的5nmGPU都只与台积电合作。

未来可能会与英特尔和三星合作,但是短期内不可能,这就使得H100的生产受到了限制。
根据爆料者称,台积电有4个生产节点为5nm芯片提供产能:N5,N5P,N4,N5P
而H100只在N5或者是N5P的中的4N节点上生产,是一个5nm的增强型节点。
而英伟达需要和苹果,高通和AMD共享这个节点的产能。
而台积电晶圆厂需要提前12个月就对各个客户的产能搭配做出规划。
如果之前英伟达和台积电低估了H100的需求,那么现在产能就会受到限制。
而爆料者称,H100到从生产到出厂大约需要半年的时间。
而且爆料者还援引某位退休的半导体行业专业人士的说法,晶圆厂并不是台积电的生产瓶颈,CoWoS(3D堆叠)封装才是台积电的产能大门。
H100内存产能
而对于H100上的另一个重要组件,H100内存,也可能存在产能不足的问题。
与GPU以一种特殊方式集成的HBM(High Bandwidth Memory)是保障GPU性能的关键组件。
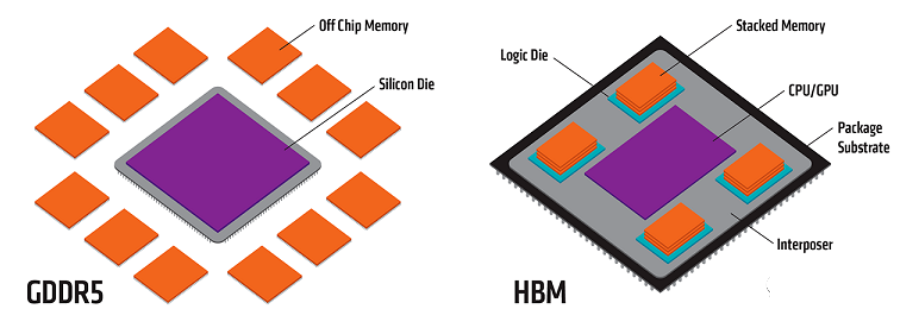
爆料者援引一位业内人士的说法:
主要的问题是 HBM。制造它是一场噩梦。由于 HBM 很难生产,供应也非常有限。生产和设计都必须按照它的节奏来。
HBM3内存,英伟达几乎都是采用SK Hynix的产品,可能会有一部分三星的产品,应该没有镁光的产品。
英伟达希望SK Hynix能提高产能,他们也在这么做。但是三星和镁光的产能都很有限。
而且制造GPU还会用到包括稀土元素在内的许多其他材料和工艺,也会成为限制GPU产能的可能因素。
GPU芯片未来的情况会怎么发展
英伟达的说法
英伟达只是透露,下半年他们能够供应更多的GPU,但是没有提供任何定量的信息。
我们今天正在处理本季度的供应,但我们也为下半年采购了大量供应。
我们相信下半年的供应量将大大高于上半年。
– 英伟达首席财务官 Colette Kress 在2023年2月至4月的财报电话会议上透露
接下来会发生什么?
GPU的供应问题现在是一个恶性循环,稀缺性导致GPU拥有量被视为护城河,从而导致更多的GPU被囤积起来,从而加剧稀缺性。
– 某私有云负责人透露
H100的下一代产品何时会出现?
根据英伟达之前的线路图,H100的下一代产品要在2024年末到2025年初才会宣布。
在那个时间点之前,H100都会是英伟达的旗舰产品。
不过英伟达在此期间内会推出120GB水冷版的H100。
而根据爆料者采访到的业内人士称,到2023年底的H100都已经卖完了!!
如何获得H100的算力?
就像前边英伟达的高管提到的,H100的GPU所提供的算力,最终要通过各个云计算提供商整合到产业链中去,所以H100的短缺,一方面是GPU生成造成的。
另一个方面,是算力云提供商怎么能有效地从英伟达获得H100,并通过提供云算力最终触及需要的客户。
这个过程简单来说是:
算力云提供商向OEM采购H100芯片,再搭建算力云服务出售给各个AI企业,使得最终的用户能够获得H100的算力。
而这个过程中同样存在各种因素,造成了目前H100算力的短缺,而爆料的文章也提供了很多行业内部的信息供大家参考。
H100的板卡找谁买?
戴尔,联想,HPE,Supermicro和广达等OEM商家都会销售H100和HGX H100。
像CoreWeave和Lambda这样的GPU云提供商从OEM厂家处购买,然后租给初创公司。
超大规模的企业(Azure、GCP、AWS、Oracle)会更直接与英伟达合作,但也会向OEM处购买。这和游戏玩家买显卡的渠道似乎也差不多。但即使是购买DGX,用户也需要通过OEM购买,不能直接向英伟达下订单。
交货时间
8-GPU HGX 服务器的交付时间很糟糕,4-GPU HGX 服务器的交付时间就还好。
但是每个客户都想要 8-GPU 服务器!
初创公司是否从原始设备制造商和经销商处购买产品?
初创公司如果要获得H100的算力,最终不是自己买了H100插到自己的GPU集群中去。
他们通常会向Oracle等大型云租用算力,或者向Lambda和CoreWeave等私有云租用,或者向与OEM和数据中心合作的提供商(例如 FluidStack)租用。

如果想要自己构建数据中心,需要考虑的是构建数据中心的时间、是否有硬件方面的人员和经验以及资本支出是否能够承担。
租用和托管服务器已经变得更加容易了。如果用户想建立自己的数据中心,必须布置一条暗光纤线路才能连接到互联网 - 每公里 1 万美元。大部分基础设施已经在互联网繁荣时期建成并支付了费用。租就行了,很便宜。
– 某私有云负责人
从租赁到自建云服务的顺序大概是:按需租云服务(纯租赁云服务)、预定云服务、托管云服务(购买服务器,与提供商合作托管和管理服务器)、自托管(自己购买和托管服务器))。
大部分需要H100算力的初创公司都会选择预定云服务或者是托管云服务。
大型云计算平台之间的比较
而对于很多初创公司而言,大型云计算公司提供的云服务,才是他们获得H100的最终来源。
云平台的选择也最终决定了他们能否获得稳定的H100算力。
总体的观点是:Oracle 不如三大云可靠。但是Oracle会提供更多的技术支持帮助。
其他几家大型云计算公司的主要差异在于:
网络:尽管大多数寻求大型 A100/H100 集群的初创公司都在寻求InfiniBand,AWS 和 Google Cloud 采用InfiniBand的速度较慢,因为它们用了自己的方法来提供服务。
可用性:微软Azure的H100大部分都是专供OpenAI的。谷歌获取H100比较困难。

因为英伟达似乎倾向于为那些没有计划开发和他竞争的机器学习芯片的云提供更多的H100配额。(这都是猜测,不是确凿的事实。)
而除了微软外的三大云公司都在开发机器学习芯片,来自AWS和谷歌的英伟达替代产品已经上市了,占据了一部分市场份额。
就与英伟达的关系而言,可能是这样的:Oracle和Azure>GCP和AWS。但这只是猜测。
较小的云算力提供商价格会更便宜,但在某些情况下,一些云计算提供商会用算力去换股权。
英伟达如何分配H100
英伟达会为每个客户提供了H100的配额。
但如果Azure说“嘿,我们希望获得10,000个H100,全部给Inflection使用”会与Azure说“嘿,我们希望 获得10,000个H100用于Azure云”得到不同的配额。
英伟达关心最终客户是谁,因此如果英伟达如果对最终的使用客户感兴趣的话,云计算提供平台就会得到更多的H100。
英伟达希望尽可能地了解最终客户是谁,他们更喜欢拥有好品牌的客户或拥有强大血统的初创公司。
是的,情况似乎是这样。NVIDIA 喜欢保证新兴人工智能公司(其中许多公司与他们有密切的关系)能够使用 GPU。请参阅 Inflection——他们投资的一家人工智能公司——在他们也投资的 CoreWeave 上测试一个巨大的 H100 集群。
– 某私有云负责人
结束语
现在对于GPU的渴求既有泡沫和炒作的成分,但是也确实是客观存在的。
OpenAI 等一些公司推出了ChatGPT等产品,这些产品收到了市场的追捧,但他们依然无法获得足够的GPU。
其他公司正在购买并且囤积GPU,以便将来能够使用,或者用来训练一些市场可能根本用不到的大语言模型。这就产生了GPU短缺的泡沫。
但无论你怎么看,英伟达就是堡垒里的绿色国王。

推荐阅读: