
数据增强策略(一)
数据增强汇总仓库
一个强大的数据增强仓库 https://github.com/aleju/imgaug
介绍了大量不同任务的数据增强方法,包括代码和可视化

另一份数据增强的文档是百度深度学习框架 PandlePandle 的介绍 https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/ImageAugment.html

以下详细介绍几种数据增强的策略
Mix up
《mixup: Beyond Empirical Risk Minimization》 https://arxiv.org/abs/1710.09412 《Bag of Tricks for Image Classification with Convolutional Neural Networks》 https://arxiv.org/abs/1812.01187
代码
mix up 在 cifar10 的应用(分类):https://github.com/facebookresearch/mixup-cifar10 可视化 :https://github.com/pascal1129/cv_notes/blob/master/codes/mixup.ipynb
算法原理:
几乎无额外计算开销的情况下稳定提升 1 个百分点的图像分类精度。也可以使用在目标检测上面

对于输入的一个 batch 的待测图片 images,将其和随机抽取的图片进行融合,融合比例为 ,得到混合张量 inputs; 第 1 步中图片融合的比例 是 [0,1] 之间的随机实数,符合 分布 numpy.random.beta (alpha, alpha),相加时两张图对应的每个像素值直接相加,即 将第 1 步中得到的混合张量 inputs 传递给 model 得到输出张量 outpus,随后计算损失函数时,我们针对两个图片的标签分别计算损失函数,然后按照比例 进行损失函数的加权求和,即
不同的 值得到的结果

代码示例
一份简单的代码实现如下:
https://github.com/facebookresearch/mixup-cifar10/blob/master/train.py
这里相当于把输入打乱后的输入进行权重相加
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size) # 打乱索引顺序
mixed_x = lam * x + (1 - lam) * x[index, :] # 这里就相当于不同的两种进行混合
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
Cutout
论文:《Improved Regularization of Convolutional Neural Networks with Cutout》https://arxiv.org/abs/1708.04552
代码:https://github.com/uoguelph-mlrg/Cutout
算法原理
随机的将样本中的部分区域 cut 掉,并且填充 0 像素值,分类的结果不变;

实验结果

CutMix
论文:《CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features》https://arxiv.org/abs/1905.04899
代码:https://github.com/clovaai/CutMix-PyTorch
算法原理
CutMix 是将一部分区域 cut 掉然后随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。进而提高了模型对抗输入破坏的鲁棒性

作者认为 mixup 的缺点是:
Mixup samples suffer from the fact that they are locally ambiguous and unnatural, and therefore confuses the model, especially for localization。
算法基本原理:通过设计一个遮罩 M,它的大小与图片大小一致,每个像素取值为 0 或者 1,然后通过 M 与图 A 进行像素点乘法运算、1-M 与图 B 进行像素点乘法运算,然后两者相加得到一张新的图片。标签类别根据相应比例重新生成。


在大部分任务中均有提升

基于 CutMix 的预训练模型可以在 Pascal VOC 上实现性能提升,但它并不是专门为目标检测器设计的。
参考:https://blog.csdn.net/weixin_38715903/article/details/103999227
Gridmask
论文:《GridMask Data Augmentation》https://arxiv.org/abs/2001.04086
代码:https://github.com/Jia-Research-Lab/GridMask
在不同任务上的效果
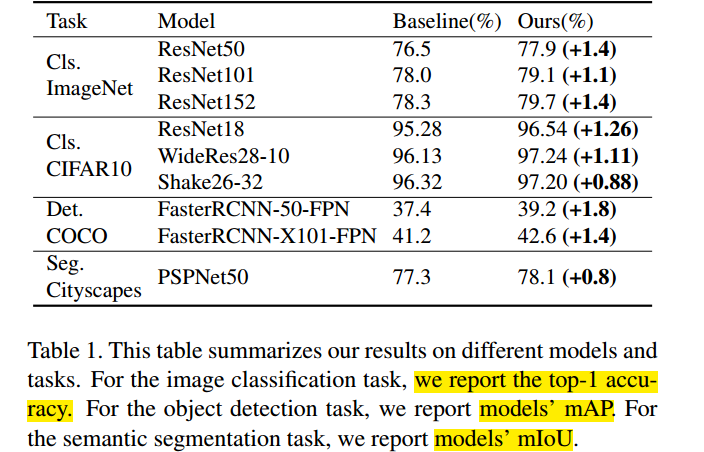
基本原理
Gridmask 的基本原理就是利用一张和原图同样大小的网格蒙版(mask,上面的值只有 0 和 1)并随机对蒙版进行翻转,然后与原图进行相乘,得到最终的结果。
该方法类似于正则化的效果,如果蒙版上 1 的数量较多,也就是保持信息的比例较大,那么模型有可能存在过拟合的风险,反之,若保持信息的比例较少,则存在欠拟合的风险。

这种数据增强的方法有 4 个参数 ,其物理意义如下:
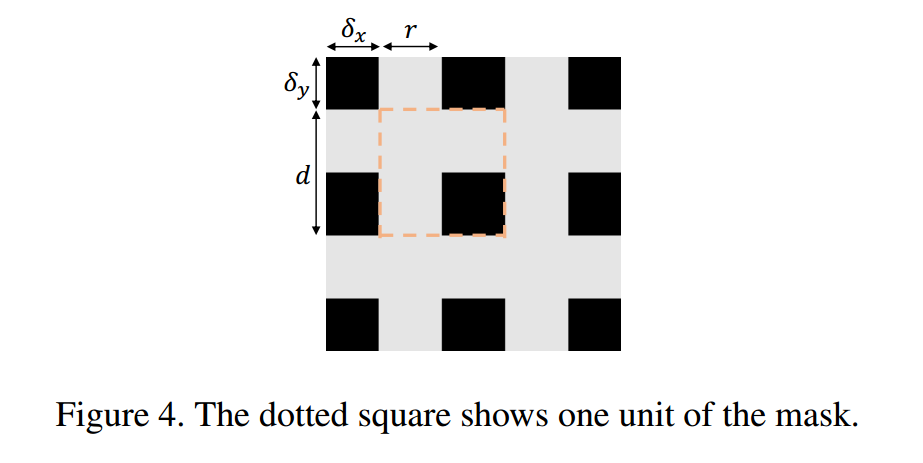
参考:https://zhuanlan.zhihu.com/p/103992528
Mosaic

Mosaic 是 YOLOv4 提出的一种数据增强方法,在 Cutmix 中我们组合了两张图像,而在 Mosaic 中我们使用四张训练图像按一定比例组合成一张图像,使模型学会在更小的范围内识别对象。其次还有助于显著减少对 batch-size 的需求。
参考:https://mp.weixin.qq.com/s/Cl_BCkRVABXsBnZd9siJtw
Label Smoothing
论文:https://arxiv.org/abs/1512.00567
算法原理
Label Smoothing 是在论文《Rethinking the Inception Architecture for Computer Vision》中提到的一种对于输出进行正则化的方法。核心就是对 label 进行 soft 操作,不要给 0 或者 1 的标签,而是有一个偏移,相当于在原 label 上增加噪声,让模型的预测值不要过度集中于概率较高的类别,把一些概率放在概率较低的类别。
对于一个 K 分类的模型,输入 x,模型计算类别为 k 的概率为
假设真实分布为 ,则交叉熵损失函数为
最小化交叉熵等价最大化似然函数。交叉熵函数对逻辑输出求导
正常情况下,如果实际的标签 y=k (第 k 类),那么 ,那么为了使损失尽量小, p (k) 必须要尽量接近于 1,那么模型对于结果预测会更加自信。这就会导致两个问题
1、over-fitting 2、使得损失函数对逻辑输出的导数差异变大,降低了模型的适应能力。
为了避免模型过于自信,引入一个独立于样本分布的变量
实验中使用均匀分布代替 ,即
参考:https://www.cnblogs.com/pprp/p/12771430.html
机器视觉 CV
与你分享 AI 和 CV 的乐趣
分享数据集、电子书、免费GPU
长按二维码关注我们