
微服务下的数据架构
架构之美
共 6988字,需浏览 14分钟
·
2022-01-04 14:01

微服务定义 微服务的优势及架构特点 微服务架构下的数据设计 选择一个合适的数据库
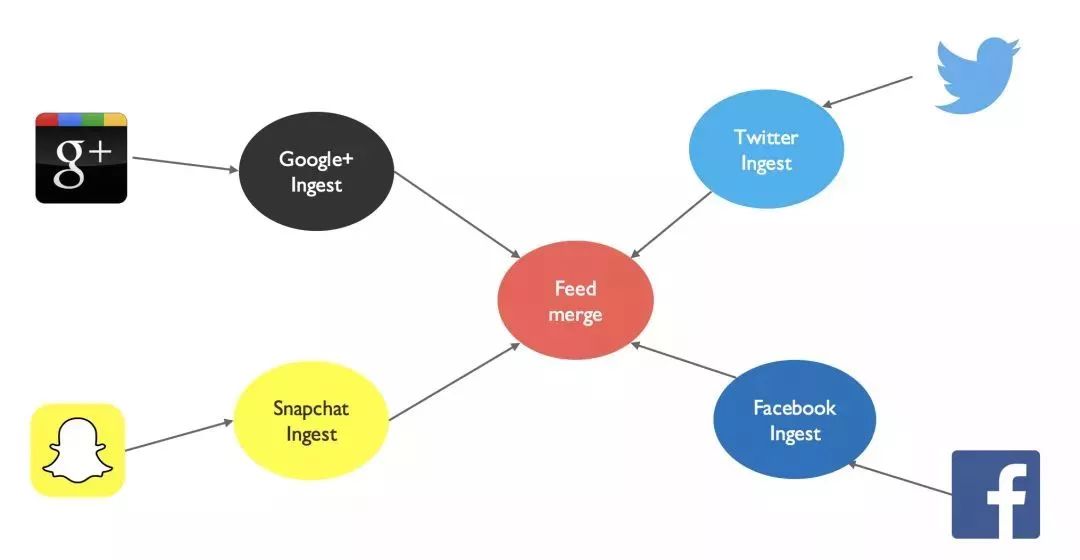
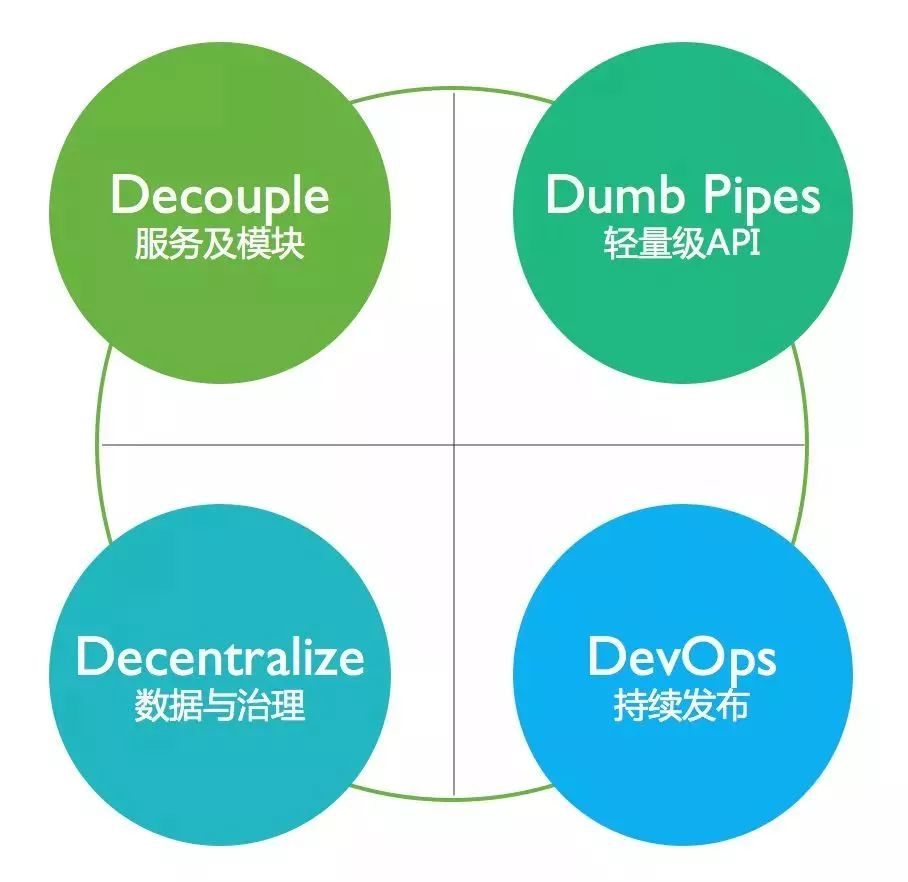
DevOps 持续集成
Decentralized 去中心数据治理
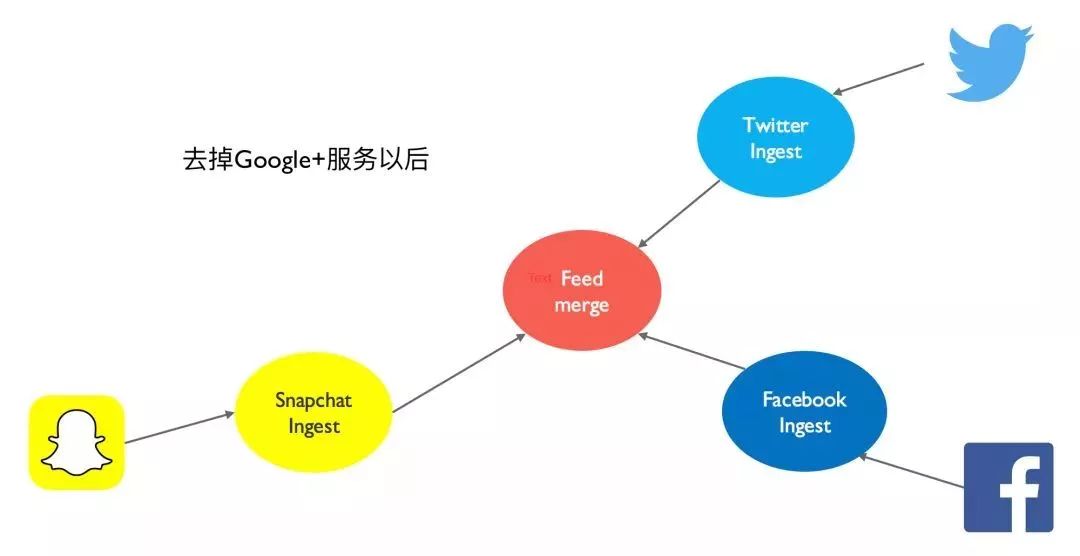
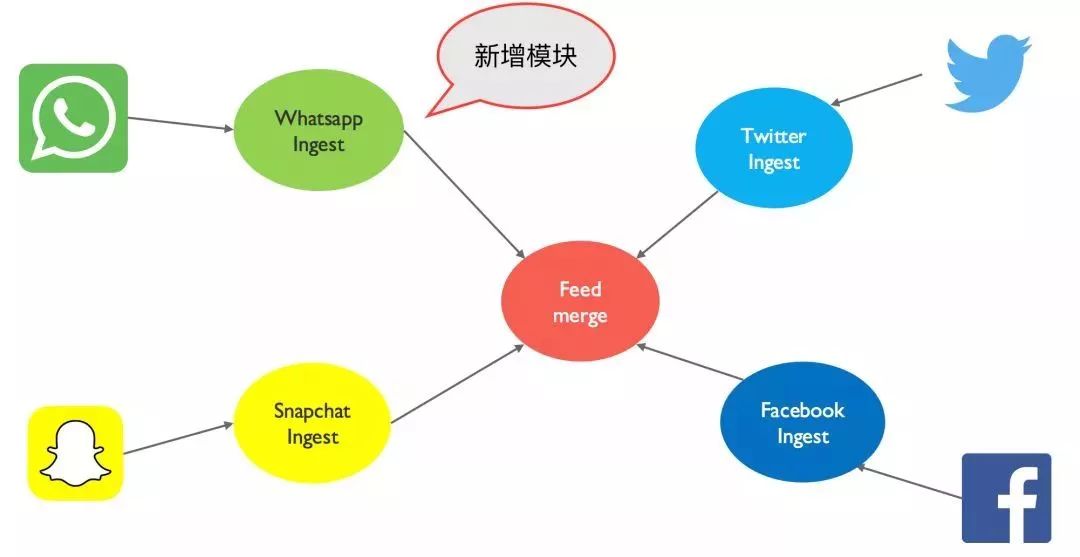
这么多微服务之间,我是否可以用一个数据库,还是多个数据库来支持多个微服务? 如果是多个数据库,我是否为每一个微服务挑选一个最合适的数据库,还是选择同一种类型的数据库? 我如何在微服务架构下扩展我的数据库? 当一个我依赖的服务需要修改数据库 Schema 的时候,是否会影响到我? 当微服务应用不断衍变的时候,我的数据库是否可以快速的响应应用需求变化?
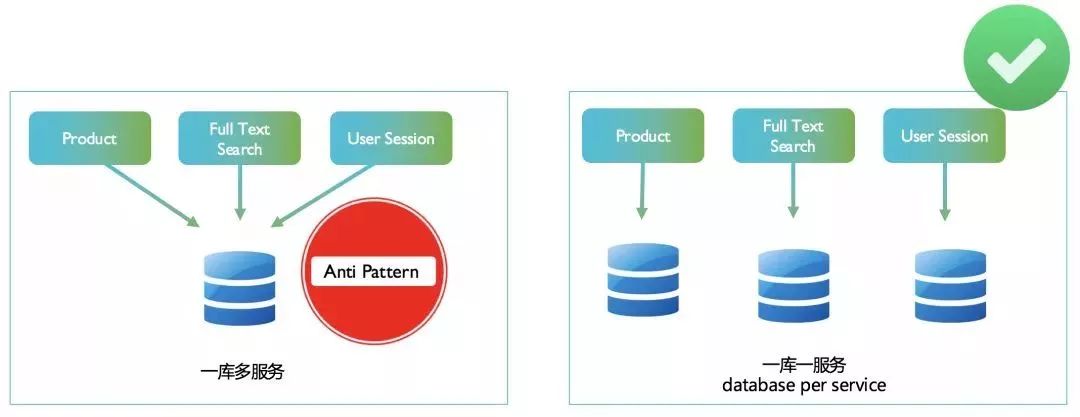
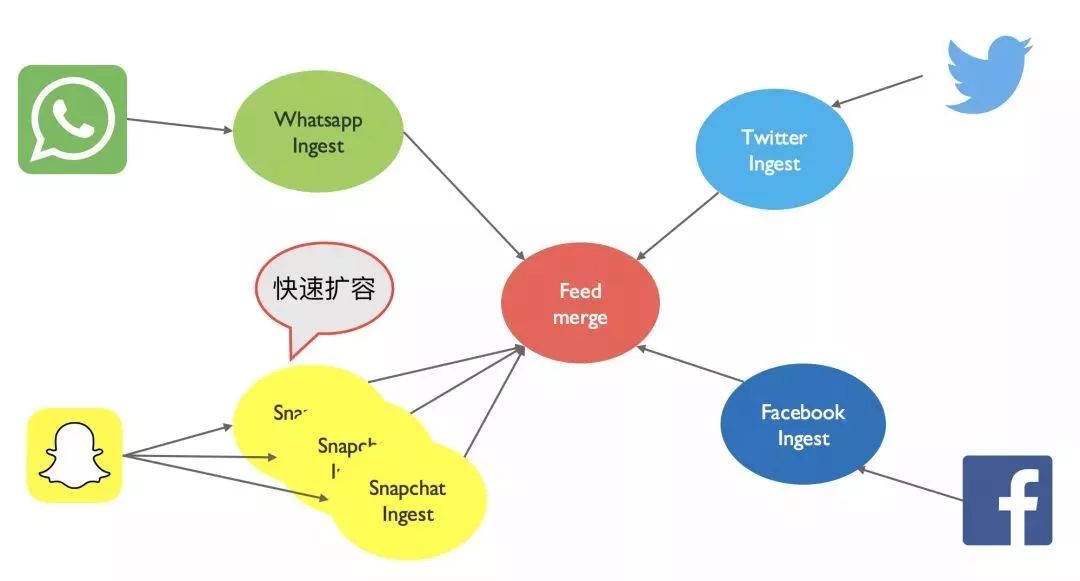
单点故障:一个数据库倒下,整批服务全部停止。何来的服务独立性? 数据在同一个地方,会给贪图方便的开发或者 DBA 工程师编写很多数据间高度依赖的程序或者工具; 无法针对某一个服务进行精准优化或扩展,如上文所讲的 Snapchat 的例子。
混合持久化 - Polyglot Persistence
多模数据库 - Multi-model Database
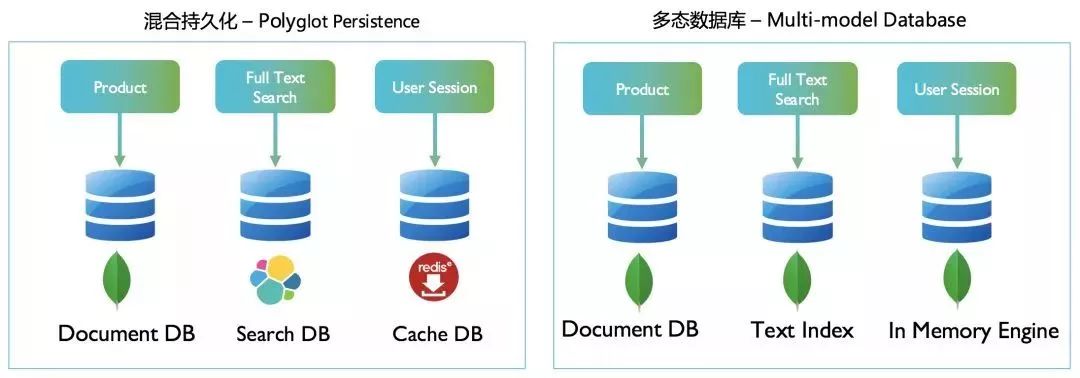
依然是一库一服务(为一个服务部署一个单独的数据库); 但是使用的是同一种类型,支持多种场景的数据库,如 NoSQL 中间为功能最全面的 MongoDB; 虽然是多实例,但是只需维护一种类型的数据库,管理上和人员配备上都较为简单。
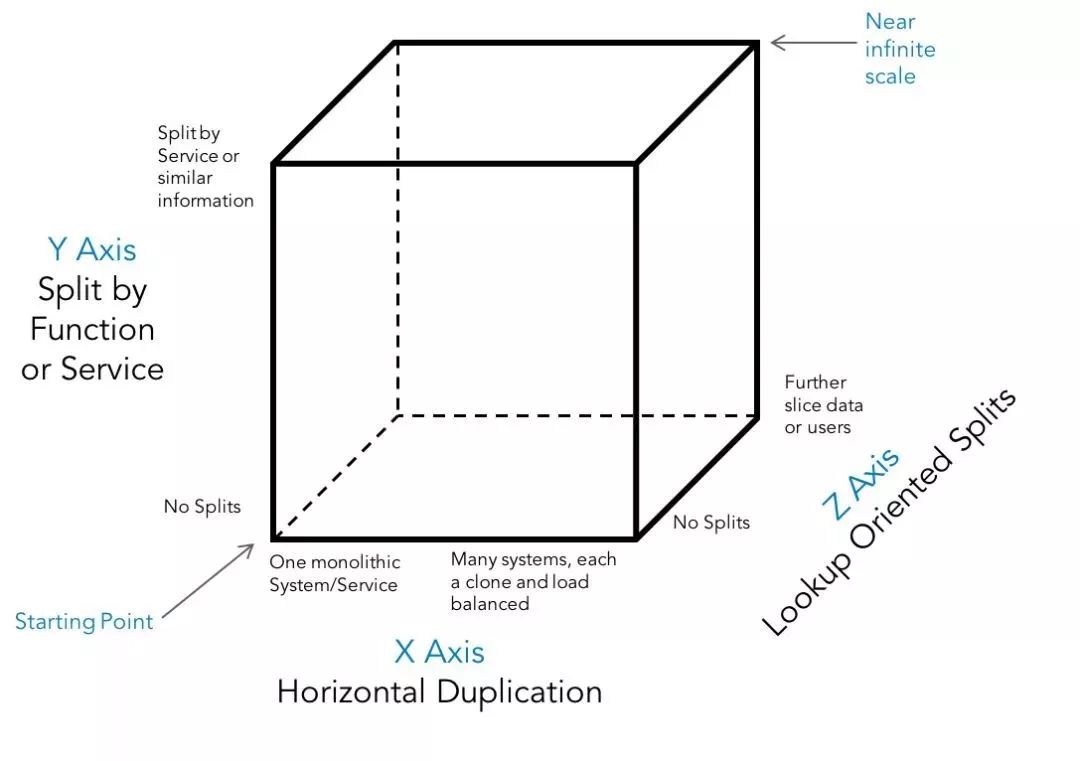
应用数据分区 数据库分区

多模数据库 (Multi-model) 原生 JSON 数据结构 - API 动态模式、无模式 (Dynamic schema / Schemaless) 数据变化流 (Change Stream) 横向扩展能力 (Sharding)
$graphLookup 来实现类似于图数据库的查询 $facet 来实现分面搜索。 内存引擎功能,用于支持类似于 Redis 的高速缓存 全文检索,用于实现搜索类型场景
动态模式
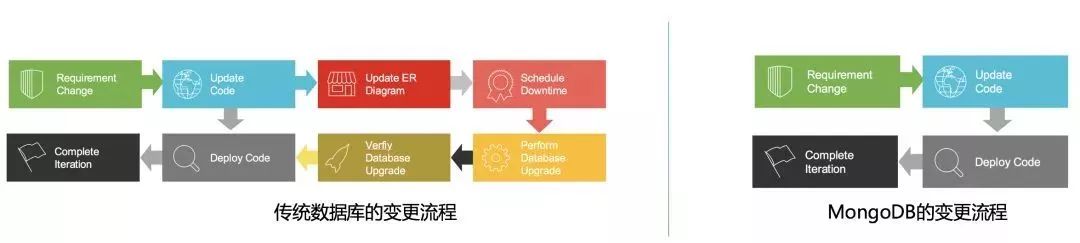
数据更改流
弹性扩展:可以扩容也可以缩容; 无缝扩展:无须停机,就可在线扩容; 自动均衡:无须应用参与即可实现数据的自动均衡,完全透明。

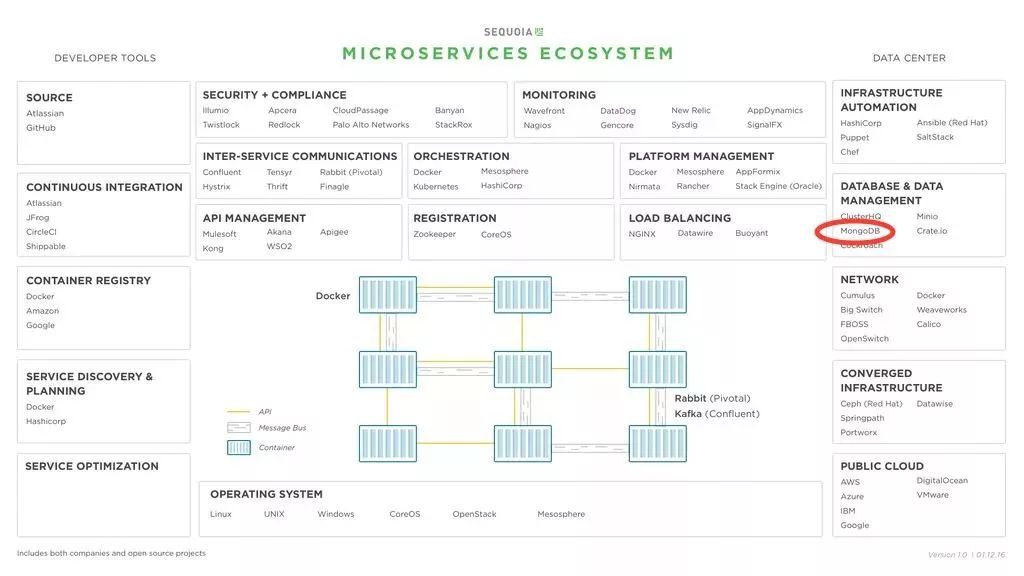
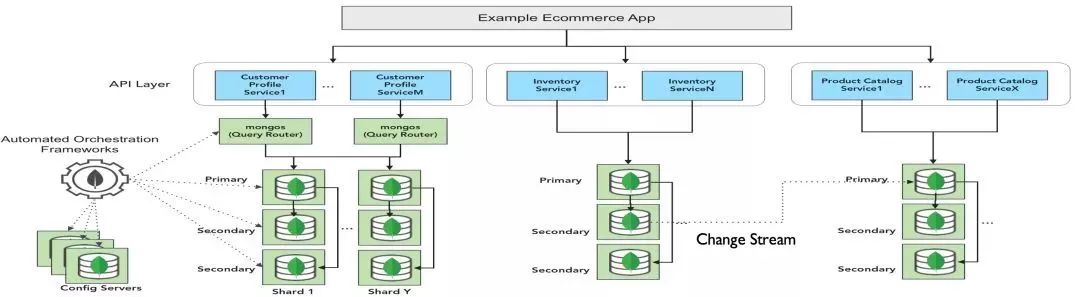
一个基于 MongoDB 的微服务参考架构图
作者:唐建法
来源:Mongoing中文社区

评论