
文生3D模型大突破!MVDream重磅来袭,一句话生成超逼真三维模型
新智元
共 4491字,需浏览 9分钟
·
2023-10-15 06:49

新智元报道
新智元报道
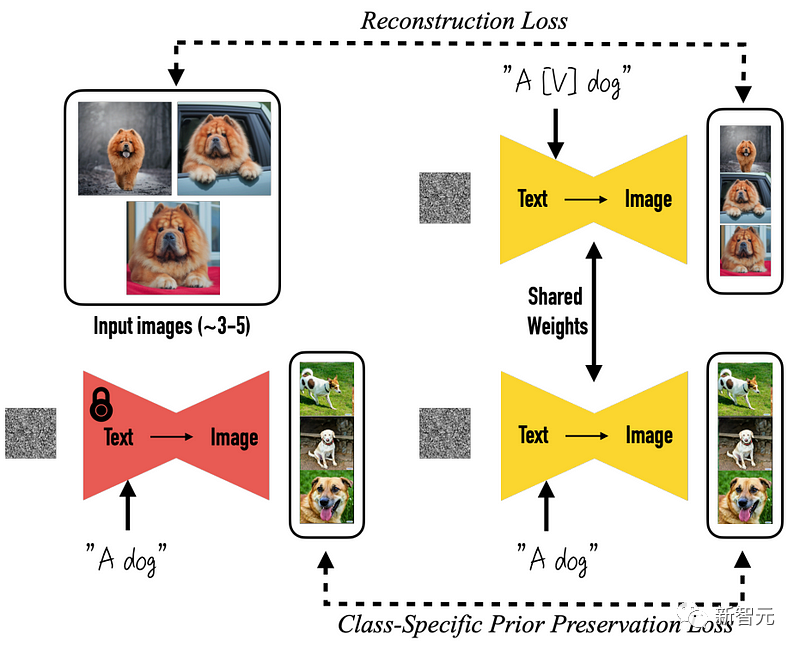
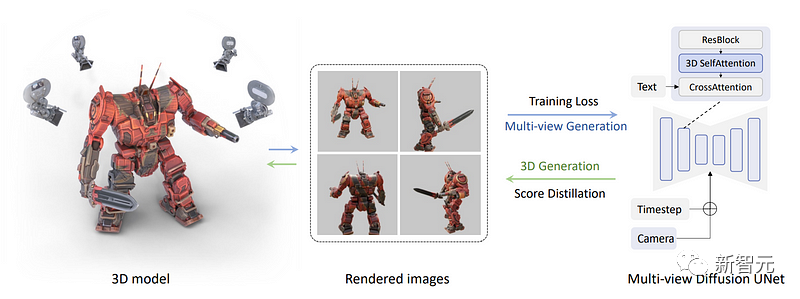
【新智元导读】文生3D模型进步!分数蒸馏采样下的MVDream,真的有这么神奇吗?真的有。

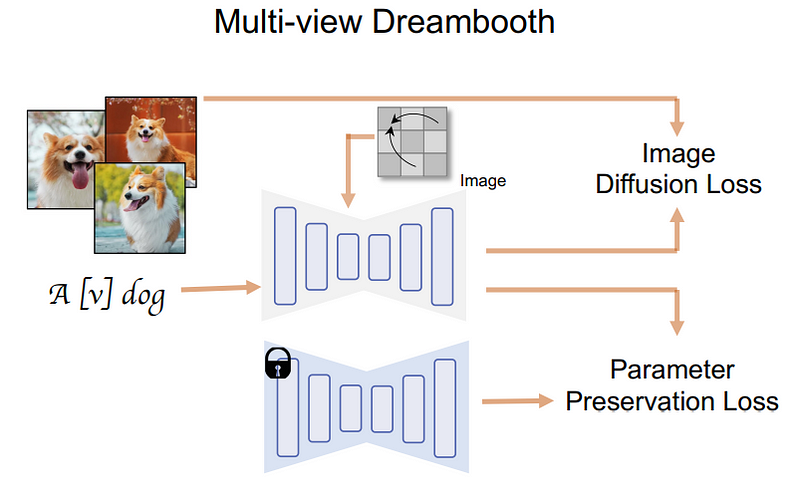
MVDream


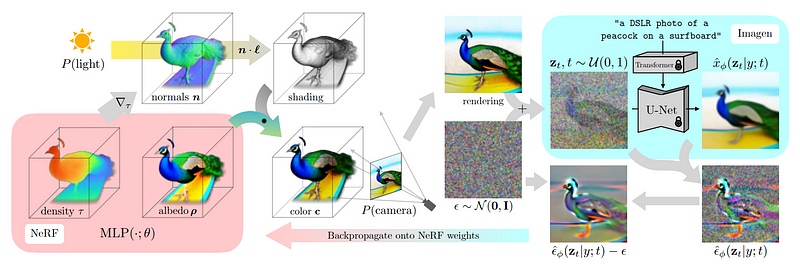
分数蒸馏采样





评论