
主流定时任务解决方案全横评
作者 | 竞霄
定时任务作为一种按照约定时间执行预期逻辑的通用模式,在企业级开发中承载着丰富的业务场景,诸如后台定时同步数据生成报表,定时清理磁盘日志文件,定时扫描超时订单进行补偿回调等。
程序开发人员在定时任务领域有着诸多框架和方案可供选择,并借此快速实现业务功能实现产品上线。本文将就当前主流定时任务解决方案进行介绍和分析,期望可以在企业技术选型和项目架构重构时作为参考。
Crotab
目标定位
Crontab 作为 Linux 内置的可执行命令,可以实现按照 cron 表达式生成的时间执行指定的系统指令或 shell 脚本。
crontab 命令语法:
crontab [-u username] [-l | -e | -r ]参数:-u : 只有root用户才能进行这个任务,编辑某个用户的crontab-e : 编辑 crontab 的工作内容-l : 查阅 crontab 的工作内容-r : 移除所有的 crontab 的工作内容
配置文件示例:
* * * * * touch ~/crontab_test* 3 * * * ~/backup0 */2 * * * /sbin/service httpd restart
实现原理
crond 守护进程是通过 Linux 启动时的 init 进程启动,由 cornd 每分钟会检查/etc/crontab 配置文件中是否有需要执行的任务,并通过 /var/log/cron 文件输出定时任务的执行情况。用户可以使用 Crontab 命令管理/etc/crontab 配置文件。
方案分析
借助 Crontab 用户可以十分便利的快速实现简易的定时任务功能,但存在以下痛点:
定时任务与指定 linux 机器绑定,当机器扩容或者更换时需要重新配置 contab,同时存在单点故障风险
随着定时任务规模增多,无统一视角对其进行任务进度的追踪和管控,难以维护
功能过于简单,没有超时,重试,阻塞等任务高级特性
可观测能力差,问题排查定位困难
任务常驻,当无任务执行时造成不必要的资源成本浪费
Spring Task
目标定位
Spring 框架提供了开箱即用的定时调度功能,用户可以通过 xml 或者 @Scheduled 注解的方式标识指定方法执行的周期。
Spring Task 支持多种任务执行模式,包括带时区配置的 corn,固定延迟,固定速率等。
使用方式
代码实例如下:
@EnableScheduling@SpringBootApplicationpublic class App {public static void main(String[] args) {SpringApplication.run(App.class, args);}}@Componentpublic class MyTask {@Scheduled(cron = "0 0 1 * * *")public void test() {System.out.println("test");}}
实现原理
并在单例 bean 初始化完成后通过 afterSingletonsInstantiated 回调设置 ScheduledTaskRegistrar 中的调度器 TaskScheduler,其底层依赖于 jdk 并发包中的 ScheduledThreadPoolExecutor 实现,并在 afterPropertiesSet 时将所有 Task 添加到 TaskScheduler 中调度执行。
方案分析
借助 Spring Task 用户可以通过注解快速实现对指定方法的周期性执行,支持多种周期性策略。但与 crontab 相似,同样有如下的痛点:
默认为单线程执行,若前一个任务执行时间较长会导致后续任饥饿阻塞,需要用户自行配置线程池
各个节点独立运行,存在单点风险,无分布式协调机制,要考虑禁止并发执行
随着定时任务规模增多,无统一视角对其进行任务进度的追踪和管控,难以维护
功能过于简单,没有超时,重试,阻塞等任务高级特性
可观测能力差,问题排查定位困难
任务常驻,当无任务执行时造成不必要的资源成本浪费
ElasticJob
目标定位
ElasticJob 作为当当网开源的一款分布式任务框架,提供弹性调度,资源管控,作业治理等诸多特性,其已经成为 Apache Shardingsphere 的子项目。
ElasticJob 目前由 2 个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成,ElasticJob-Lite 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务;ElasticJob-Cloud 使用 Mesos 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务。一般使用 ElasticJob-Lite 即可满足需求。
使用者需要在 yaml 中配置注册中心 zk 的地址以及任务的配置信息:
elasticjob:regCenter:serverLists: localhost:6181namespace: elasticjob-lite-springbootjobs:simpleJob:elasticJobClass: org.apache.shardingsphere.elasticjob.lite.example.job.SpringBootSimpleJobcron: 0/5 * * * * ?timeZone: GMT+08:00shardingTotalCount: 3shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
实现对应的接口即可标识对应的任务,同时通过配置监听器来实现任务执行前后回调:
public class MyElasticJob implements SimpleJob {@Overridepublic void execute(ShardingContext context) {switch (context.getShardingItem()) {case 0:// do something by sharding item 0break;case 1:// do something by sharding item 1break;case 2:// do something by sharding item 2break;// case n: ...}}}public class MyJobListener implements ElasticJobListener {@Overridepublic void beforeJobExecuted(ShardingContexts shardingContexts) {// do something ...}@Overridepublic void afterJobExecuted(ShardingContexts shardingContexts) {// do something ...}@Overridepublic String getType() {return "simpleJobListener";}}
ElasticJob 底层时间调度基于 Quartz,Quartz 需要持久化业务 Bean 到底层数据表中,系统侵入性相当严重,同时通过 db 锁进行任务抢占,不支持并行调度,不具备可扩展性。
而 ElasticJob 通过数据分片以及自定义分片参数的特性完成了水平扩展,可以将一个任务拆分为 N 个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。比如一个数据库中有 1 亿条数据,需要将这些数据读取出来并进行计算,就可以将这 1 亿条数据划分成 10 个分片,每一个分片读取其中的 1 千万条数据,然后计算后写入数据库。
如果有三台机器执行,A 机器分到分片(0,1,2,9),B 机器分到分片(3,4,5),C 机器分到分片(6,7,8),这也是相比于 Quartz 最显著的优势。
实现上 ElasticJob 使用 zookeeper 作为注册中心进行分布式调度协调以及 leader 节点的选举,通过注册中心的临时节点的变化来感知服务器的增减,每当 leader 节点选举,服务器上下线,分片总数变更时均会触发后续的重新分片,由 leader 节点在下次定时任务触发时进行具体的分片划分,再由各节点从注册中心中获取分片信息,作为任务的运行参数进行执行。
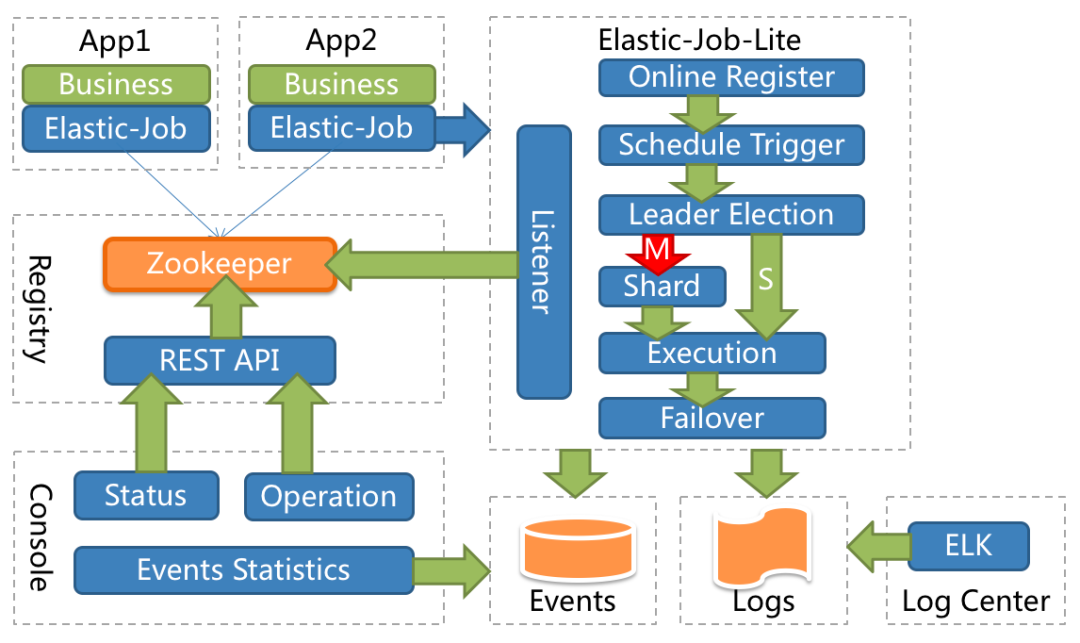
方案分析
ElasticJob 作为分布式任务框架,解决了上述单节点任务无法保证任务执行过程中的高可用和高并发下执行的性能的问题,并支持失败转移(failover)和错过执行的作业重新执行(misfire)等高级机制,但在使用过程中仍存在以下痛点:
框架整体较重,需要依赖外置注册中心zk,增加了至少三台服务器的使用成本和维护复杂度
随着任务量的不断增多,zk 作为有状态中间件将会成为性能瓶颈
可观测能力弱,需要额外引入 db 并配置事件追踪
任务常驻,当无任务执行时造成不必要的资源成本浪费
XXLJob
目标定位
XXLJob 作为大众点评员工开源的一款分布式任务框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
XXLJob 具备丰富的功能,如任务分片广播,超时控制,失败重试,阻塞策略等,并通过体验友好的白屏化控制台对任务进行管理和维护。
XXLJob 分为中心式调度器和分布式执行器两部分组成,在使用时需要分别启动,在调度中心启动时需要配置所依赖的 db 配置。
执行器需要配置调度中心的地址:
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-adminxxl.job.accessToken=xxl.job.executor.appname=xxl-job-executor-samplexxl.job.executor.address=xxl.job.executor.ip=xxl.job.executor.port=9999xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandlerxxl.job.executor.logretentiondays=30
通过 bean 模式方法形式创建任务和前后回调的使用方式如下:
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")public void demoJobHandler() throws Exception {int shardIndex = XxlJobHelper.getShardIndex();int shardTotal = XxlJobHelper.getShardTotal();XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);}public void init(){logger.info("init");}public void destroy(){logger.info("destory");}
创建任务完成后,需要在控制台上配置任务的执行策略:
XXLJob 实现上将调度系统与任务解耦,其自研调度器负责管理调度信息,按照调度配置发出调度请求,支持可视化、简单且动态的管理调度信息,自动发现和路由,调度过期策略,重试策略,支持执行器 Failover。
执行器负责接收调度请求并执行任务逻辑,并接收任务终止请求和日志请求,负责任务超时,阻塞策略等。调度器和执行器通过 restful api 进行通信,调度器本身无状态支持集群部署,提升调度系统容灾和可用性,通过 mysql 维护锁信息和持久化。执行器无状态支持集群部署,提升调度系统可用性,同时提升任务处理能力。
XXLJob 一次完整的任务调度通讯流程:首先调度中心向执行器内嵌 Server 发送 http 调度请求,然后执行器执行对应的任务逻辑,待任务执行完成或超时后执行器发送 http 回调向调度中心返回调度结果。
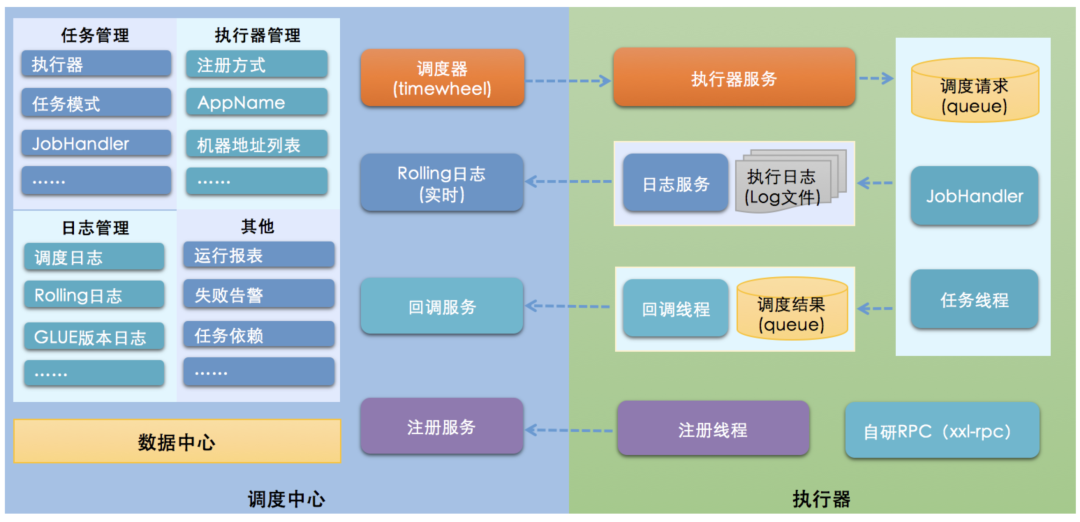
方案分析
XXLJob 在开源社区广泛流行,凭借其简单的操作和丰富的功能已在多家公司投入使用,可以较好的满足生产级别的需求,但下面的一些痛点需要改进:
需要依赖外置 DB,增加了数据库的使用成本和维护复杂度
依赖 DB 锁保证集群分布式调度的一致性,当短时任务量不断增多将对 db 造成较大压力,成为性能瓶颈
相较于无中心模式需要额外部署调度器,调度器和执行器均需要常驻同时为保证高可用均至少两台,当无任务执行时造成不必要的资源成本浪费
Serverless Job
目标定位
Serverless 作为云计算的最佳实践和未来演进趋势,其全托管免运维的使用体验和按量付费的成本优势使得其在云原生时代备受推崇。
SAE (Serverless 应用引擎)Job 作为首款面向任务的 Serverless PaaS 平台,提供传统的用户体验。
当前聚焦支持单机、广播、并行分片模型的任务,同时支持事件驱动、并发策略和超时重试等诸多特性,提供低成本、多规格、高弹性的资源实例来满足短时任务的执行。
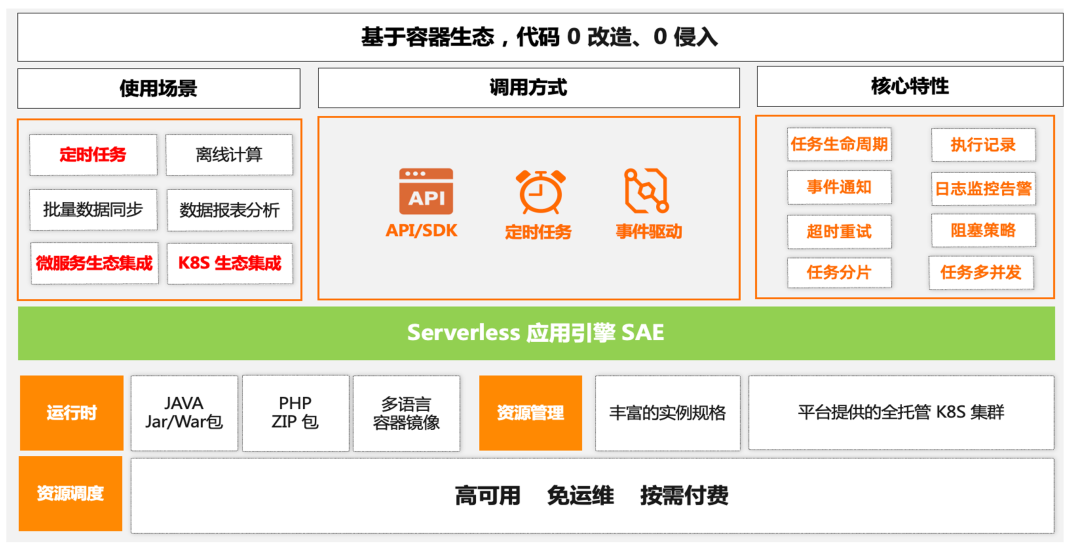
对于使用上述所有方案的存量应用,SAE (Serverless 应用引擎) Job 在兼容功能体验的同时支持零改造无感迁移。
无论用户使用的是 Crontab,Spring Task,还是 ElasticJob, XXLJob,均可将代码包或者镜像直接部署到 SAE (Serverless 应用引擎) Job中,直接升级成为 Serverless 架构, 从而即刻拥有 Serverless 所带来的技术上的优势,节省资源成本和运维成本。
对于运完即停的程序,无论是 Java,还是 Shell,Python,Go,Php 均可以直接部署到 SAE (Serverless 应用引擎) Job 中, 从而即刻拥有白屏化管控,全托管免运维的完备体验以及开箱即用的可观测功能。
SAE (Serverless 应用引擎)Job 底层为多租 Kubernetes,使用神龙裸金属安全容器、VK 对接 ECI 两种方式提供集群计算资源。
用户在 SAE(Serverless 应用引擎)中运行的任务会映射到 Kubernetes 中相应的资源。其中多租能力是借助系统隔离、数据隔离、服务隔离和网络隔离实现租户间的隔离。
SAE (Serverless 应用引擎)Job 通过 Event Bridge 作为事件驱动源,在支持丰富调用方式的同时避免了 Kubernetes 内置定时器不保证准时触发以及精度时区上的问题。
同时不断完善 Job 控制器的企业级特性,新增自定义分片,注入配置,差异化 GC,sidecar 主动退出,实时日志持久化,事件通知等机制。并借助 Java 字节码增强技术接管任务调度,实现通用的 Java 目标框架的零改造 Serverless 化。
使用 KubeVela 软件交付平台作为任务发布和管理的载体,以任务为中心,以开源开放的标准,通过声明式的方式完成整个云原生交付。SAE (Serverless 应用引擎)Job 将持续优化 etcd 以及调度器在短时任务高并发创建场景下的效率以及实例启动的极致弹性能力,结合弹性资源池保证任务调度的低延迟和高可用。
方案分析
SAE (Serverless 应用引擎)Job 解决了上述定时任务解决方案的各种痛点,用户无需关注任务的调度和集群资源,无需部署的额外的运维依赖组件,也无需自建一整套监控告警系统,同时更重要的是无需云主机 7*24h 常驻,在低资源利用率的环境下持续消耗闲置资源。
SAE (Serverless 应用引擎)Job 相较于传统定时任务解决方案提供了三大核心价值:
完备全托管:提供了一站式全托管的管理界面,其任务生命周期管理、可观测性开箱即用,用户可以低心智负担、零成本地学习使用 SAE。
简单免运维:屏蔽了底层资源,用户只需关注其核心的业务逻辑开发,无需操心集群可用性、容量、性能等方面的问题。
超高性价比:采用按需使用、按量付费的模式,只有任务执行业务逻辑时才会拉起收费,其余时间不收取任何费用,极大节省了资源的成本开销。
总结
 戳下方了解更多 SAE Job 的功能优势,和众多开源任务框架“低门槛”迁移的方案!
戳下方了解更多 SAE Job 的功能优势,和众多开源任务框架“低门槛”迁移的方案!