
Scrapy爬了三千张超养眼美女私房照!
文 | 酷头
嗨!大家好,我是酷头
欢迎来到学习python的宝藏基地~~~


Scrapy爬取B站小姐姐入门教程,结果万万没想到!
第二次使用scrapy翻页爬取了糗事百科13页的段子信息Scrapy翻页爬取糗事百科所有段子后,我总结出的...
今天我们使用scrapy爬取美女网92页小姐姐图片,先来看结果:
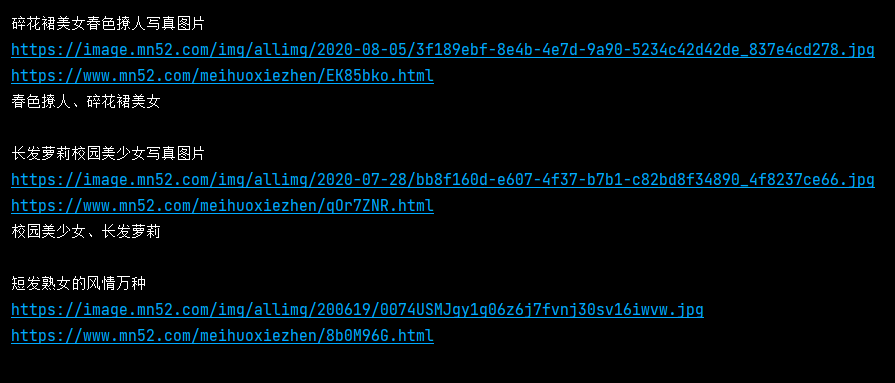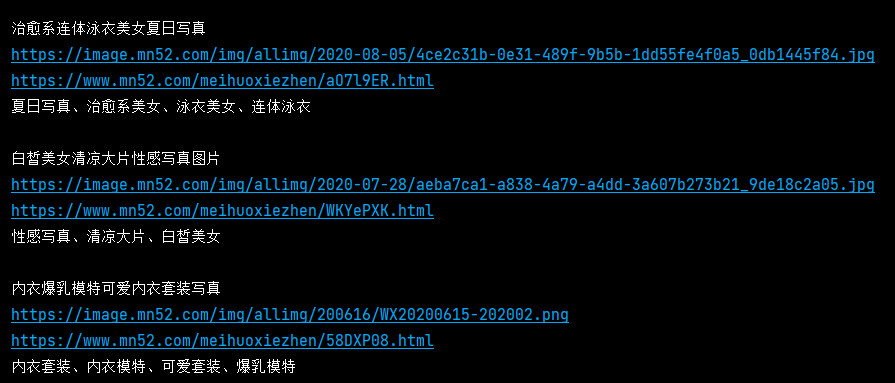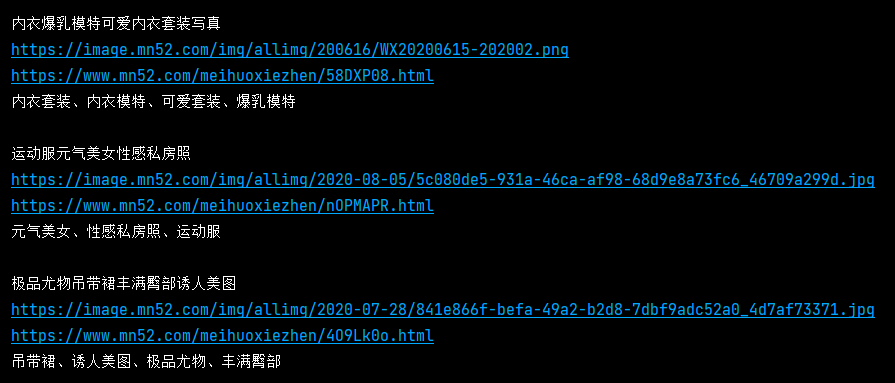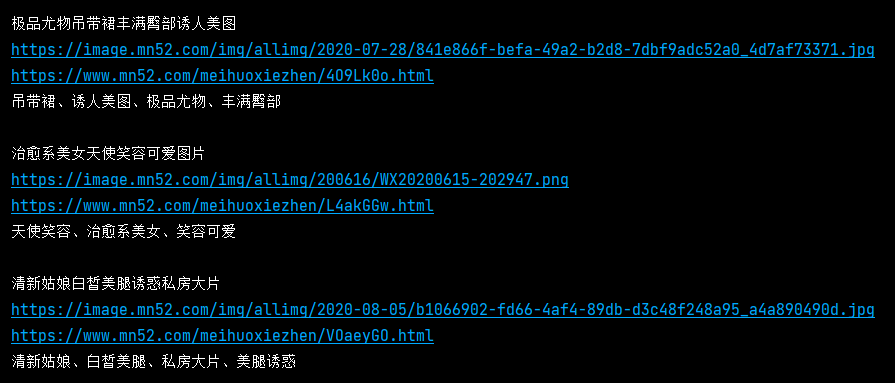

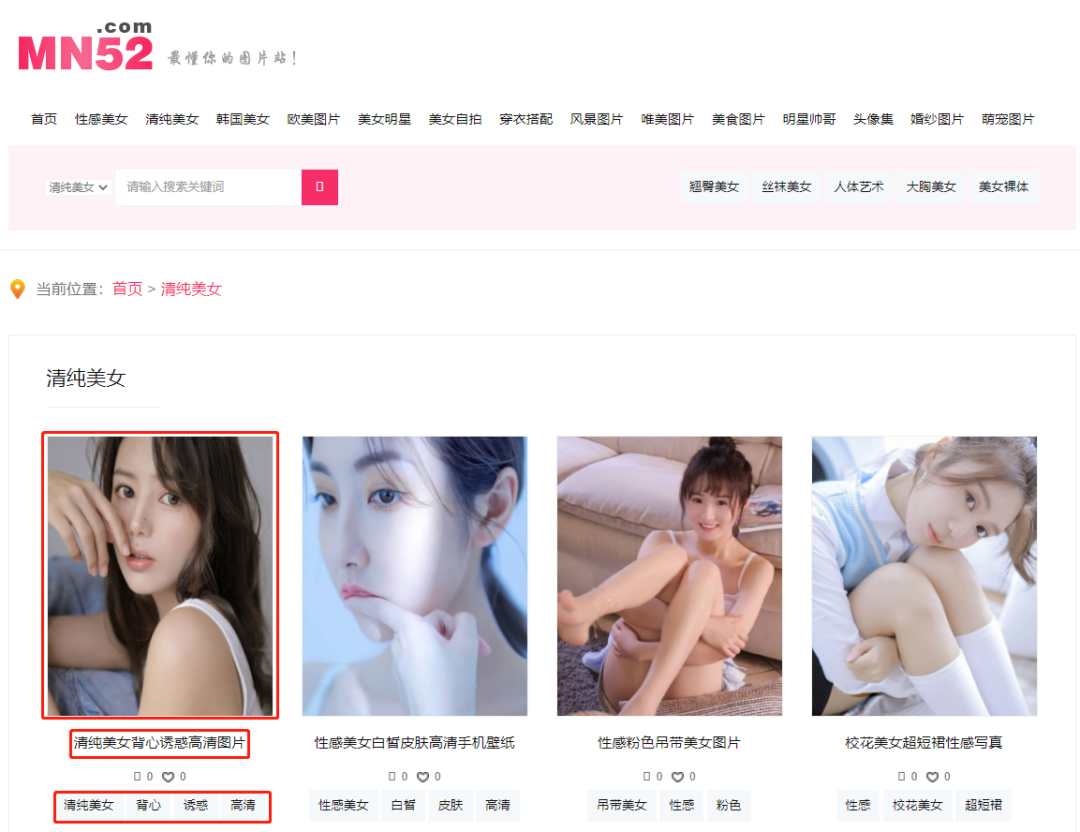
2. 我们使用命令
scrapy startproject mnxz 建立一个名称为mnxz的新工程。如下:


3. 使用命令
scrapy genspider spider_mn https://www.mn52.com/meihuoxiezhen/list_2_1.html创建一个名称为spider_mn 的爬虫文件
4. 工程建立好了接下来咱们来写代码,
首先是咱们的实体类items。获取的数据有四个如下:
pic = scrapy.Field() # 图片内容
url = scrapy.Field() # 图片链接
title = scrapy.Field() # 图片标题
label = scrapy.Field() # 图片标签5. 接下来就在爬虫文件spider_mn来实现具体的爬取。
然后使用yield将数据流向管道文件pipelines中。
# 获取当前页面所有信息
divs = response.xpath("//div[@class='col-md-3 col-sm-6']/div[@class='item-box']")
for div in divs:
item['title'] = div.xpath('./a/@title').get() # 图片标题
pic = div.xpath("./a/div[@class='item-media entry']/img/@src").get()
item['pic'] = 'https:' + pic # 图片信息
url = div.xpath('./a/@href').get()
item['url'] = 'https:' + url # 对应大图链接
label = div.xpath('./div[@class="tags"]/a/text()').getall()
item['label'] = '、'.join(label) # 图片对应标签
yield item6. 在pipeline中对文件进行保存。
一方面我们要保存我们获取到的美女的照片、标题、标签和点击之后对应的图片链接四个数据存放在json文件中;
另一方面我们要将图片单独存放在images文件夹中。
def process_item(self, item, spider):
print(item['title'])
print(item['pic'])
print(item['url'])
print(item['label'] + '\n')
# 保存文件到本地
with open('./beauty_girls.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
if not os.path.exists('images'):
os.mkdir('images')
# 保存图片到本地
with open('images/{}.jpg'.format(item['title']), 'wb') as f:
req = requests.get(item['pic'])
f.write(req.content)
time.sleep(random.random()*4)
return item
7. 接下来我们打开setting进行如下设置:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': str(UserAgent().random)
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'mnxz.pipelines.MnxzPipeline': 300,
}
8. 同样我们最后来运行main文件。可以成功的获取到当前页面数据。
from scrapy import cmdline
cmdline.execute('scrapy crawl spider_mn -s LOG_FILE=all.log'.split())

9. 我们可以看到小姐姐照片总共有92页,
咱们的目标就是全部照片。接下来就是使用循环来获取多页数据了。
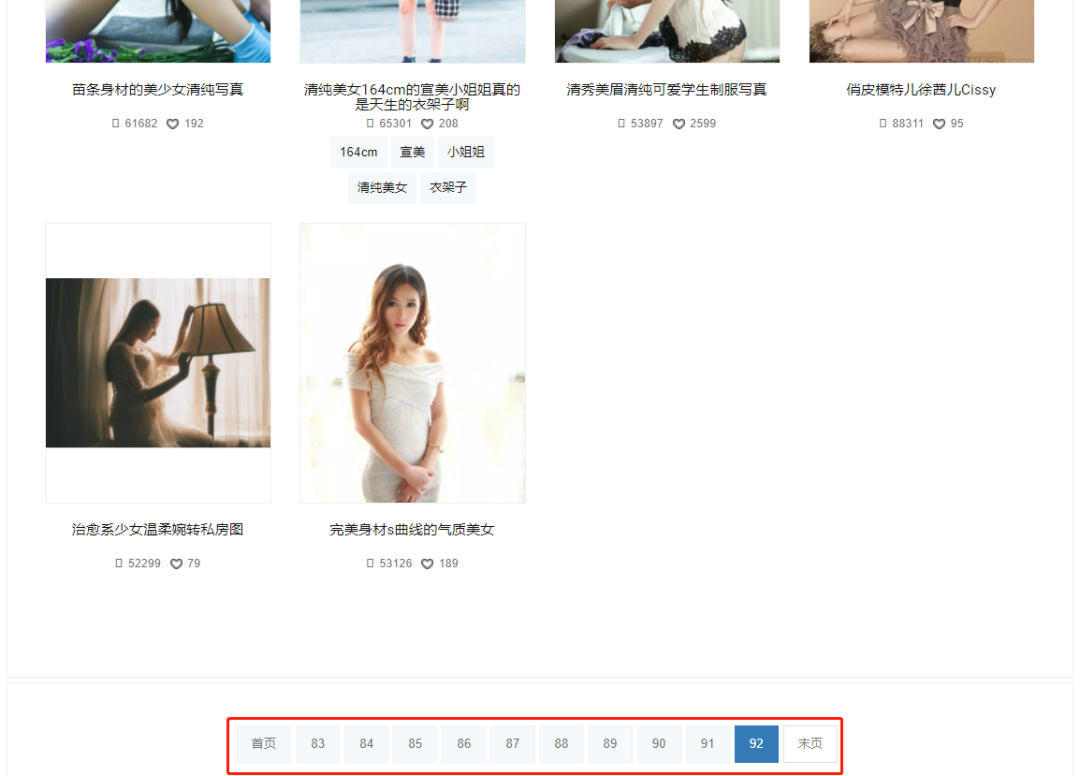
def start_requests(self):
# 获取翻页URL
for page in range(1, 92 + 1):
url = r'https://www.mn52.com/meihuoxiezhen/list_2_{}.html'.format(str(page)) # 提取翻页链接
yield scrapy.Request(url, callback=self.parse, dont_filter=False)


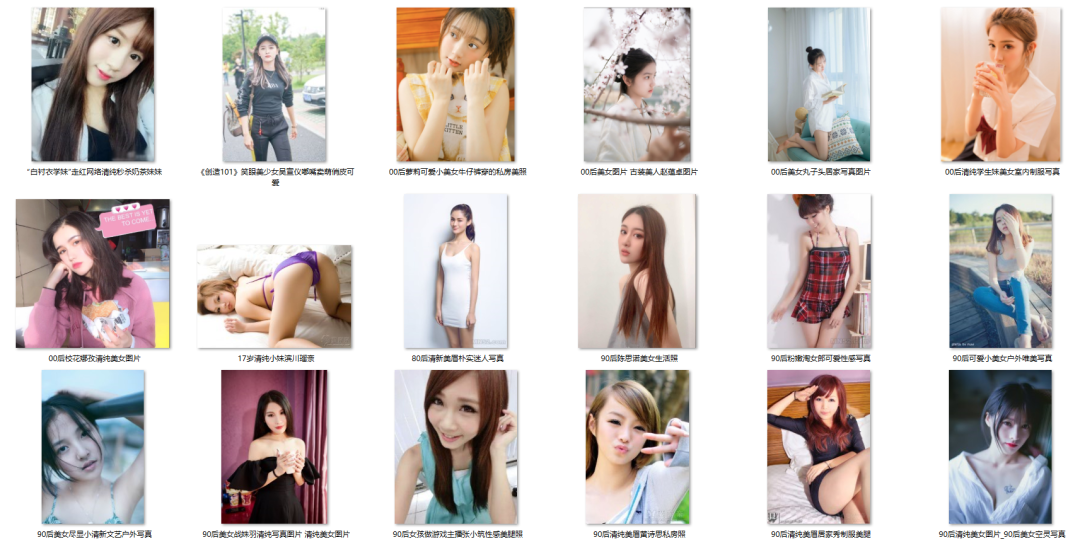
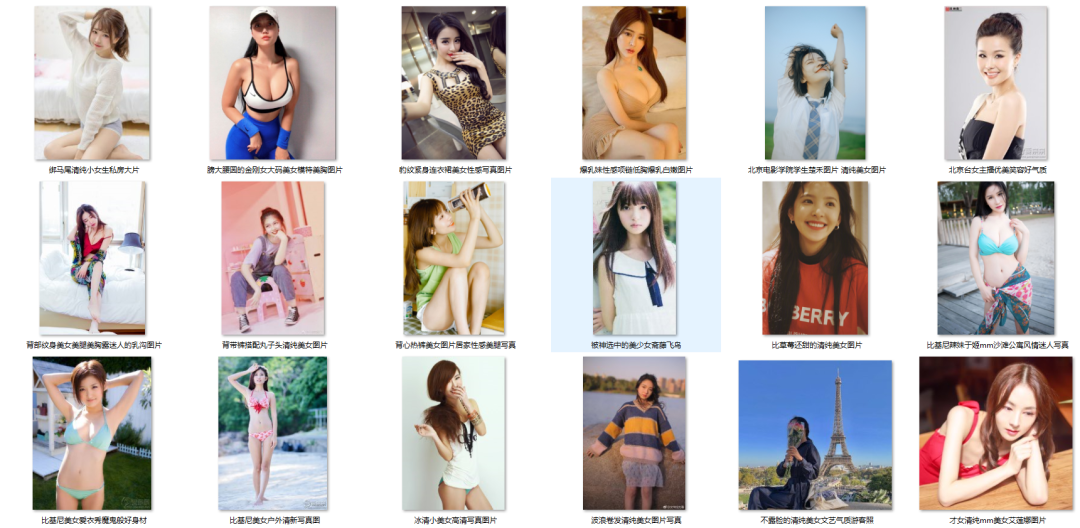
获取到的图片
加入循环之后我们就可以获取到全部小姐姐图片啦
评论