
【NLP】基于预训练的中文NLP工具介绍:ltp 和 fastHan
1. 简介
2. ltp
2.1 工作流程
2.2 demo
2.3 词典分词
2.4 词性标注集
2.5 模型算法
3. fastHan
3.1 模型结构
3.2 demo
3.3 词典分词
3.4 微调模型
3.5 词性标注集
4. 速度对比实验
1. 简介
今天给大家介绍两个中文自然语言处理工具:ltp 和 fastHan,两者都支持基本的中文自然语言处理任务,包括中文分词、词性标注、命名实体识别和依存句法分析等。ltp 是由哈工大社会计算与信息检索研究中心(HIT-SCIR)开源,基于 pytorch 与 transformers 实现的语言技术平台,其内核为基于 Electra 的联合模型。
paper: N-LTP: An Open-source Neural Language Technology Platform for Chinese
link: https://arxiv.org/pdf/2009.11616.pdf
code: https://github.com/HIT-SCIR/ltp
fastHan 是由复旦大学自然语言处理实验室邱锡鹏组研发,基于 fastNLP 与 pytorch 实现的中文自然语言处理工具,其内核为基于 BERT 的联合模型。
paper: fastHan: A BERT-based Multi-Task Toolkit for Chinese NLP
link: https://arxiv.org/pdf/2009.08633v2.pdf
code: https://github.com/fastnlp/fastHan
2. ltp
2.1 工作流程
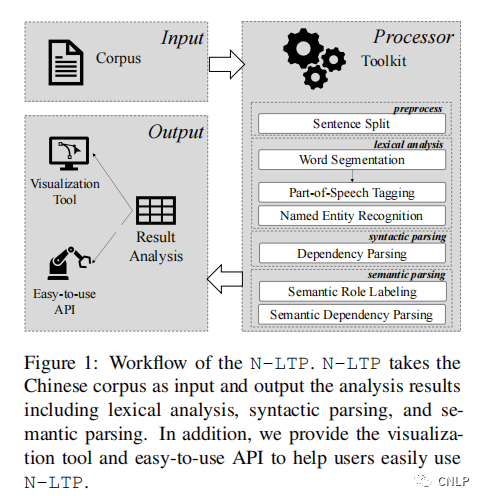
如上为 N-LTP 的工作流程,输入为中文语料库,输出为相对丰富和快速的分析结果,包括词法分析(中文分词、词性标注和命名实体识别),依存句法分析和语义分析(语义依存分析和语义角色标注)等。
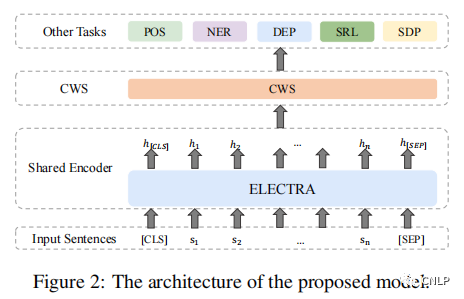
上图展示了 N-LTP 的基本模型结构,主要由一个共享编码器和几个处理不同任务的解码器组成。整个框架共享一个编码器,用于利用在所有任务中共享的知识。每个任务分别使用各自的任务解码器。所有任务通过一个联合学习机制同时进行优化。此外,还引入了知识蒸馏技术,以鼓励多任务模型性能超越其单任务教师模型。
2.2 demo
使用 pip 安装 ltp:
pip install ltp
快速使用:
from ltp import LTP
model = LTP()
# 默认加载 small 模型
# model = LTP(path="small")
# path 可以为下载下来的包含ltp.model和vocab.txt的模型文件夹
# 也可以接受一些已注册可自动下载的模型名:
# base/base1/base2/small/tiny/GSD/GSD+CRF/GSDSimp/GSDSimp+CRF
sent_list = ['俄罗斯总统普京决定在顿巴斯地区开展特别军事行动。']
# 中文分词
seg, hidden = model.seg(sent_list)
# 词性标注
pos = model.pos(hidden)
# 命名实体识别
ner = model.ner(hidden)
# 语义角色标注
srl = model.srl(hidden)
# 依存句法分析
dep = model.dep(hidden)
# 语义依存分析
sdp = model.sdp(hidden)
部分分析结果:
seg:
[['俄罗斯', '总统', '普京', '决定', '在', '顿巴斯', '地区', '开展', '特别', '军事', '行动', '。']]
pos:
[['ns', 'n', 'nh', 'v', 'p', 'ns', 'n', 'v', 'a', 'n', 'v', 'wp']]
ner:
[[('Ns', 0, 0), ('Nh', 2, 2), ('Ns', 5, 6)]]
词性标注结果中的每个元素表示分词结果中相应的单词词性,命名实体识别结果中的每个元素为一个三元组,分别表示实体类型、单词开始编号和单词结束编号。
2.3 词典分词
LTP 允许用户使用 init_dict 函数和 add_words 函数添加自定义词典:
# model.init_dict(user_dict_path)
model.add_words(['俄罗斯总统', '顿巴斯地区'])
seg, _ = model.seg(sent_list)
seg:
[['俄罗斯总统', '普京', '决定', '在', '顿巴斯地区', '开展', '特别', '军事', '行动', '。']]
2.4 词性标注集
LTP 使用的是 863 词性标注集,其各个词性含义如下表。
| Tag | Description | Example | Tag | Description | Example |
|---|---|---|---|---|---|
| a | adjective | 美丽 | ni | organization name | 保险公司 |
| b | other noun-modifier | 大型, 西式 | nl | location noun | 城郊 |
| c | conjunction | 和, 虽然 | ns | geographical name | 北京 |
| d | adverb | 很 | nt | temporal noun | 近日, 明代 |
| e | exclamation | 哎 | nz | other proper noun | 诺贝尔奖 |
| g | morpheme | 茨, 甥 | o | onomatopoeia | 哗啦 |
| h | prefix | 阿, 伪 | p | preposition | 在, 把 |
| i | idiom | 百花齐放 | q | quantity | 个 |
| j | abbreviation | 公检法 | r | pronoun | 我们 |
| k | suffix | 界, 率 | u | auxiliary | 的, 地 |
| m | number | 一, 第一 | v | verb | 跑, 学习 |
| n | general noun | 苹果 | wp | punctuation | ,。! |
| nd | direction noun | 右侧 | ws | foreign words | CPU |
| nh | person name | 杜甫, 汤姆 | x | non-lexeme | 萄, 翱 |
| z | descriptive words | 瑟瑟,匆匆 |
LTP 中的 NER 模块识别三种命名实体,分别如下:
| 标记 | 含义 |
|---|---|
| Nh | 人名 |
| Ni | 机构名 |
| Ns | 地名 |
2.5 模型算法
默认加载的 small 模型各个模块使用的算法如下,详细介绍可参考原论文。
分词:Electra Small + Linear
词性:Electra Small + Linear
命名实体:Electra Small + Adapted Transformer + Linear
依存句法:Electra Small + BiAffine + Eisner
语义依存:Electra Small + BiAffine
语义角色:Electra Small + BiAffine + CRF
3. fastHan
3.1 模型结构

如上展示了 fastHan 的基本模型结构,其采用基于 BERT 的联合模型在 13 个语料库上进行多任务学习,可以处理中文分词、词性标注、命名实体识别和依存句法分析四项基本任务。
fastHan 有 base 和 large 两个版本,large 模型使用 BERT 的前 8 层,base 模型使用 Theseus 策略将 large 模型的 8 层压缩至 4 层。base 版本在总参数量 150MB 的情况下在各项任务上均有不错表现,large 版本则接近甚至超越 SOTA 模型。
3.2 demo
使用 pip 安装 fastHan:
pip install fastHan
快速使用:
from fastHan import FastHan
model = FastHan()
# 默认加载base模型
# 使用large模型如下
# model = FastHan(model_type="large")
model.set_device(0)
sent_list = ['俄罗斯总统普京决定在顿巴斯地区开展特别军事行动。']
# 中文分词
seg = model(sent_list)
# 词性标注
pos = model(sent_list, target="POS")
# 命名实体识别
ner = model(sent_list, target="NER", return_loc=True)
# 依存句法分析
dep = model(sent_list, target="Parsing")
分析结果:
seg:
[['俄罗斯', '总统', '普京', '决定', '在', '顿巴斯', '地区', '开展', '特别', '军事', '行动', '。']]
pos:
[[['俄罗斯', 'NR'], ['总统', 'NN'], ['普京', 'NR'], ['决定', 'VV'], ['在', 'P'], ['顿巴斯', 'NR'], ['地区', 'NN'], ['开展', 'VV'], ['特别', 'JJ'], ['军事', 'NN'], ['行动', 'NN'], ['。', 'PU']]]
ner:
[[['俄罗斯', 'NS', 0], ['普京', 'NR', 5], ['顿巴斯', 'NS', 10]]]
dep:
[[['俄罗斯', 2, 'nn', 'NR'], ['总统', 3, 'nn', 'NN'], ['普京', 8, 'xsubj', 'NR'], ['决定', 0, 'root', 'VV'], ['在', 8, 'prep', 'P'], ['顿巴斯', 7, 'nn', 'NR'], ['地区', 5, 'pobj', 'NN'], ['开展', 4, 'ccomp', 'VV'], ['特别', 11, 'amod', 'JJ'], ['军事', 11, 'nn', 'NN'], ['行动', 8, 'dobj', 'NN'], ['。', 4, 'punct', 'PU']]]
当设置 return_loc=True 时,结果会返回单词的第一个字符在原始输入句子中的位置。
3.3 词典分词
fastHan 允许用户使用 add_user_dict 函数添加自定义词典,该词典会影响模型在分词任务中的权重分配。进行分词任务时,首先利用词典和正向、反向最大匹配法进行分词,并将词典方法的分词结果乘上权重系数融入到深度学习模型的结果中。add_user_dict 函数的参数可以是由单词组成的列表,也可以是文件路径(文件中的内容是由 '\n' 分隔开的词)。
用户可使用 set_user_dict_weight 函数设置自定义词典中的单词权重系数(若不设置,默认为 0.05)。
model.add_user_dict(["俄罗斯总统", "顿巴斯地区"])
# 自定义词典中的单词权重系数默认为0.05
model.set_user_dict_weight()
seg1 = model(sent_list, use_dict=True)
# 自定义词典中的单词权重系数设置为1.0
model.set_user_dict_weight(1.0)
seg2 = model(sent_list, use_dict=True)
seg1:
[['俄罗斯', '总统', '普京', '决定', '在', '顿巴斯', '地区', '开展', '特别', '军事', '行动', '。']]
seg2:
[['俄罗斯总统', '普京', '决定', '在', '顿巴斯地区', '开展', '特别', '军事', '行动', '。']]
3.4 微调模型
用户可以使用 finetune 函数在新的数据集上进行微调:
from fastHan import FastHan
model = FastHan(model_type='base')
model.set_device(0)
# traindata file path
cws_data = 'train.dat'
model.finetune(data_path=cws_data, task='CWS', save=True, save_url='finetuned_model')
微调时需要将用于训练的数据按格式放到一个文件里。对于中文分词任务,要求每行一条句子,每个词用空格分隔开:
上海 浦东 开发 与 法制 建设 同步
俄罗斯总统 普京 决定 在 顿巴斯地区 开展 特别 军事 行动 。
对于命名实体识别任务,要求使用 B-M-E-S-O 标注的 NT/NS/NR 输入格式:
札 B-NS
幌 E-NS
雪 O
国 O
庙 O
会 O
。O
主 O
道 O
上 O
的 O
雪 O
...
对于词性标注和依存句法解析任务,要求按照 CTB9 的格式与标签集。
3.5 词性标注集
fastHan 使用 CTB 词性标注集,其各个词性含义如下表。
| 标签 | 描述 | 含义 | 标签 | 描述 | 含义 |
|---|---|---|---|---|---|
| AD | adverbs | 副词 | M | Measure word(including classifiers) | 量词,例子:“个” |
| AS | Aspect marker | 体态词,体标记(例如:了,在,着,过) | MSP | Some particles | 例子:“所” |
| BA | 把 in ba-const | “把”、“将”的词性标记 | NN | Common nouns | 普通名词 |
| CC | Coordinating conjunction | 并列连词,“和” | NR | Proper nouns | 专有名词 |
| CD | Cardinal numbers | 数字,“一百” | NT | Temporal nouns | 时序词,表示时间的名词 |
| CS | Subordinating conj | 从属连词(例子:若,如果,如…) | OD | Ordinal numbers | 序数词,“第一” |
| DEC | 的 for relative-clause etc | “的”词性标记 | ON | Onomatopoeia | 拟声词,“哈哈” |
| DEG | Associative | 联结词“的” | P | Preposition (excluding 把 and 被) | 介词 |
| DER | in V-de construction, and V-de-R | “得” | PN | pronouns | 代词 |
| DEV | before VP | 地 | PU | Punctuations | 标点 |
| DT | Determiner | 限定词,“这” | SB | in long bei-construction | 例子:“被,给” |
| ETC | Tag for words, in coordination phrase | 等,等等 | SP | Sentence-final particle | 句尾小品词,“吗” |
| FW | Foreign words | 例子:ISO | VA | Predicative adjective | 表语形容词,“红” |
| IJ | interjetion | 感叹词 | VC | Copula | 系动词,“是” |
| JJ | Noun-modifier other than nouns | VE | 有 as the main verb | “有” | |
| LB | in long bei-construction | 例子:被,给 | VV | Other verbs | 其他动词 |
| LC | Localizer | 定位词,例子:“里” |
fastHan 中的 NER 模块识别三种命名实体,分别如下:
| 标记 | 含义 |
|---|---|
| NR | 人名 |
| NT | 机构名 |
| NS | 地名 |
4. 速度对比实验
笔者在 GPU 上(torch1.7 + cuda10.2 + cudnn7.6.5)对比了 ltp 和 fastHan 的处理速度。从中文维基百科中抽取了 10098 条长度为 128 左右的句子,分别使用 ltp-tiny、ltp-small、ltp-base 和 fastHan-base、fastHan-large 模型进行处理,batch size 设置为 64,统计不同任务的处理速度如下表所示:
| model | cws_speed (句/s) | pos_speed (句/s) | ner_speed (句/s) |
|---|---|---|---|
| ltp-tiny | 613 | 614 | 596 |
| ltp-small | 451 | 450 | 413 |
| ltp-base | 189 | 186 | 178 |
| fastHan-base | 199 | 194 | 194 |
| fastHan-large | 144 | 143 | 145 |
可以看出,ltp-tiny 和 ltp-small 模型的处理速度显著快于 fastHan,fashHan-base 的处理速度略快于 ltp-base,fastHan-large 的处理速度最慢。通常情况下,ltp-small 的性能已经非常不错,对处理速度要求高的场景建议使用 ltp 默认的 small 模型。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: