
2021 年最酷的 10 个大数据工具(建议收藏)
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群

管理不断增长的数据量仍然是企业和组织面临的挑战。这里有 10 个很酷的大数据管理工具和平台,引起了我们的注意。
大数据管理的大挑战
全球 COVID-19 大流行并没有减缓数据的指数增长:IDC 最近计算出,2020 年全球创建、消费和存储了 64.2 泽字节的数据。市场研究人员预测,全球数据创建和复制将经历 23% 2020 年至 2025 年的复合年增长率。
好消息是创新的 IT 供应商,无论是老牌公司还是初创公司,都在继续为一系列数据管理任务开发下一代平台和工具,包括数据操作、数据集成、数据准备、数据科学、数据治理、数据发现和数据沿袭跟踪。
以下是一些很酷的大数据管理工具,它们在 2021 年年中引起了我们的注意。
Airbyte
早期创业公司 Airbyte(成立于 2020 年 1 月)开发了一个开源数据集成平台,用于将来自不同来源的数据复制和整合到数据库、数据仓库和数据湖中。组织可以使用该平台在数据源之间构建管道,包括 Salesforce 和 Facebook Ads 等运营应用程序,以及 Snowflake 和 AWS Redshift 等云数据仓库。
虽然 Airbyte 正在与众多成熟的 ETL(提取、转换和加载)工具供应商竞争,但该公司鼓吹其软件的简单性,并坚持认为即使是非技术业务分析师也可以使用它来复制数据。这家初创公司的开源方法创造了一个活跃的用户社区,该社区正在为该平台快速开发其他连接器。
今年 1 月至 5 月期间,Airbyte 的客户群增长了八倍,达到 2,000 多个。这家总部位于旧金山的公司于 5 月在 A 轮融资中筹集了 2600 万美元。
Alation Cloud Service
Alation 已将其原始数据目录软件扩展为用于一系列企业数据智能任务的平台,包括数据搜索和发现、数据治理、数据管理、分析和数字转换。
4 月,该公司通过其新的 Alation 云服务将这些功能扩展到云,这是一个基于云的综合数据智能平台,可以通过云原生连接器连接到云中或本地的任何数据源。
该公司总部位于加利福尼亚州雷德伍德城,该公司表示,新的云产品及其持续集成和部署选项提供了一种简单的方法,可以在组织的混合架构中推动数据智能,同时降低维护和管理开销并缩短交付时间。价值。

AtScale CloudStart
AtScale 的旗舰产品智能数据虚拟化平台使用语义层技术为分布式数据提供基于云的 OLAP(在线分析处理)分析——无论它位于何处。
这家总部位于波士顿的公司于 5 月推出的全新 AtScale CloudStart 通过将 AtScale 的语义层与云数据管理系统(包括 Snowflake、Microsoft Azure Synapse SQL、Google BigQuery、Amazon Redshift 和 DataBricks)集成,提供了一种在云数据平台上构建分析基础设施的方法。
CloudStart 可以更轻松地将 Tableau、Power BI 和 Looker 等业务分析工具连接到多个云数据源。

CockroachDB 21.1
位于纽约的 Cockroach Labs 开发了 CockroachDB,这是一种云原生分布式 SQL 数据库,旨在处理具有大量事务数据的工作负载。
Cockroach 在 5 月推出了 CockroachDB 21.1,使用单一数据库将数据关联到世界任何地方的特定位置变得更加简单——这是一项重大挑战,因为越来越多的国家和地区要求将数据保留在其境内。
新的数据库版本提供了独特的架构和内置功能,可使用少量 SQL 语句管理世界任何地方数据的地理位置——无需架构更改或手动分片——为用户提供近乎即时的数据访问,同时确保本地合规性。
该版本通过将数据放置在靠近最终用户的物理位置来最大限度地减少事务延迟,通过使用在区域或云故障中幸存下来的冗余来消除中断,并支持本地数据隐私要求。

Databricks Delta Sharing
Databricks 在 5 月份启动了 Delta Sharing 计划,旨在创建一个开源数据共享协议,用于跨组织实时安全地共享数据,独立于数据所在的平台。
Delta 共享包含在开源 Delta Lake 1.0 项目中,它建立了一个通用标准,用于共享所有数据类型(结构化和非结构化),其开放协议可用于 SQL、可视化分析工具和编程语言(如 Python 和R. 大规模数据集也可以实时共享 Apache Parquet 和 Delta Lake 格式,无需复制。
据 Databricks 称,Delta Sharing 计划已经吸引了包括纳斯达克、标准普尔和 Factset 在内的许多数据提供商以及包括亚马逊网络服务、微软和谷歌云在内的领先 IT 供应商的支持。
Delta Sharing 是 Databricks 的最新开源计划,Databricks 是最受关注的大数据初创公司之一。由 Apache Spark 分析引擎的开发人员创立,总部位于旧金山的 Databricks 销售其旗舰统一数据分析平台 Databricks Lakehouse 平台。

Dremio Dart Initiative
6 月,数据湖引擎开发商 Dremio 推出了 Dremio Dart 计划,这家总部位于加利福尼亚州圣克拉拉的公司大胆宣称这是“在淘汰云数据仓库方面向前迈出的重要一步”。
Dremio 的软件提供了一种直接分析数据湖(大量无组织数据存储)中的数据的方法,而无需将数据复制并移动到数据仓库系统中。Dart Initiative 通过使直接在数据湖上运行所有关键任务 SQL 工作负载成为可能,将其提升到一个新的水平。
最初的 Dart Initiative 功能内置于最新的 Dremio 版本中,包括更快的查询执行和优化查询计划、增强的查询加速自动化管理、对更广泛的 SQL 工作负载的支持以及改进的分布式和实时元数据管理以支持更大的数据集。

Nexla Nexsets
Nexla 开发了一个统一的数据操作平台——公司称之为“融合数据结构”——用于在整个组织中创建可扩展、可重复和可预测的数据流。该软件用于集成、自动化和监控数据用例的传入和传出数据,包括数据科学和业务分析。
Nexsets 是 Nexla 最新加入其技术组合的产品,可自动执行耗时的手动数据工程任务,从而更轻松地访问、集成和转换可能分散在不同系统中的数据。Nexsets 无需复制或复制数据即可创建数据的逻辑视图,为业务用户提供对精选数据视图的访问权限,他们可用于创建报告和仪表板、将数据移动到应用程序或将数据存储在云中。
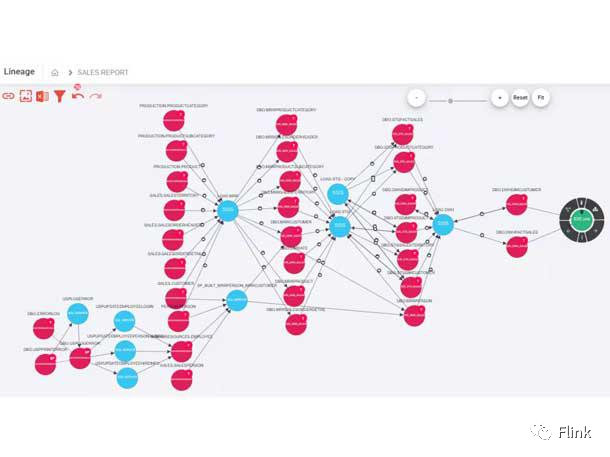
Octopai Data Lineage XD
Octopai 总部位于以色列特拉维夫,开发自动化元数据管理和分析的软件工具,帮助组织定位和理解他们的数据,以改进运营、数据质量和数据治理。
Octopai 于 5 月 10 日推出了 Data Lineage XD,这是一个先进的多维数据血缘平台,该公司表示将数据血缘提升到一个新的水平。Data Lineage XD 使用可视化表示来显示从源到目的地的数据流,让用户更全面地了解数据来源、发生的事情以及数据在数据环境中的分布位置。
此类功能用于跟踪数据错误、实施流程变更、管理系统迁移和提高业务分析效率。
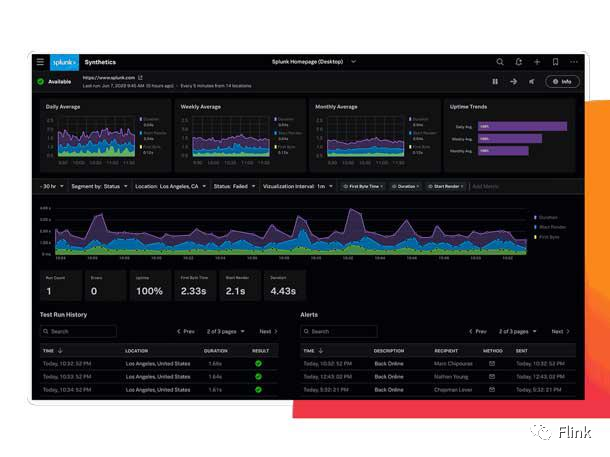
Splunk Observability Cloud and Splunk Security Cloud
Splunk 一直在扩展其产品组合,以利用其“数据到一切”Splunk Enterprise 和 Splunk Cloud 平台的功能在可搜索存储库中捕获、索引和关联机器数据。
IT 系统和应用程序监控是 Splunk 平台最常见的用途之一。Splunk 总部位于旧金山,通过为 IT 和 DevOps 团队开发 Splunk Observability Cloud,这是一个 Splunk 软件包,包括 Splunk Log Observer、Splunk Real User Monitoring、Splunk Infrastructure Monitoring、Splunk APM 和 Splunk On-Call .
面向 IT 和 DevOps 团队的 Observability Cloud 于 2020 年 10 月首次推出测试版,并于 5 月全面上市。
用于网络安全任务的系统监控和数据收集是 Splunk 平台的另一个主要应用。6 月,Splunk 推出了 Splunk Security Cloud,这是一个以数据为中心的安全运营平台,利用其“数据到一切”技术提供高级安全分析、自动化安全运营和集成威胁情报功能。

YugabyteDB
Yugabyte 位于加利福尼亚州桑尼维尔,是新一代数据库开发商之一,提供旨在超越和超越传统数据库系统的技术。YugabyteDB 是一个高性能的分布式 SQL 数据库,用于构建全球互联网规模的应用程序。
5 月,Yugabyte 发布了 YugabyteDB 2.7,其中包含一套全面的部署选项,适用于希望使用 Red Hat OpenShift 和 VMware Tanzu 等 Kubernetes 平台跨混合云环境扩展分布式 SQL 的组织。
该公司表示,YugabyteDB 对公共和云原生环境的支持使企业和组织能够贯彻其战略 Kubernetes、分布式 SQL 和微服务计划,同时避免云锁定。
YugabyteDB 2.7 版本可以回滚意外更改并将数据库恢复到更早的时间点。它还支持表空间,以细粒度控制跨区域和可用区的数据分布。
--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇