
Bert4torch 快速入门实战
作者简介
作者:Bo仔很忙
原文:https://zhuanlan.zhihu.com/p/486329434
转载者:杨夕
推荐系统 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
个人笔记:
https://github.com/km1994/nlp_paper_study

背景
本人经常会阅读苏神的科学空间网站,里面有很多对前言paper浅显易懂的解释,以及很多苏神自己的创新实践;并且基于bert4keras框架都有了相应的代码实现。但是由于本人主要用pytorch开发,因此参考bert4keras开发了bert4torch项目,实现了bert4keras的主要功能。
简介
bert4torch是一个基于pytorch的训练框架,前期以效仿和实现bert4keras的主要功能为主,方便加载多类预训练模型进行finetune,提供了中文注释方便用户理解模型结构。主要是期望应对新项目时,可以直接调用不同的预训练模型直接finetune,或方便用户基于bert进行魔改,快速验证自己的idea;节省在github上clone各种项目耗时耗力,且本地文件各种copy的问题。
pip安装
pip install bert4torchgithub链接https://github.com/Tongjilibo/bert4torch
主要功能
1、加载预训练权重(bert、roberta、albert、nezha、bart、RoFormer、ELECTRA、GPT、GPT2、T5)继续进行finetune
2、在bert基础上灵活定义自己模型:主要是可以接在bert的[btz, seq_len, hdsz]的隐含层向量后做各种魔改
3、调用方式和bert4keras基本一致,简洁高效
model.fit(train_dataloader,steps_per_epoch=1000,epochs=epochs,callbacks=[evaluator])
4、实现基于keras的训练进度条动态展示
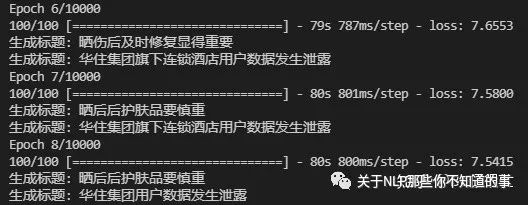 仿照keras的模型训练进度条
仿照keras的模型训练进度条5、配合torchinfo,实现打印各层参数量功能
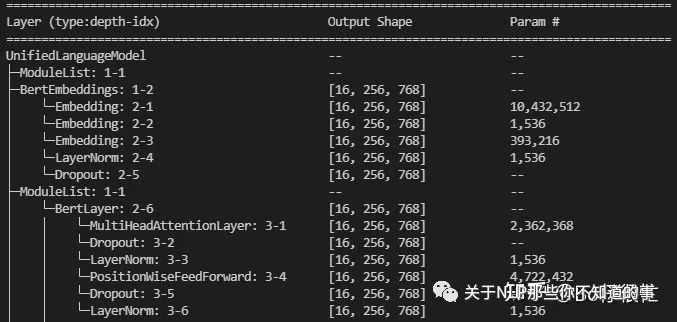 打印参数
打印参数6、结合logger,或者tensorboard可以在后台打印日志
支持在训练开始/结束,batch开始/结束,epoch的开始/结束,记录日志,写tensorboard等
class Callback(object):'''Callback基类 '''def __init__(self):passdef on_train_begin(self, logs=None):passdef on_train_end(self, logs=None):passdef on_epoch_begin(self, global_step, epoch, logs=None):passdef on_epoch_end(self, global_step, epoch, logs=None):passdef on_batch_begin(self, global_step, batch, logs=None):passdef on_batch_end(self, global_step, batch, logs=None):pass
7、集成多个example,可以作为自己的训练框架,方便在同一个数据集上尝试多种解决方案
 实现多个example可供参考
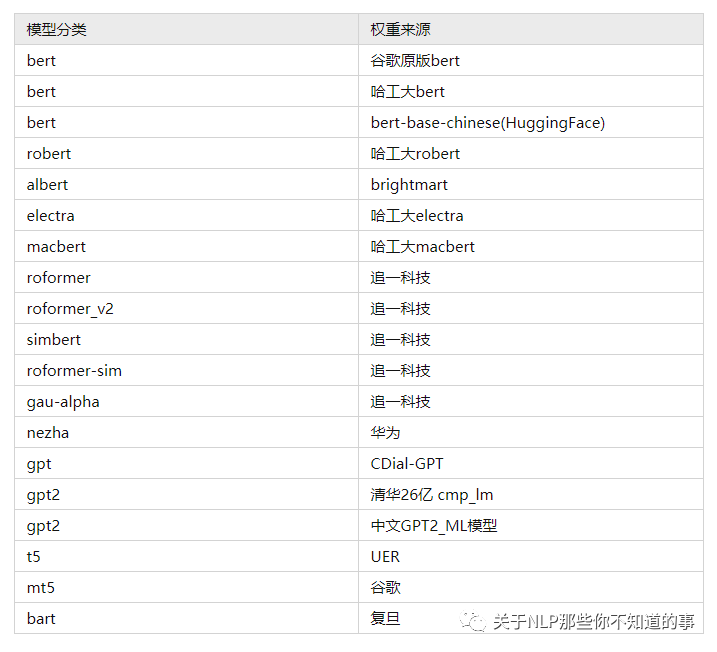
实现多个example可供参考支持的预训练权重(bert4torch)
实战
1. 建模流程示例
# 建立分词器tokenizer = Tokenizer(dict_path, do_lower_case=True)# 加载数据集,可以自己继承Dataset来定义class MyDataset(ListDataset):def load_data(filenames):"""读取文本文件,整理成需要的格式 """D = []return Ddef collate_fn(batch):'''处理上述load_data得到的batch数据,整理成对应device上的Tensor 注意:返回值分为feature和label, feature可整理成list或tuple '''batch_token_ids, batch_segment_ids, batch_labels = [], [], []return [batch_token_ids, batch_segment_ids], batch_labels.flatten()# 加载数据集train_dataloader = DataLoader(MyDataset('file_path'), batch_size=batch_size, shuffle=True, collate_fn=collate_fn) # 定义bert上的模型结构,以文本二分类为例class Model(BaseModel):def __init__(self) -> None:super().__init__()self.bert = build_transformer_model(config_path, checkpoint_path, with_pool=True)self.dropout = nn.Dropout(0.1)self.dense = nn.Linear(768, 2)def forward(self, token_ids, segment_ids):# build_transformer_model得到的模型仅接受list/tuple传参,因此入参只有一个时候包装成[token_ids]hidden_states, pooled_output = self.bert([token_ids, segment_ids])output = self.dropout(pooled_output)output = self.dense(output)return outputmodel = Model().to(device)# 定义使用的loss和optimizer,这里支持自定义model.compile(loss=nn.CrossEntropyLoss(), # 可以自定义Lossoptimizer=optim.Adam(model.parameters(), lr=2e-5), # 可以自定义优化器scheduler=None, # 可以自定义schedulermetrics=['accuracy'])# 定义评价函数def evaluate(data):total, right = 0., 0.for x_true, y_true in data:y_pred = model.predict(x_true).argmax(axis=1)total += len(y_true)right += (y_true == y_pred).sum().item()return right / totalclass Evaluator(Callback):"""评估与保存,这里定义仅在epoch结束后调用 """def __init__(self):self.best_val_acc = 0.def on_epoch_end(self, global_step, epoch, logs=None):val_acc = evaluate(valid_dataloader)if val_acc > self.best_val_acc:self.best_val_acc = val_accmodel.save_weights('best_model.pt')print(f'val_acc: {val_acc:.5f}, best_val_acc: {self.best_val_acc:.5f}\n')if __name__ == '__main__':evaluator = Evaluator()model.fit(train_dataloader, epochs=20, steps_per_epoch=100, grad_accumulation_steps=2, callbacks=[evaluator])
2. 主要模块讲解
1) 数据处理部分
a. 精简词表,并建立分词器
token_dict, keep_tokens = load_vocab(dict_path=dict_path, # 词典文件路径simplified=True, # 过滤冗余部分token,如[unused1]startswith=['[PAD]', '[UNK]', '[CLS]', '[SEP]'], # 指定起始的token,如[UNK]从bert默认的103位置调整到1)tokenizer = Tokenizer(token_dict, do_lower_case=True) # 若无需精简,仅使用当前行定义tokenizer即可
b. 好用的小函数
text_segmentate(): 截断总长度至不超过maxlen, 接受多个sequence输入,每次截断最长的句子,indices表示删除的token位置tokenizer.encode(): 把text转成token_ids,默认句首添加[CLS],句尾添加[SEP],返回token_ids和segment_ids,相当于同时调用tokenizer.tokenize()和tokenizer.tokens_to_ids()tokenizer.decode(): 把token_ids转成text,默认会删除[CLS], [SEP], [UNK]等特殊字符,相当于调用tokenizer.ids_to_tokens()并做了一些后处理sequence_padding: 将序列padding到同一长度, 传入一个元素为list, ndarray, tensor的list,返回ndarry或tensor
2) 模型定义部分
模型创建
'''调用模型后,若设置with_pool, with_nsp, with_mlm,则返回值依次为[hidden_states, pool_emb/nsp_emb, mlm_scores],否则只返回hidden_states'''build_transformer_model(config_path=config_path, # 模型的config文件地址checkpoint_path=checkpoint_path, # 模型文件地址,默认值None表示不加载预训练模型model='bert', # 加载的模型结构,这里Model也可以基于nn.Module自定义后传入application='encoder', # 模型应用,支持encoder,lm和unilm格式segment_vocab_size=2, # type_token_ids数量,默认为2,如不传入segment_ids则需设置为0with_pool=False, # 是否包含Pool部分with_nsp=False, # 是否包含NSP部分with_mlm=False, # 是否包含MLM部分return_model_config=False, # 是否返回模型配置参数output_all_encoded_layers=False, # 是否返回所有hidden_state层)
定义loss,optimizer,scheduler等
'''定义使用的loss和optimizer,这里支持自定义'''model.compile(loss=nn.CrossEntropyLoss(), # 可以自定义Lossoptimizer=optim.Adam(model.parameters(), lr=2e-5), # 可以自定义优化器scheduler=None, # 可以自定义scheduleradversarial_train={'name': 'fgm'}, # 训练trick方案设置,支持fgm, pgd, gradient_penalty, vatmetrics=['accuracy'] # loss等默认打印的字段无需设置)
自定义模型
'''基于bert上层的各类魔改,如last2layer_average, token_first_last_average'''class Model(BaseModel):# 需要继承BaseModeldef __init__(self):super().__init__()self.bert = build_transformer_model(config_path, checkpoint_path)def forward(self):pass
自定义训练过程
'''自定义fit过程,适用于自带fit()不满足需求时'''class Model(BaseModel):def fit(self, train_dataloader, steps_per_epoch, epochs):train_dataloader = cycle(train_dataloader)self.train()for epoch in range(epochs):for bti in range(steps_per_epoch):train_X, train_y = next(train_dataloader)output = self.forward(*train_X)loss = self.criterion(output, train_y)loss.backward()self.optimizer.step()self.optimizer.zero_grad()
模型保存和加载
'''prefix: 是否以原始的key来保存,如word_embedding原始key为bert.embeddings.word_embeddings.weight默认为None表示不启用, 若基于BaseModel自定义模型,需指定为bert模型对应的成员变量名,直接使用设置为''主要是为了别的训练框架容易加载'''model.save_weights(save_path, prefix=None)model.load_weights(load_path, strict=True, prefix=None)
加载transformers模型进行训练
from transformers import AutoModelForSequenceClassificationclass Model(BaseModel):def __init__(self):super().__init__()self.bert = AutoModelForSequenceClassification.from_pretrained("file_path", num_labels=2)def forward(self, token_ids, attention_mask, segment_ids):output = self.bert(input_ids=token_ids, attention_mask=attention_mask, token_type_ids=segment_ids)return output.logits
3) 模型评估部分
'''支持在多个位置执行'''class Evaluator(Callback):"""评估与保存 """def __init__(self):self.best_val_acc = 0.def on_train_begin(self, logs=None): # 训练开始时候passdef on_train_end(self, logs=None): # 训练结束时候passdef on_batch_begin(self, global_step, batch, logs=None): # batch开始时候passdef on_batch_end(self, global_step, batch, logs=None): # batch结束时候# 可以设置每隔多少个step,后台记录log,写tensorboard等# 尽量不要在batch_begin和batch_end中print,防止打断进度条功能passdef on_epoch_begin(self, global_step, epoch, logs=None): # epoch开始时候passdef on_epoch_end(self, global_step, epoch, logs=None): # epoch结束时候val_acc = evaluate(valid_dataloader)if val_acc > self.best_val_acc:self.best_val_acc = val_accmodel.save_weights('best_model.pt')print(f'val_acc: {val_acc:.5f}, best_val_acc: {self.best_val_acc:.5f}\n')
3. 其他特性讲解
1) 单机多卡训练
a. 使用DataParallel
'''DP有两种方式,第一种是forward只计算logit,第二种是forward直接计算loss建议使用第二种,可以部分缓解负载不均衡的问题'''from bert4torch.models import BaseModelDP# ===========处理数据和定义model===========model = BaseModelDP(model) # 指定DP模式使用多gpumodel.compile(loss=lambda x, _: x.mean(), # 多个gpu计算的loss的均值optimizer=optim.Adam(model.parameters(), lr=2e-5), # 用足够小的学习率)
b. 使用DistributedDataParallel
'''DDP使用torch.distributed.launch,从命令行启动'''# 需要定义命令行参数parser = argparse.ArgumentParser()parser.add_argument("--local_rank", type=int, default=-1)args = parser.parse_args()torch.cuda.set_device(args.local_rank)device = torch.device('cuda', args.local_rank)torch.distributed.init_process_group(backend='nccl')# ===========处理数据和定义model===========# 指定DDP模型使用多gpu, master_rank为指定用于打印训练过程的local_rankmodel = BaseModelDDP(model, master_rank=0,device_ids=[args.local_rank],output_device=args.local_rank,find_unused_parameters=False)# 定义使用的loss和optimizer,这里支持自定义model.compile(loss=lambda x, _: x, # 直接把forward计算的loss传出来optimizer=optim.Adam(model.parameters(), lr=2e-5), # 用足够小的学习率)
2) tensorboard保存训练过程
from tensorboardX import SummaryWriterclass Evaluator(Callback):"""每隔多少个step评估并记录tensorboard """def on_batch_end(self, global_step, batch, logs=None):if global_step % 100 == 0:writer.add_scalar(f"train/loss", logs['loss'], global_step)val_acc = evaluate(valid_dataloader)writer.add_scalar(f"valid/acc", val_acc, global_step)
3) 打印训练参数
from torchinfo import summarysummary(model, input_data=next(iter(train_dataloader))[0])