
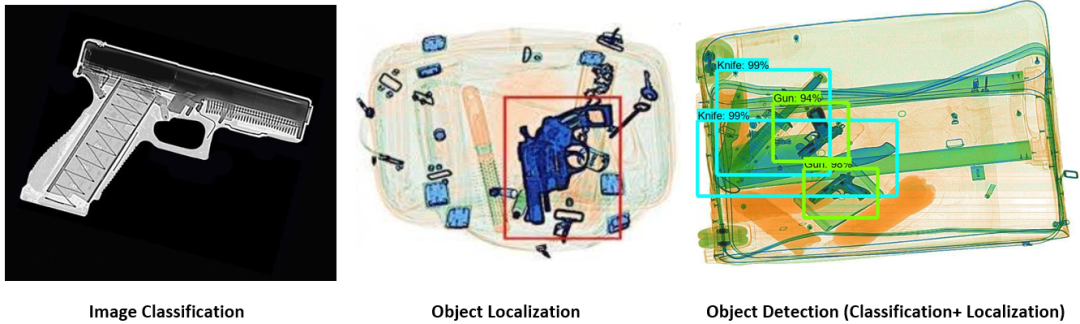
X射线图像中的目标检测
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:小白学视觉

1 动机和背景
每天有数百万人乘坐地铁、民航飞机等公共交通工具,因此行李的安全检测将保护公共场所免受恐怖主义等影响,在安全防范中扮演着重要角色。但随着城市人口的增长,使用公共交通工具的人数逐渐增多,在获得便利的同时带来很大的不安全性,因此设计一种可以帮助加快安全检查过程并提高其效率的系统非常重要。卷积神经网络等深度学习算法不断发展,也在各种不同领域(例如机器翻译和图像处理)发挥了很大作用,而目标检测作为一项基本的计算机视觉问题,能为图像和视频理解提供有价值的信息,并与图像分类、机器人技术、人脸识别和自动驾驶等相关。在本项目中,我们将一起探索几个基于深度学习的目标检测模型,以对X射线图像中的违禁物体进行定位和分类为基础,并比较这几个模型在不同指标上的表现。
针对该(目标检测)领域已有的研究,R. Girshick等[29]的基于区域的目标检测网络(称为R-CNN),使用选择性搜索算法在感兴趣物体周围寻找边界框,但这种模型训练很慢;几个月后,R. Girshick等 [30]通过改进选择性搜索算法改进了R-CNN模型,减少了训练时间,该模型称为Fast R-CNN;一年后,K. He,R. Girshick等[31]删除了选择性搜索算法,引入Region Proposal net(RPN)网络,设计了Faster R-CNN新目标检测模型,大大减少了训练时间;2017年,K. He等[32]提出Mask R-CNN,该架构不仅仅使用边界框来定位物体,还可以定位每个物体的精确像素。
与上述基于区域提议的方法不同,一些研究还介绍了另一种称为基于回归/分类的目标检测方法,D. Erhan等[33]在2014年推出了MulitBox;J. Redmon等[34]在2016年发明了YOLO,达到很高的检测速度;之后,J. Redmon和A. Farhadi [35]设计了一种更快的模型,称为YOLO v2;2016年,由W. Liu等人 [36] 组成另一个研究团队介绍了一种称为SSD网络的新架构,与Faster R-CNN相比,SSD具有相近的准确性,但训练时间更短。在我们的项目中已经探索了所有这些基于区域提案的框架和基于回归/分类的框架。
数据集:SIXray数据集由来自北京地铁的X射线图像组成https://github.com/MeioJane/SIXray

2 问题陈述
本项目的目标是通过选择多种算法、训练多种模型,比较各种算法的性能,找到检测X射线图像中违禁物品的最佳算法,这些违禁物包括了枪、刀、扳手、钳子和剪刀,但是锤子不包含在此项目中,因为这一类的图像太少。模型的性能由mAP(目标检测的指标)、准确率和查全率来描述,接下来我们讨论解决这一问题具有哪些挑战。
2.1 算法(目标检测vs图像分类)
在图像分类中,CNN被用来当作特征提取器,使用图像中的所有像素直接提取特征,这些特征之后被用来分类X射线图像中违禁物品,然而这种方法计算代价昂贵,并且带来了大量的冗余信息,此外标准CNN中包含具有固定输出的全连接层(即分类网络的输出是固定的维度),但在我们的数据集中,一副图像中可能有许多相同或不相同类别的违禁物品,并且违禁物品可能有不同的空间位置和长宽比,因此使用分类方法会导致计算成本高昂,耗费大量时间。因此我们得出结论,该数据集非常适合目标检测算法,目标检测的目标不仅是分类违禁物品,还要通过创建边界框来为它们定位。
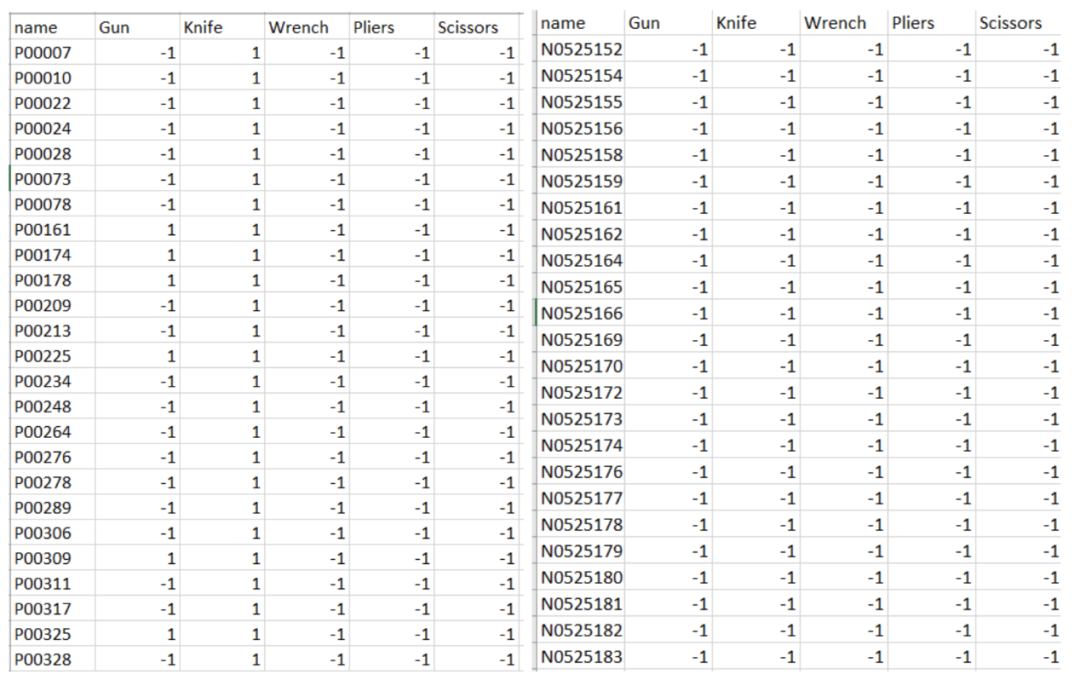
2.2 数据集不平衡
我们的数据集高度不平衡,数据集的负样本比正样本多的多,负样本意味着图片中不包含我们感兴趣的目标,换句话来说正样本意味着一张图片中包含我们感兴趣的物品。在本例中,我们尝试在X射线图像中检测的目标是违禁物品,如刀、枪、扳手、钳子和剪刀。使用目标检测模型而不是分类模型的好处是我们能够训练足够的正样本,无需将负样本(图像)合并到训练集中,这是因为负样本早就隐式的存在于图像中,图像中与边界框(目标的真实边界框)不相关的所有区域都是负样本。因此,由于不平衡的数据集,我们能够节省训练大型数据集的时间和成本而不用牺牲很多准确性。
2.3 复杂的图像
我们的X射线图像数据集,不仅是数据集,不平衡数据集中也包含了不清晰的图像。从本质上来讲,安全检查经常处理的行李图像中包含了与其他物品聚集、重叠和随机堆叠的物品,例正常物品和违禁物品通常以各种方式混合在一起,导致一些重大检测问题,例如通过简单的金属探测器甚至是人员检查等技术而产生错误检测或漏检。但通过仔细选择合适的目标检测模型,不仅可以对违禁物品正确分类,还可以确定它们在图像中位置,解决这个具有挑战性的问题。下一节中,我们将介绍项目选择的每个模型背后的目标检测架构。

3 数据处理过程
3.1 数据获取
数据集为包含正样本(包含我们感兴趣对象的图像,即我们要定位和分类的违禁物品)和负样本(包含非违禁物品的图像)的SIXray数据集,这些样本随后用于训练、评估我们的模型。此外,所有图像的标签文件位于三个单独的文件夹中。我们感兴趣对象的位置标注文件为xml格式。
3.2 预处理图像和标签文件以创建训练数据
我们使用正样本的一个子集用于训练,另一个子集与负样本结合以进行测试和评估。由于计算成本和功能的限制,在本项目中我们没有使用整个SIXray数据集。我们数据集有3个主要预处理步骤:
第一步:获取我们要使用的每个图像的正确标签。因为我们使用的是数据集的子集,因此需要从数据集中为每个图像获取新标签,之后这些标签被用来测试和评估我们训练好的模型。
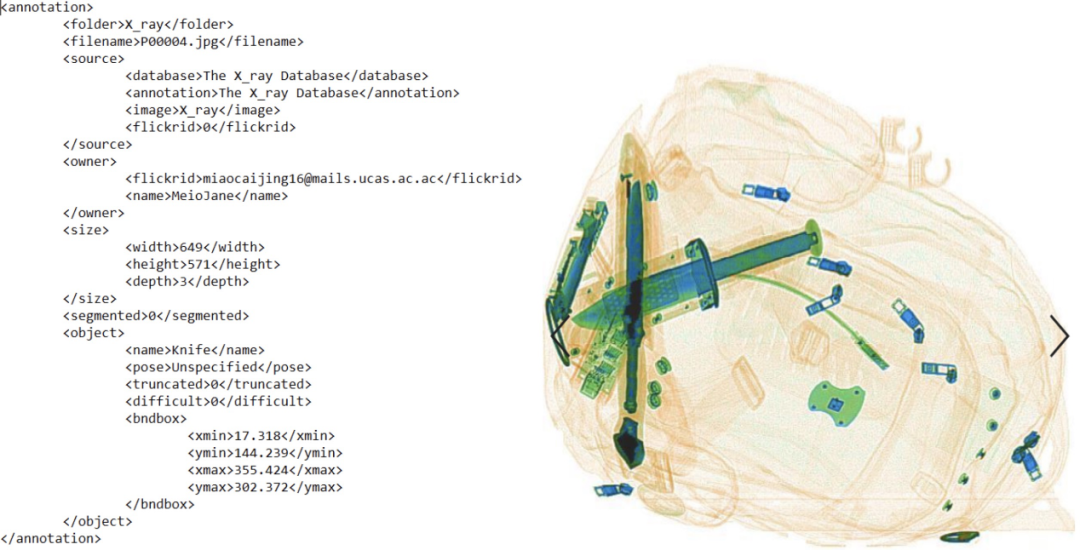
第二步:通过转换带标签的xml文件(包含每个图片元数据,例类别、对象位置)创建可读数据集。
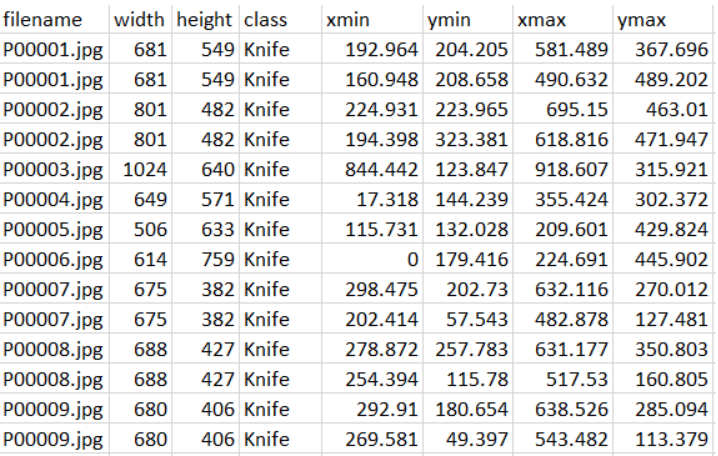
第三步:将正样本的图像和注释文件转换为Tensorflow Record,用于目标检测模型的训练。
3.3 创建训练和训练模型
我们的训练是通过TensorFlow目标检测API完成的,我们可以从下面的链接下载和安装,还可以下载来自TensorFlow模型Zoo的配置文件和目标检测预训练模型。另外我们尝试了分类模型,但是效果不好,因此我们改为使用目标检测模型。
TensorFlow目标检测API:
https://github.com/tensorflow/models/tree/master/research/object_detection
TensorFlow目标检测模型Zoo:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
每个模型的TensorFlow目标检测配置:
https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs
训练是在带有深度学习VM的Google cloud平台上完成的。我们训练了8种不同的目标检测模型。
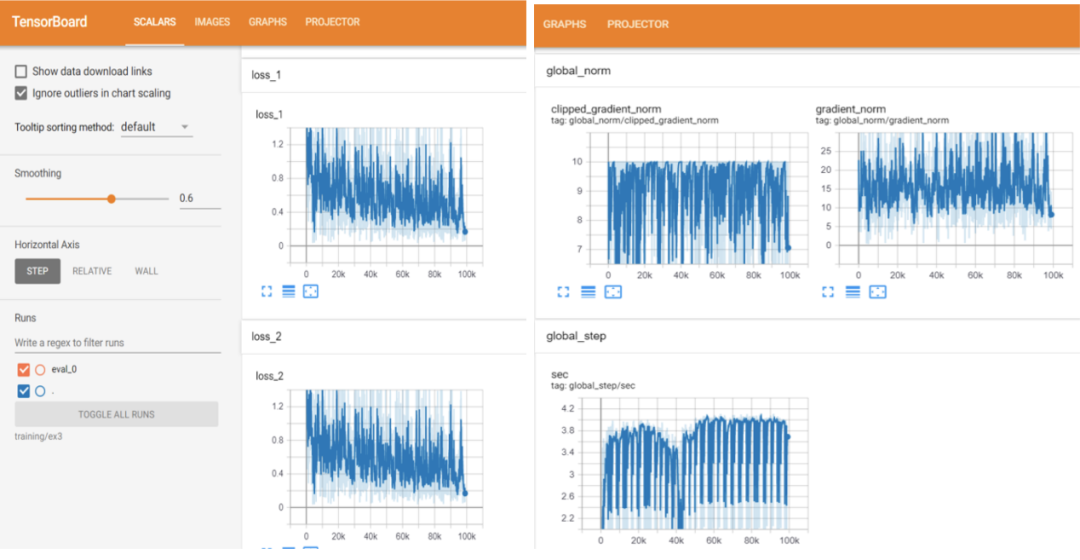
用于训练的图像为7200个正样本,在这个项目中,我们没有将负样本添加到我们的训练集中,因为检测模型会将不属于真实边界框的图像区域作为负样本。此外,训练过程由TensorBoard监控,可以在线查看训练进度,如结束训练的步数、训练损失、验证损失等等。

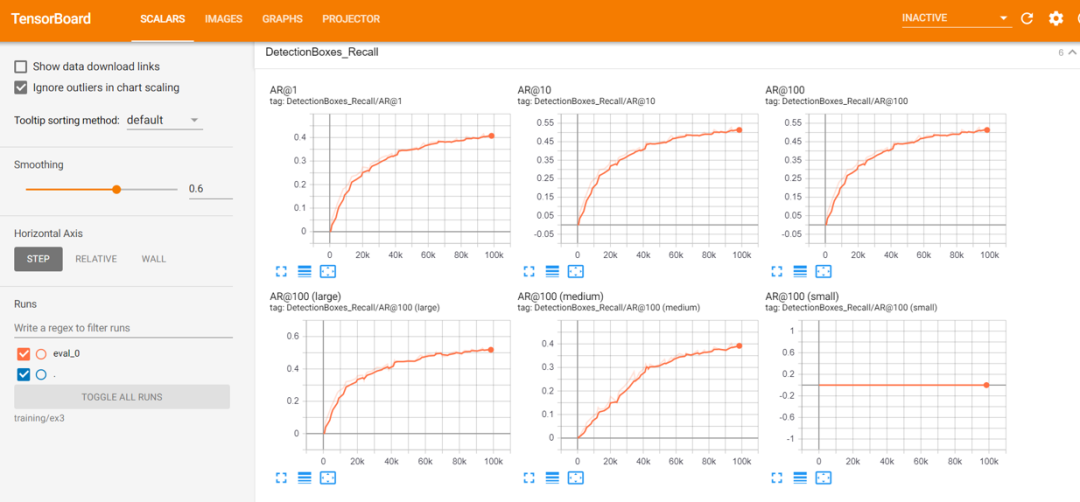
3.4 用不同比例的正-负图像集评估每个模型
我们为训练有素的模型创建一个推理图,并用它与正样本的另一个子集和全部负样本进行评估。评估的性能用Precision-Recall分数和mAP进行衡量。
用于模型评估的三种测试集比率:
1.1800个正样本+ 50,000个负样本
2.1800个正样本+ 100,000个负样本
3.1800个正样本+ 150,000个负样本
4 方法
对于图像分类问题,图像作为输入,模型会对该图像中包含的对象进行分类,而定位问题是定位图像中的对象的位置,但是仅仅定位并不能帮助我们预测图像中的对象类别。目标检测能指定对象在图片中的位置并预测该对象的类别,因此在此项目中,目标检测模型非常适合我们的X射线图像数据集。
在我们的项目中,我们实现了8个目标检测模型,他们具有不同的结构(下节讲述):
1. SSD Mobilenet_v1
2. SSD Mobilenet_v1_fpn
3. SSD Inception_v2
4. SSD Resnet50
5. R-FCN Resnet101
6. Faster R-CNN Resnet50
7. Faster R-CNN Resnet101
8. Faster R-CNN Inception_v2
4.1 目标检测架构
(1)SSD(Single Shot MultiBox Detector)
论文地址:https://arxiv.org/abs/1512.02325
SSD是一种使用单一深度神经网络检测图像中对象的方法,该方法将边界框的输出空间离散化为一组默认框,这组默认框在每个特征图位置上具有不同长宽比和尺度。在预测时,网络会为每个默认框生成所有对象类别存在的分数,并调整默认框以更好的匹配该对象的形状。
与需要区域提案的其他方法相比,SSD更加简单,因为SSD将所有的计算完全封装在一个网络中。SSD使用VGG16作为特征提取器(等效于Faster RCNN中的CNN),它使得SSD易于训练、检测迅速,并且可以直接集成到需要实时检测的系统中。SSD采用了特征金字塔层次结构,具有快速的检测速度,但是在检测小物体方面性能低下,因为它错过了使用高分辨率特征图的机会(例SSD仅仅使用上层特征图进行检测),如下图:
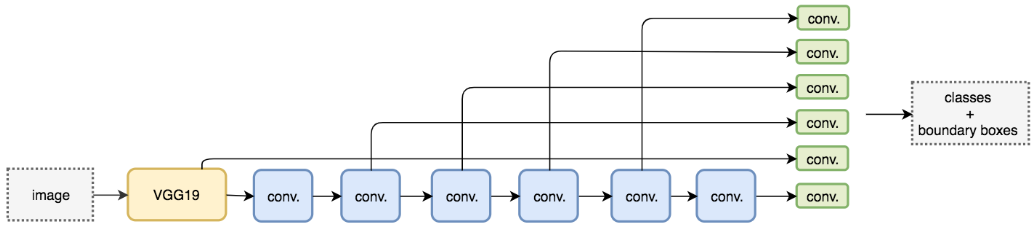
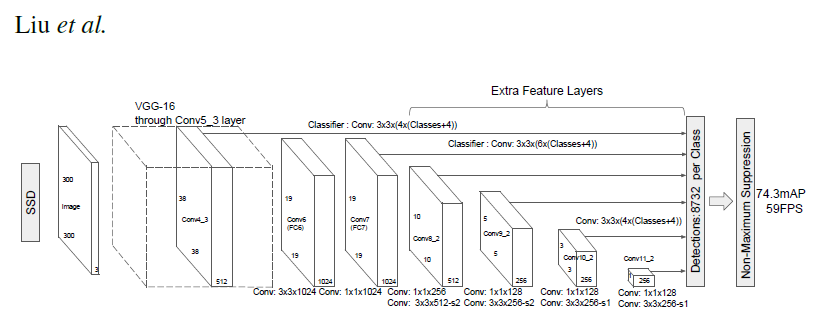
(2)FPN(特征金字塔网络)
论文地址:https://arxiv.org/abs/1612.03144
FPN包含两个主要路径:自上而下的路径(语义强、分辨率低的特征)和自下而上的路径(语义弱、分辨率高的特征)。此外网络添加了横向连接,连接重建的层和相应的特征图,以帮助检测器更好的预测目标位置。整个特征金字塔在所有层上都具有丰富的语义,并且可以在不牺牲特征表征、速度、内存的情况下快速构建。
总之,FPN是一种特征提取器,旨在构建各种尺度的高级语义特征图(金字塔概念)。FPN是多尺度特征提取器的改进,与其他目标检测模型中的特征提取器相比,如Faster R-CNN,包含更高质量的信息。
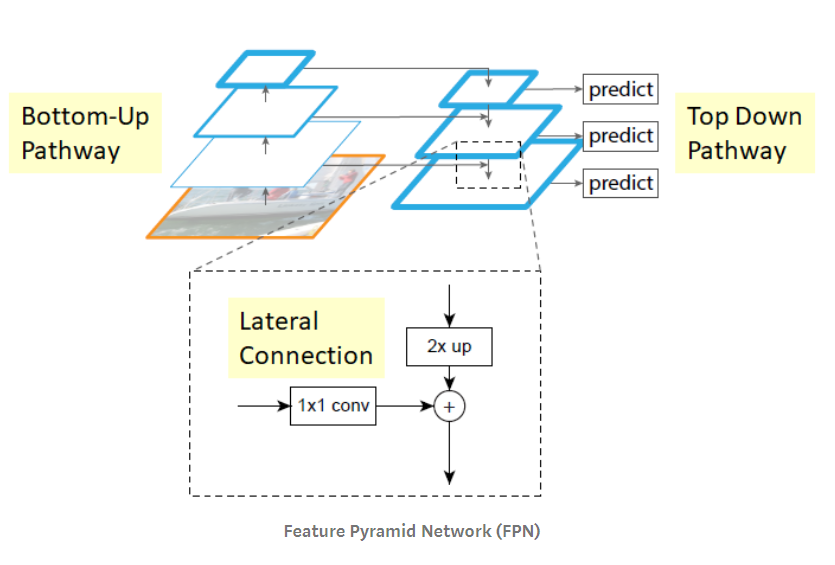
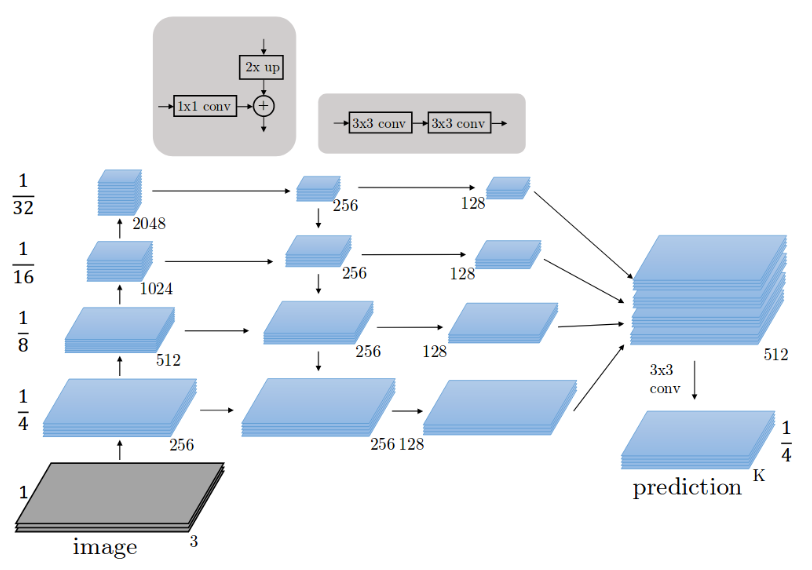
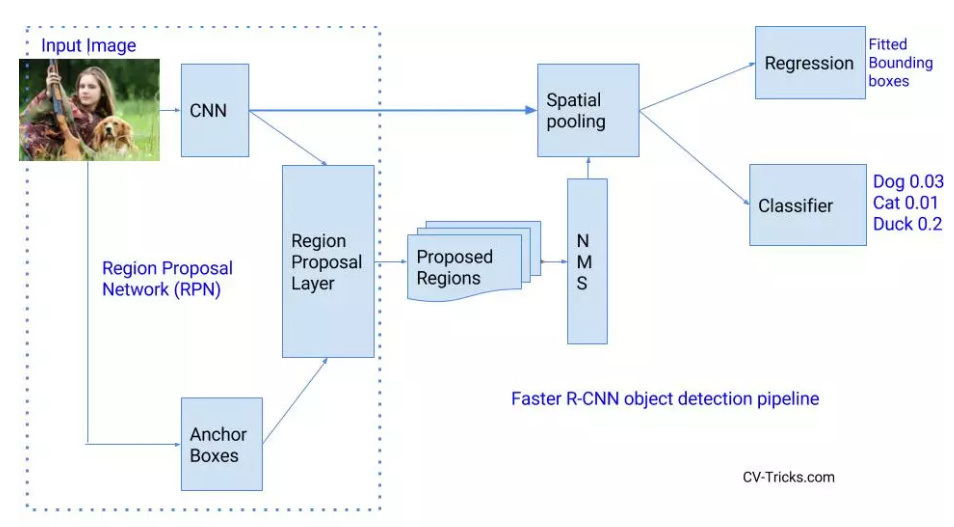
(3)Faster R-CNN(基于区域的卷积网络)
论文地址:https://arxiv.org/abs/1506.01497
在简单的目标检测算法中将CNN模型应用于单一图像,来检测我们感兴趣的对象。因为我们感兴趣的对象可能位于图像中的任何位置,因此我们通过对不同的区域多次应用不同的滑动窗口来重新训练网络,这种方法计算代价高昂并且非常耗时,因此需要尝试减少滑动窗口的数量。
R-CNN:Ross Girshick提出的R-CNN,使用选择性搜索算法为每张图片提取2000个区域建议(候选区域)。选择性搜索算法使用局部线索(如纹理、颜色等)产生对象的所有可能位置,CNN充当每个候选区域的特征提取器,最后线性SVM分类器对候选区域中可能存在的目标进行分类。但训练R-CNN计算代价依旧高昂,因为每个图片中依旧包含约2000个候选区域。
Fast R-CNN:之后同一研究者( Ross Girshick)设计了这个模型(R-CNN)的升级版本,称为Fast R-CNN,它使用了非常相似的方法,例如使用带有一些修改的选择性搜索方法 ,不需要产生2000个固定区域建议,而是通过两个主要操作提取一组区域建议:第一个操作是CNN模型特征提取,输出卷积特征图(全图特征);第二个操作是使用感兴趣区域池化层(ROI)从第一个操作的输出中识别区域建议,并提取特征。这种方法使得计算量减少。
Faster R-CNN:但选择性搜索方法依旧是一个非常耗时的操作,因此提出了一种称为Faster R-CNN的新模型。不使用选择性搜索算法,引入新的网络来产生区域建议,这使得Faster R-CNN比R-CNN和Fast RCNN都快。

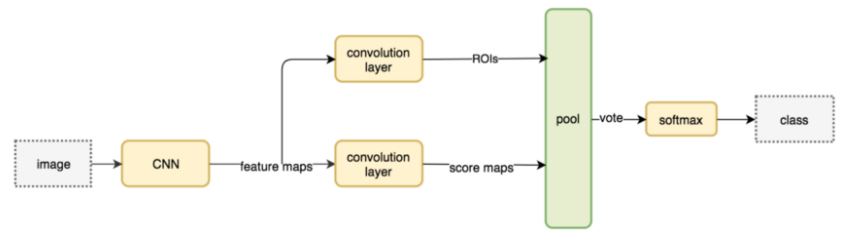
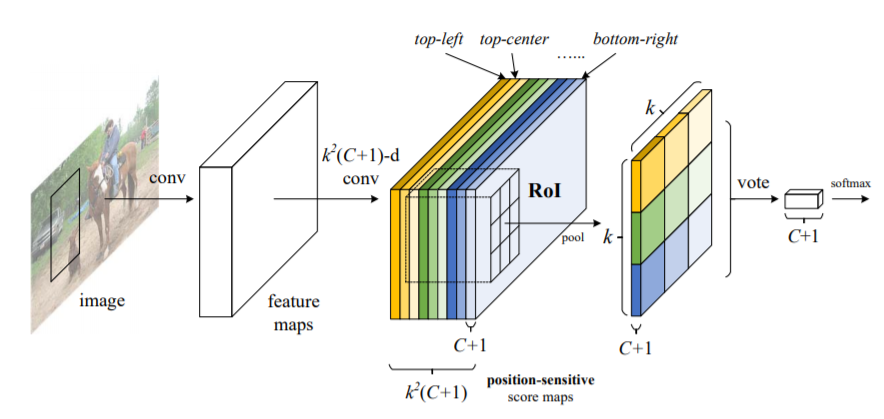
(4)R-FCN(基于区域的全卷积网络)
论文地址:https://arxiv.org/abs/1605.06409
同以前的基于区域的检测器(如R-CNN,Fast R-CNN和Faster R-CNN)数百次应用代价昂贵的区域子网相比,该论文的作者提出了一种新的基于区域的模型称为R-FCN,它具有全卷积的架构,几乎在整个图像上共享所有计算。作者提出了位置敏感得分图,以解决图像分类中的平移不变性与目标检测中的平移差异性之间的难题。因此,该方法可以采用全卷积的图像分类器主干(例最新的残差网络Resnet)来进行目标检测。
(5)模型之间精度和速度的比较
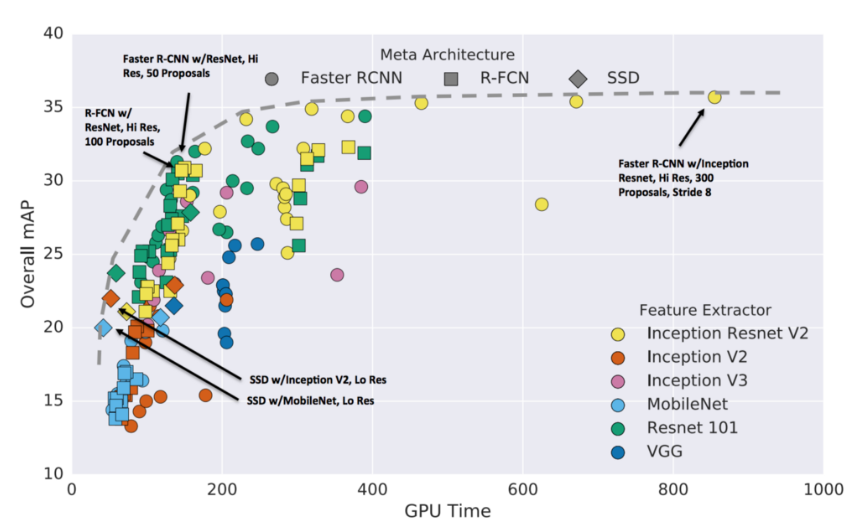
4.2 目标检测模型主干网络的关键功能
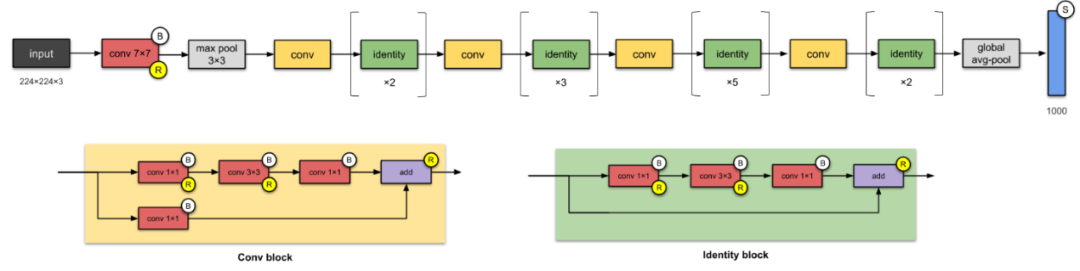
(1)Resnet50和Resnet101
论文地址:https://arxiv.org/abs/1512.03385
Resnet是一个非常深的网络,具有许多层,它是第一个使用跳跃连接来解决由于网络加深而引起梯度消失进而导致精确度下降问题的网络。它还应用了批量归一化技术,请注意Resnet101是比Resnet50更深的网络。
(2)Inception v2
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf
Inception_v2架构包含三个主要组件:首先,它在网络中间引入了两个附加的辅助分类器,以解决梯度消失问题;其次,由于同一层中的过滤器大小不同,因此与Resnet相比它具有更深更宽的网络(结构);最后,为了解决因为减少输入大小引发的信息丢失问题,网络通过使用两个3x3卷积(而不是一个5x5卷积)升级了Inception_v1。
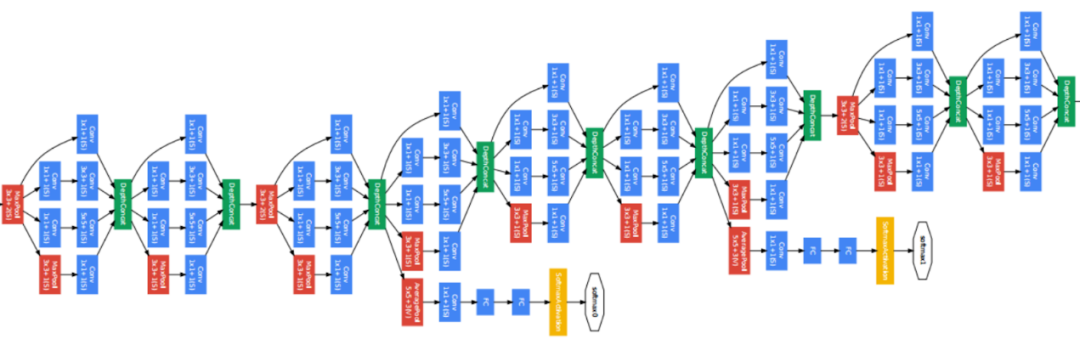
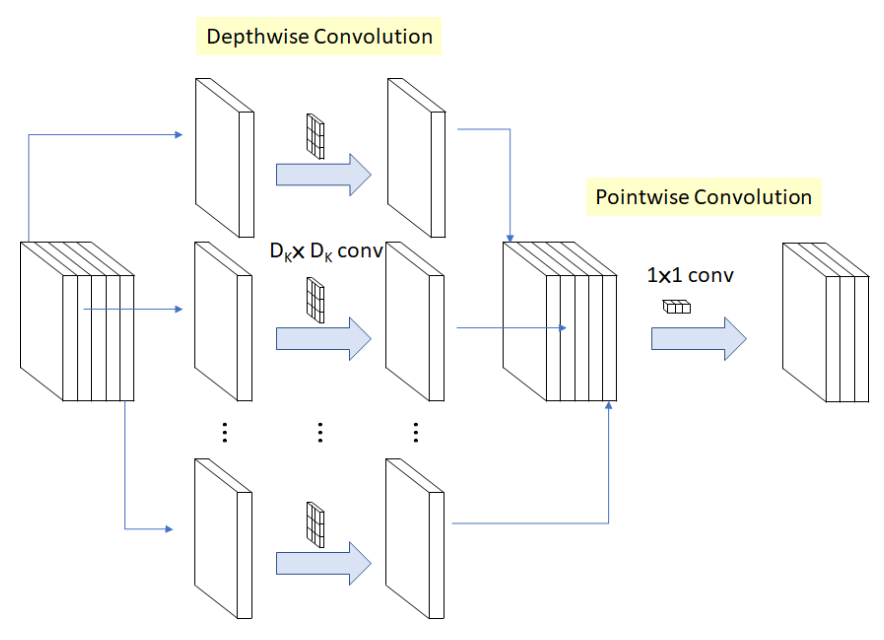
(3)Mobilenet v2
论文地址:https://arxiv.org/abs/1704.04861
Mobilenet的关键是它使用深度可分离卷积来构建轻量级深度网络。这意味着网络在应用逐点卷积之前先应用逐通道卷积。标准卷积可以通过单个操作进行过滤和合并,但深度可分离的卷积,这个操作是在单独的两个步骤上完成的,从而加快了计算速度。
(4)模型之间精度和速度的比较
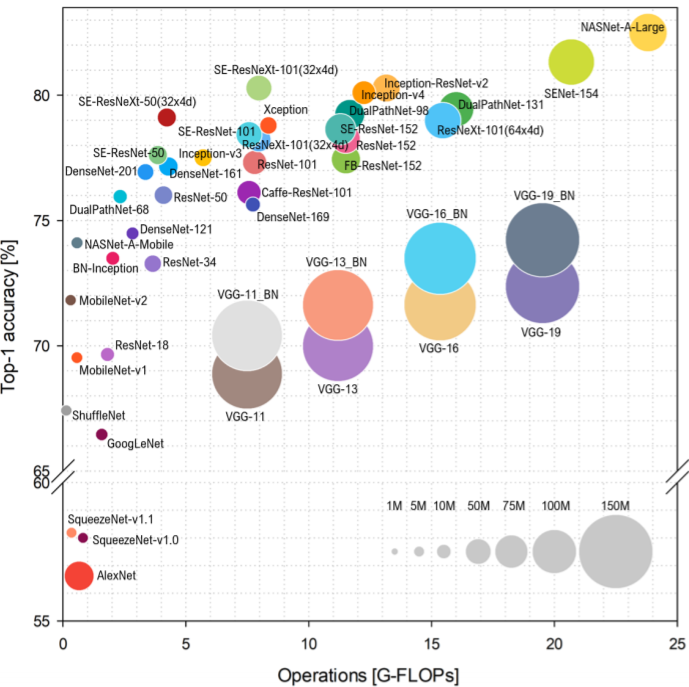
注意:
1. 复杂性可以用浮点运算或寻找解决方案所需的触发器来表示,这意味着触发器是计算的基本单位,触发器的数量表示执行一系列操作的成本。
2. Inception v3具有与Inception v2相同的架构,但有一些小的更改。
从上图中,就计算时间而言,我们可以为使用的每个模型按从最快到最慢的顺序排列,分别是:Resnet101、Inception_v3、Resnet50和Mobilenet_v1。另一方面,按最高到最低的准确性顺序排序,分别是Inception_v3、Resnet101、Resnet50和Mobilenet_v1。
5 评估
目标检测模型包含两个主要任务:第一个任务是分类任务,用来判断图片中是否包含我们感兴趣的对象;第二个任务是定位任务,用来确定图像中我们感兴趣对象的位置。此外,我们的数据集存在正负样本高度不平衡和不同类别违禁物品分布不规则的问题,因此仅使用准确性度量评估模型是不够的,还需要评估我们的模型对感兴趣对象和非感兴趣对象进行错误分类的可能性,因此基于图像中我们感兴趣对象周围的每个边界框评估模型得分或者置信度分数,以便在任何可接受阈值下评估我们模型对目标位置和类别的预测能力。平均精度(AP)是目标检测任务常用的度量,我们还需要理解一些重要的概念,例Precision-Recall曲线、AP和IoU。
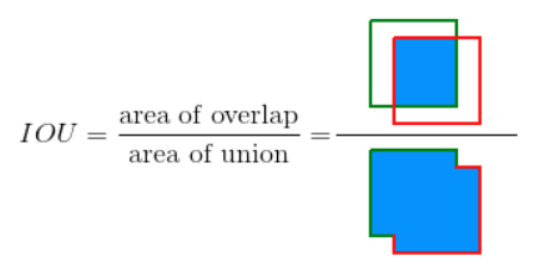
5.1 交并比阈值(IoU)
在评估目标检测模型是否能分类违禁物品的类别并预测这些物品在图像中的位置的重要阈值是交并比阈值(IoU),IoU是目标真值框和我们模型预测框之间相交的面积与并集的面积的比值。
5.2 精确度-召回率曲线(Precision-Recall曲线)
我们的项目中样本和类别不平衡,精确度-召回率度量是预测成功的一个十分有用的度量。
精确度(P)是真实正样本(TP)的数量除以真实正样本和错误正样本(FP)数量的和。[P=TP/(TP+FP)]
召回率(R)是真实正样本(TP)的数量除以真实正样本(TP)和错误负样本(FN)数量的和。[R=TP/(TP+FN)]
为了评估这些指标,我们需要选择一些阈值来考虑模型的预测方向。
真实正样本(TP)是IoU>=阈值的正确预测
错误正样本(FP)是IoU<阈值的错误预测
错误负样本(FN)是对感兴趣对象的漏检
真实负样本(TN)是目标检测模型的隐式度量,真实负样本是不包含我们感兴趣对象的边界框,在每张图片中有很多这样的边界框。我们不需要显示测量真实负样本,因为上面的其他措施可以在相反的方向执行类似的功能。
精确度是我们模型检测感兴趣对象的能力,召回率是我们的模型可以找到我们感兴趣对象的所有相关边界框的能力。从精确度和召回率的公式可以看出精确度不会随着召回率的降低而降低。
精确度TP/(TP+FP)的定义表明:降低模型阈值可能会通过增加相关返回的结果来增加分母,如果阈值设置的太高,会增加返回结果的真实正样本的数量,进而提高精确度;而如果之前的阈值大致正确或太低,进一步降低阈值会增加错误正样本的数量,因而降低精确度。召回率R=TP/(TP+FN)的定义表明:FN不依赖于选择的阈值,这意味着降低阈值可能通过增加真实正样本的数量来提高召回率,所以降低阈值可能会导致召回率保持不变时精确度发生波动。但选择正确的阈值很难,因此我们宁愿找到所有可能的阈值取它们的平均值,这就是为什么平均精度(AP)非常重要的原因。
精确度和召回率曲线:展示了针对不同阈值,精确度和召回率之间的权衡。曲线下的高区域代表高召回率和高精度,其中高精确度和低FP有关,高召回率和低FN有关,两者的高分都表明我们的模型返回了准确的结果(高精度),并且返回了大部分真实正样本(高查全率)。
召回率高但精度低的模型可以将大多数边界框定位在我们感兴趣对象的周围,但是与真实标签相比,这些对象的大多数预测类都不正确。精度高而召回率低的模型则相反,通过定位很少相关边界框,但与真实标签相比这些边界框大多数预测类都正确。总而言之,我们希望具有高精确度和高召回率的模型,因为它们将返回许多相关的边界框,且所有结果均正确标记。
5.3 平均精度(AP)和平均精度均值(mAP)
平均精度(AP)将精确度-召回率曲线总结为,在每个阈值水平上,作为权重的前一个阈值的召回率的增加所达到的平均精度(AP)。[AP=∑n(Rn−Rn−1)Pn ]其中,Pn和Rn是在第n个阈值处的精确度和召回率,根据上面的公式,AP是每个阈值在所有召回率上的平均精度。
平均精度均值(mAP)定义为:所有不同类别的平均精度的平均值,但有两种不同类型的mAP:Micro mAP和Macro mAP,Macro mAP为我们感兴趣的每一类对象独立地计算AP度量,然后计算平均值,这意味着Macro mAP平等对待所有类;相反Micro mAP将汇总所有类别的贡献以计算AP指标。
结果:
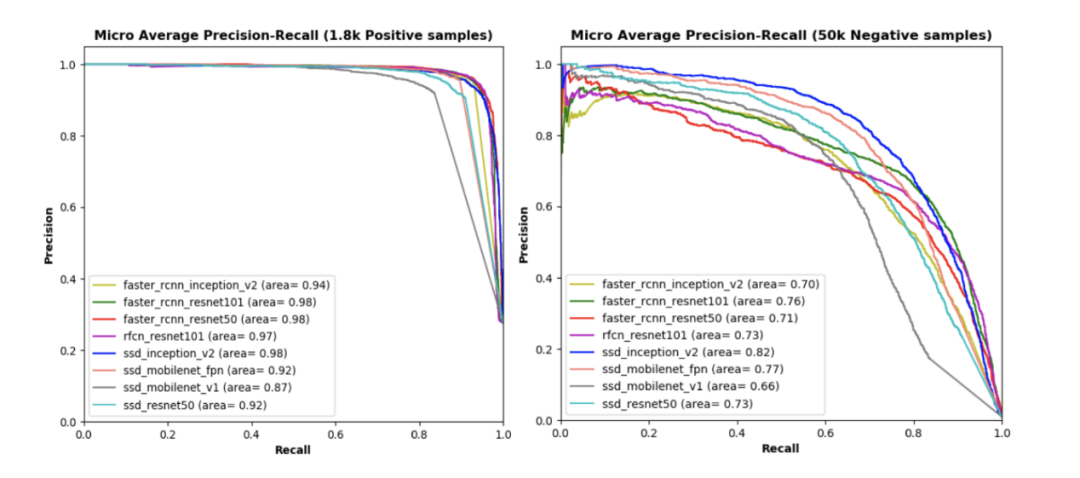
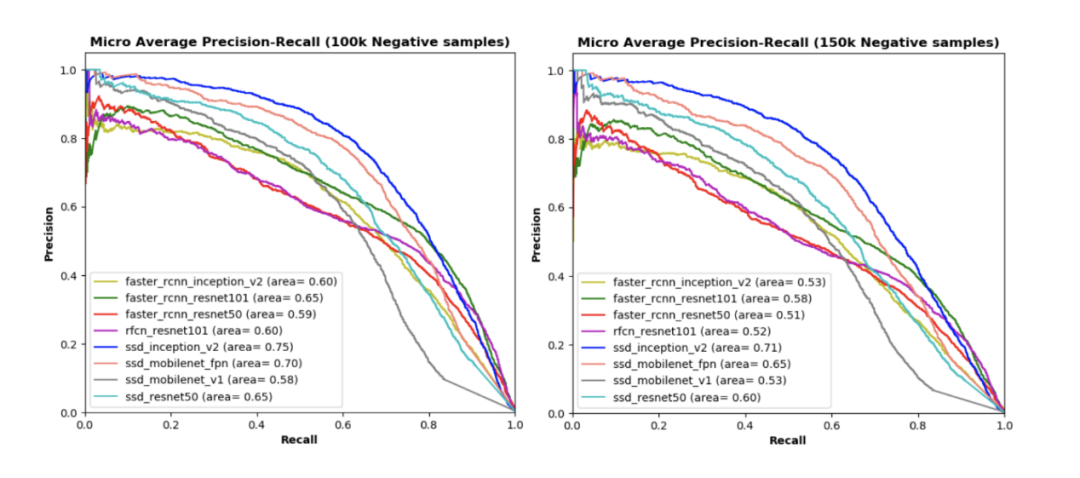
我们用7200个正样本训练所有模型,同时用另外1800个正样本以及不同数量的负样本(分别是50000、100000和150000)进行评估。上面所有图表是在具有不同正样本和负样本比例的测试数据集下,不同模型的精确度-召回率曲线,曲线下的面积越大,每个阈值处的精确度和查全率都越高。
图表可知:
(1)左上方图像,仅使用1800个正样本而不使用任何负样本来测试我们的模型,尽管SSD_Mobilenet_v1曲线下的面积比其他模型相对较小,但每个模型曲线下的面积都很高。其余三幅图像显示了使用测试数据集的不同子集(即50000、100000和150000负样本)测试每个模型时的性能;
(2)与每种测试数据集下的其他模型相比,SSD_Inception_v2模型曲线下的面积最大,此外在测试数据集的正样本和负样本的每个比率中,基于SSD的模型(例如SSD_Mobilenet_v1_fpn和SSD_Resnet50)在曲线下的面积也比其他模型(例如R-FCN和Faster R-CNN)高(SSD_Mobilenet_v1除外)。
(3)在每个测试数据集中,SSD_Mobilenet_v1曲线下的面积最低,这意味着我们模型的性能不仅依赖于检测网络,而且还依赖于网络后端(如用于特征提取的不同CNN模型)。
(4)基于Inception_v2、Mobilenet_v1_fpn和Resnet50的SSD检测模型优于具有类似网络后端的R-FCN和Faster R-CNN模型。相比之下,使用简单提取网络(例如Mobilenet_v1)的SSD模型在我们所有模型中表现最差。
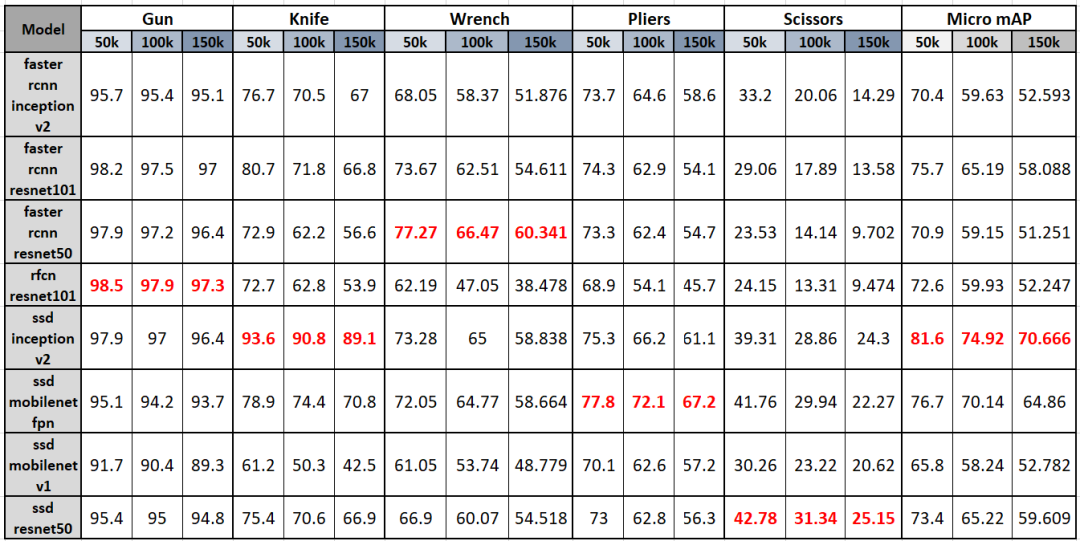
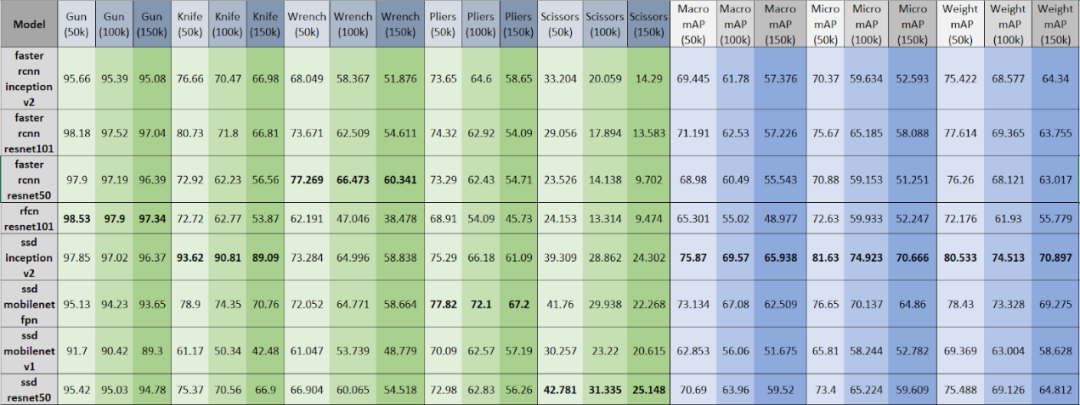
表显示了不同模型在包含不同比例违禁物品的测试数据集中的平均准确度(AP),最后三列显示了每个模型在不同比例的数据集下,每种违禁物品类别的平均准确度均值(mAP)。
从该表可以明显观察到:
(1)随着将更多负样本添加到测试数据集中(从50k到150k),AP和mAP都相应减少。
(2)对于枪类,RFCN_Resnet101性能最佳,其他模型(如Faster_RCNN_Resnet50 / 101和SSD_Inception_v2)非常接近;对于刀类,SSD_Inception_v2AP最高且性能大大优于其他模型,无论是枪类还是刀类,最佳模型的AP可达90%;对于扳手和钳子类别,Faster_RCNN_Resnet50和SSD_Mobilenet_v1_fpn分别具有60-80%的最高AP;但对于剪刀类,SSD_Resnet50具有最高AP但也仅有20%至40%,这意味着剪刀类可能是最难检测到的违禁物品,因此建议机器学习工程师使用更多的剪刀类修改模型或添加更多数据。
总体而言,我们的项目使用Micro mAP来评估每个模型的总体性能。SSD_Inception_v2具有最高的Micro mAP,这与我们之前对平均召回率曲线的分析一致。
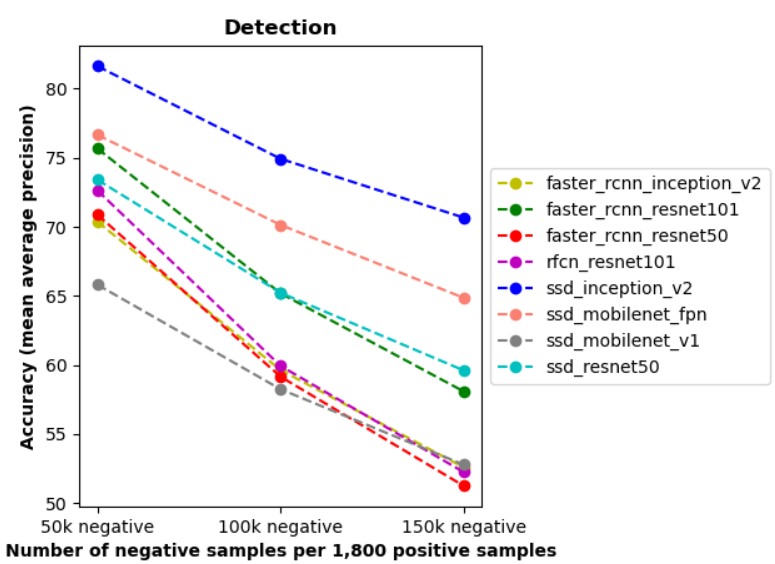
上面的折线图通过使用每个模型的Micro mAP分数总结了上表的最后三列。SSD_Inception_v2是我们项目中最好的模型,其次是SSD_Mobilenet_v1_fpn,在所有模型中SSD_Mobilenet_v1的性能最让人失望。
6 数据产品
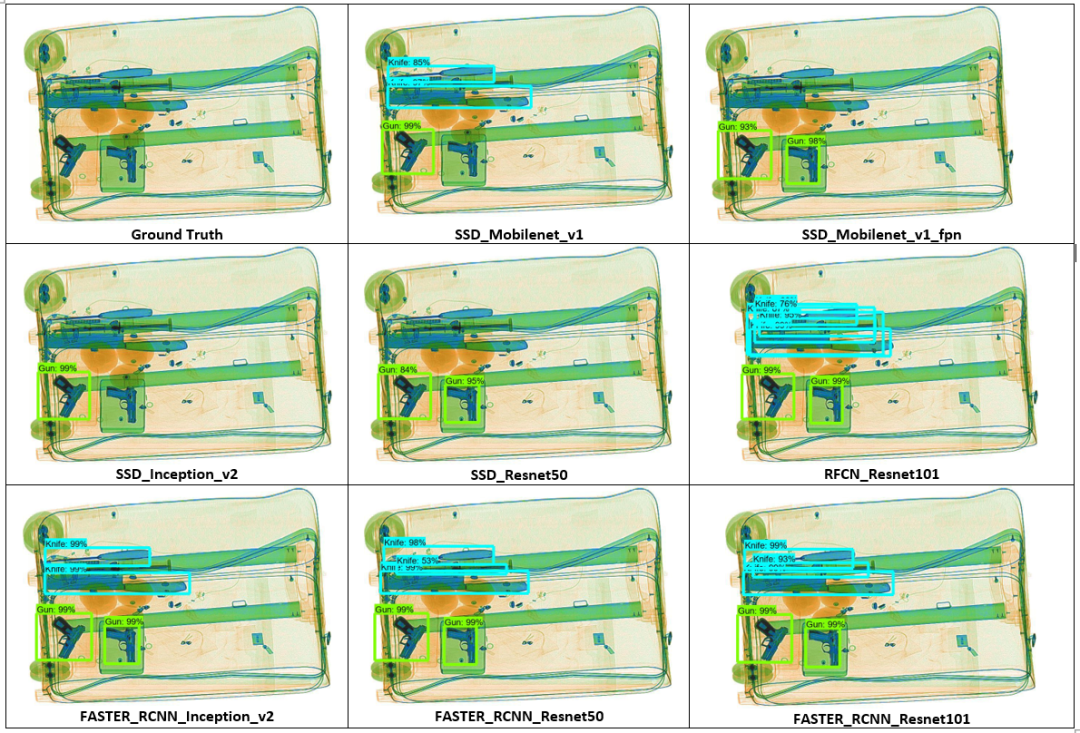
测试图像显示了我们训练的不同目标检测模型的性能以及图像的真实情况。
第一张测试图像中我们可以看到,该行李图像中有四个危险物品,包括两把枪和三把重叠的刀。所有模型中,SSD_Mobilenet_v1_fpn、SSD_Inception_v2和SSD_Resnet50都只能检测到枪支而忽略了所有刀,而其余模型则可以同时检测到枪和刀,RFCN_Resnet101和Faster_RCNN_Resnet101同其他模型相比具有最佳性能,尽管RFCN_Resnet101在违禁物品上放置了更多边界框,但它们可以非常高精度地检测到所有四个违禁物品。
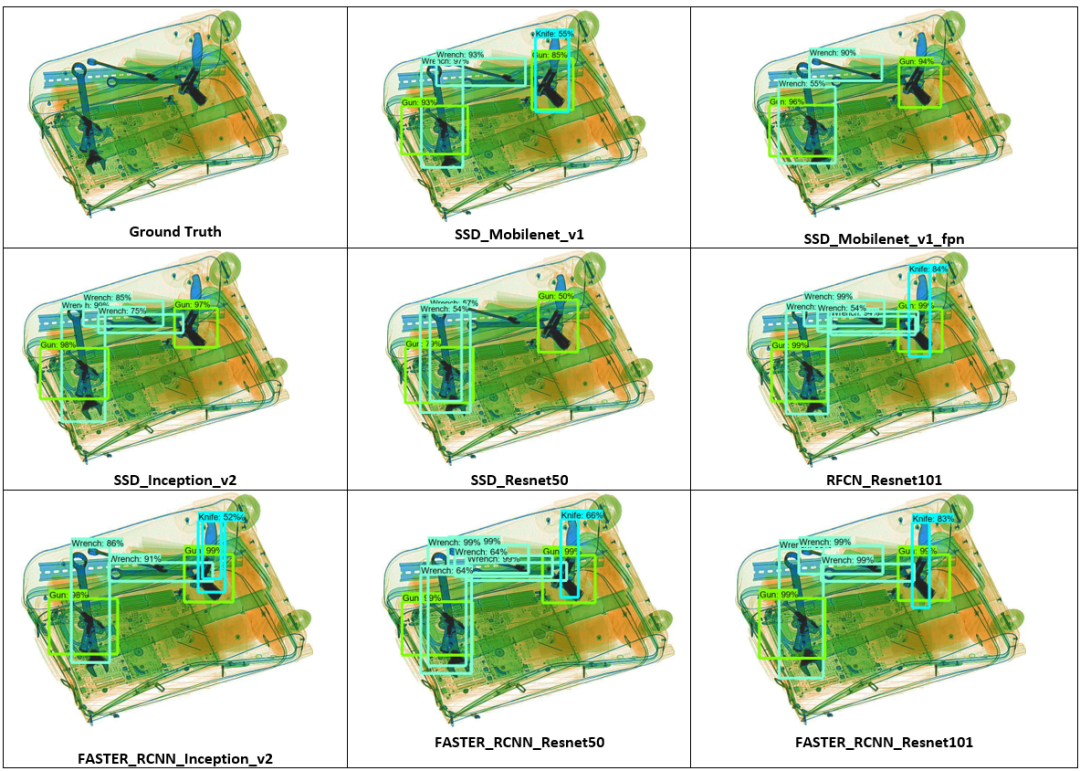
第二张测试图像比上一张更具挑战性,有三种不同类型的危险物品:扳手,枪和刀。从真实图像中可以看到有三把扳手,两把枪和一个刀随机地散布和重叠。SSD_Mobilenet_v1_fpn和SSD_Inception_v2可以检测到扳手和枪支漏检了刀,相反除SSD_Resnet50之外的其他模型都可以检测到所有这三种违禁物品。SSD_Resnet50可以以非常低的准确度分数检测枪支和扳手却漏检了刀和扳手。RFCN_Resnet101、Faster_RCNN_Resnet101和Faster_RCNN_Resnet50在这个图像中表现最佳,因为它们能够识别所有违禁物品并且以高的准确率得分对其定位。
7 经验教训
从该项目中可以学到如下三点:目标检测模型如何工作;为什么需要目标检测模型;如何评估目标检测模型的性能。
(1)为什么使用目标检测而不是分类模型?通常,我们选择CNN模型来解决图像分类问题,然而在这个项目中CNN不能为X射线数据集中的图像识别并定位违禁物品,例我们尝试了VGG16和Resnet50模型,但结果令人失望。为了解释这种现象,我们对计算机视觉进行了一些研究,发现仅分类模型并不适合解决该项目的问题,该项目中具有挑战性的任务包括特征提取和多目标定位。相反,我们实现了一种更好的替代方法,即目标检测模型。
(2)不同的目标检测架构。例如Faster R-CNN、SSD、R-FCN和FPN。在前面的部分中已经详细解释了它们的结构、功能和优点。为了实现目标检测模型,我们使用Tensorflow目标检测API并在Google Cloud平台上训练,我们训练了几种模型并评估了它们的性能。
(3)模型评估指标。在评估部分,我们了解了模型评估指标的三个新概念,包括精确度-召回率曲线、平均精确度(AP)、平均精确度均值(mAP)和交并比(IoU)阈值。我们使用AP和Micro mAP作为主要指标来评估所有训练的目标检测模型,并选择性能最佳的模型。
未来工作:
(1)为了提高目标检测模型的准确性,我们需要添加更多‘正’图,未来也可以将一些负样本整合到训练集中。尤其需要添加包含剪刀类的图像,对于我们的所有模型来说识别剪刀似乎都是最困难的,检测剪刀性能最佳的模型也只能获得42%的精度,一个可能的原因是我们的数据集中缺少剪刀图像,因为我们只有983个带有剪刀的图像,这远低于其它类别;我们当前的数据集正样本和负样本不平衡(具有8929个正图像和1050302个负图像),并且在每个类别中包含违禁物品的图像数量也不平衡,我们的项目只使用正图像来训练模型,但正图像仅占不到1%,并且测试数据集仍然需要其中的一些图像,未来我们可以将一些负样本整合到我们的训练数据集中。
(2)对模型的时间和准确性做出权衡。由于某些应用程序需要实时目标检测,因此在这种情况下,具有最高准确度但训练和评估速度慢的模型可能不适合。
8 总结
项目目标:找到能够正确分类X射线图像中的违禁物品并精确定位的最佳算法。
项目数据集:使用一个大规模数据集——SIXray数据集,由超过一百万个X射线图像组成,这些X射线图像由不同数量的违禁物品和非违禁物品组成。
项目模型:由于分类CNN模型的性能不佳,改为使用目标检测模型来解决此问题;选择了许多目标检测架构,例如SSD、Faster R-CNN、FPN和R-FCN,它们具有不同的特征提取器后端,如CNN模型(包括Resnet,Inception和Mobilenet);我们成功地训练了8个目标检测模型,并评估了每种模型的性能,以便在我们的不平衡数据集中找到性能最佳的模型,使用平均精确度均值(mAP)来测量每种模型在预测不同类别违禁物品时的总体性能,在该项目中SSD_Inception_v2被证明是最合适的模型,具有最高的平均精确度均值得分。
未来工作:优化模型的性能,以提升预测剪刀等违禁物品的性能,由于剪刀图像的数量仅占整个数据集的0.001%,一种可能的解决方案是增加训练数据集的数量,如添加更多的正样本。
额外图像:

T
参考
1.SIXray Dataset: https://github.com/MeioJane/SIXray
2.SIXray: A Large-scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images:
https://arxiv.org/pdf/1901.00303.pdf
3.Tensorflow Object Detection API document:
https://github.com/tensorflow/models/tree/master/research/object_detection
4.Tensorflow Object Detection Model zoo:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
5.Tensorflow Object Detection Model Config files:
https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs
6.Feature Pyramid Network:
https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
7.COCO Dataset: http://presentations.cocodataset.org/COCO17-Stuff-FAIR.pdf
8.R-FCN Research paper: https://arxiv.org/abs/1605.06409
9.R-FCN explanation:
https://medium.com/@jonathan_hui/understanding-region-based-fully-convolutional-networks-r-fcn-for-object-detection-828316f07c99
10.Resnet Research paper: https://arxiv.org/abs/1512.03385
11.Inception Research paper: https://arxiv.org/pdf/1512.00567v3.pdf
12.Mobilenet Research paper: https://arxiv.org/abs/1704.04861
13.Mobilenet explanation:
https://towardsdatascience.com/review-mobilenetv1-depthwise-separable-convolution-light-weight-model-a382df364b69
14.Object Detection metric reviews:
https://blog.zenggyu.com/en/post/2018-12-16/an-introduction-to-evaluation-metrics-for-object-detection/
15.Object Detection metric explanation:
https://medium.com/@timothycarlen/understanding-the-map-evaluation-metric-for-object-detection-a07fe6962cf3
16.Faster R-CNN explanation: https://towardsdatascience.com/review-faster-r-cnn-object-detection-f5685cb30202
17.Introduction to Object Detection:
https://machinelearningmastery.com/object-recognition-with-deep-learning/
18.Object Detection model reviews: https://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
19.History of R-CNN, Fast R-CNN, and Faster R-CNN:
https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
20.Should we integrate Negative samples into training dataset:
https://stats.stackexchange.com/questions/315748/object-detection-how-to-annotate-negative-samples
21.Object Detection metrics: https://github.com/rafaelpadilla/Object-Detection-Metrics
22.Scikit-learn Precision-Recall:
https://scikit-learn.org/0.15/auto_examples/plot_precision_recall.html
23.Mean Average Precision: Micro vs Macro:
https://datascience.stackexchange.com/questions/15989/micro-average-vs-macro-average-performance-in-a-multiclass-classification-settin
24.Mean Average Precision: https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
25.Benchmark Analysis of Representative Deep Neural Network Architectures:
https://arxiv.org/pdf/1810.00736.pdf
26.Flop Definition:
https://www.stat.cmu.edu/~ryantibs/convexopt-S15/scribes/09-num-lin-alg-scribed.pdf
27.Object Detection speed and accuracy comparison:
https://mc.ai/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo/
28.Single Shot Detection(SSD):
https://medium.com/@jonathan_hui/what-do-we-learn-from-single-shot-object-detectors-ssd-yolo-fpn-focal-loss-3888677c5f4d
29.R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,”inCVPR, 2014
30.R. Girshick, “Fast r-cnn,” inICCV, 2015
31.Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” inNIPS, 2015,pp. 91–99.
32.K. He, G. Gkioxari, P. Doll ́ar, and R. B. Girshick, “Mask r-cnn,” inICCV, 2017
33.D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalable object detection using deep neural networks,” inCVPR, 2014
34.Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inCVPR, 2016
35.J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,”arXiv:1612.08242, 2016
36.W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, andA. C. Berg, “Ssd: Single shot multibox detector,” inECCV, 2016.
最后的最后求一波分享!
回复“DL2020”,获取 台大美女老师 《应用深度学习》课程资料和视频 end
个人微信 请注明:地区+学校/企业+研究方向+昵称 如果没有备注不拉群!
