技术选型 | OLAP大数据技术哪家强?
数据分析挖掘与算法
共 3157字,需浏览 7分钟
·
2021-02-15 13:38


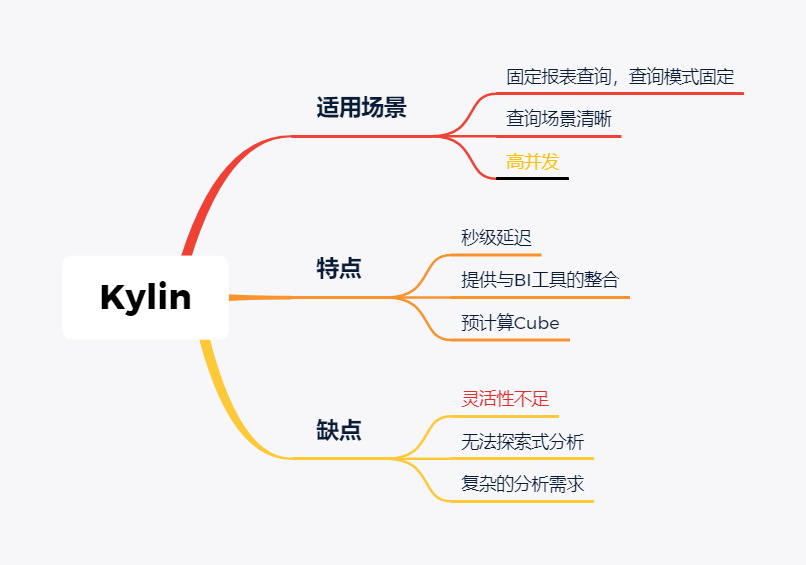
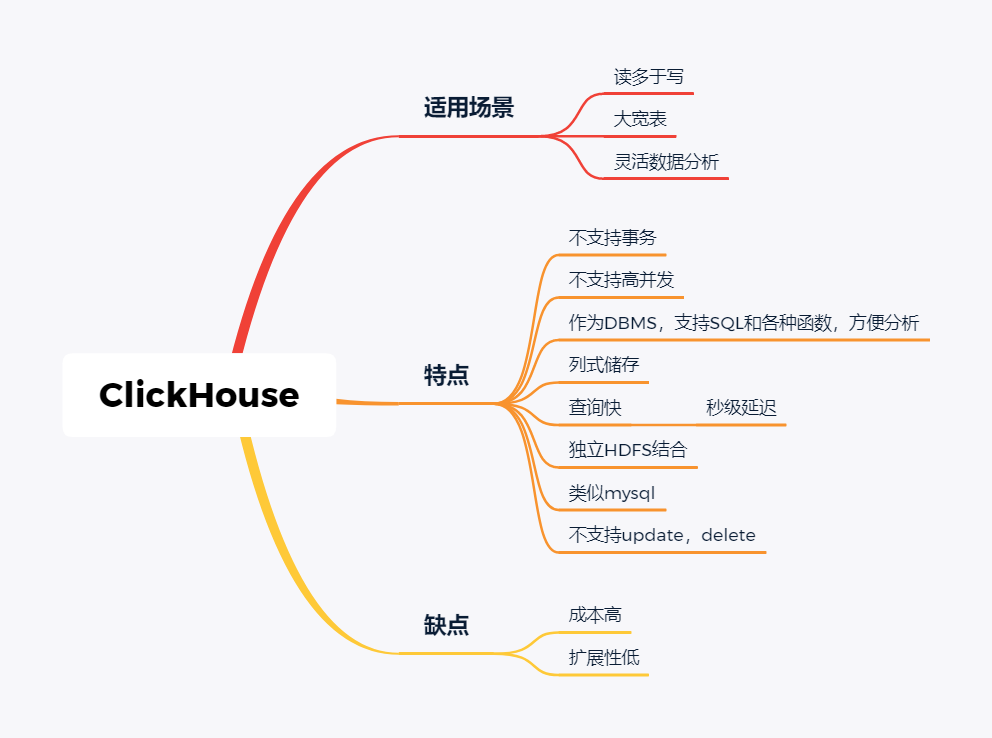
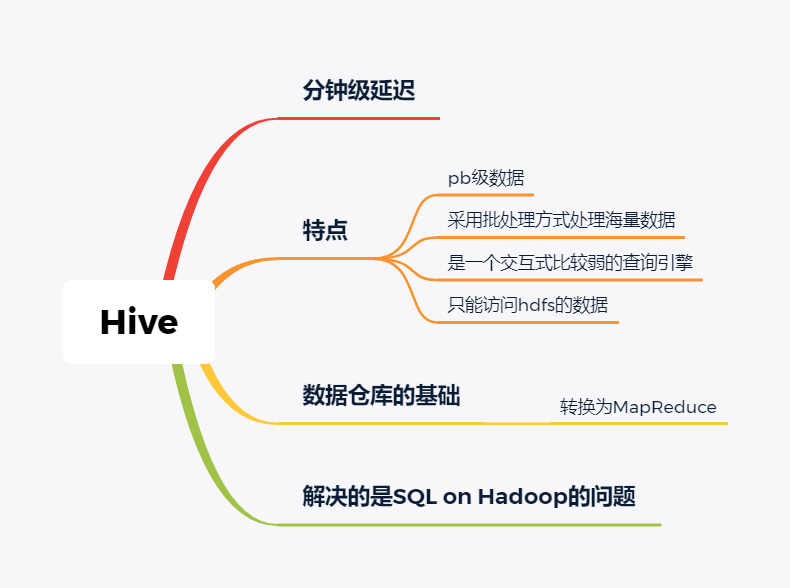
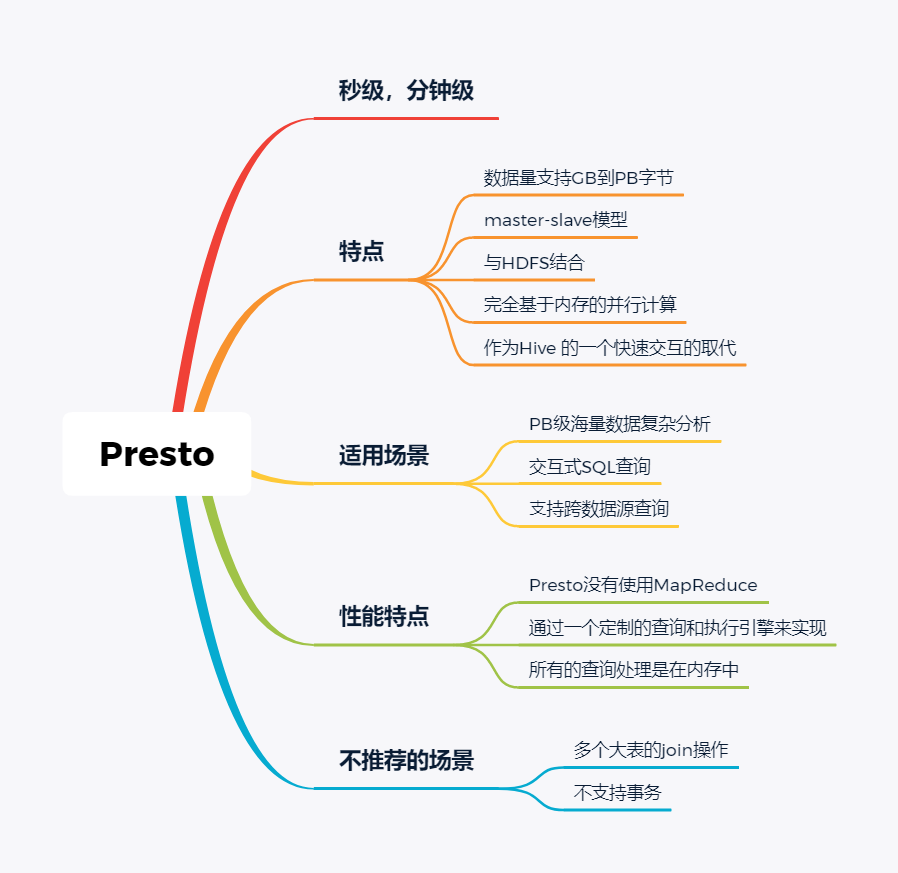
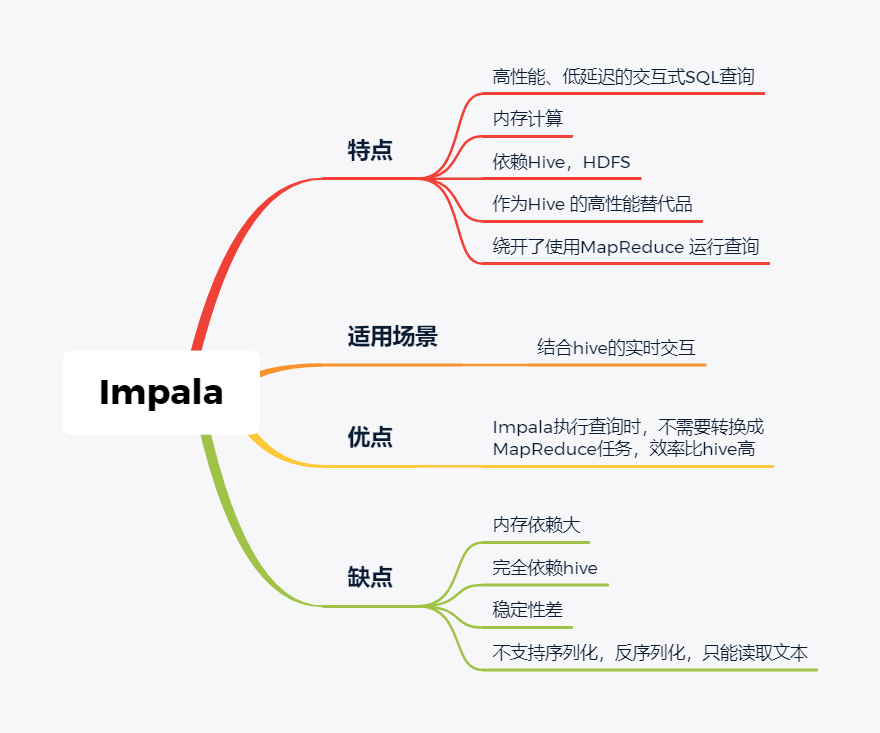
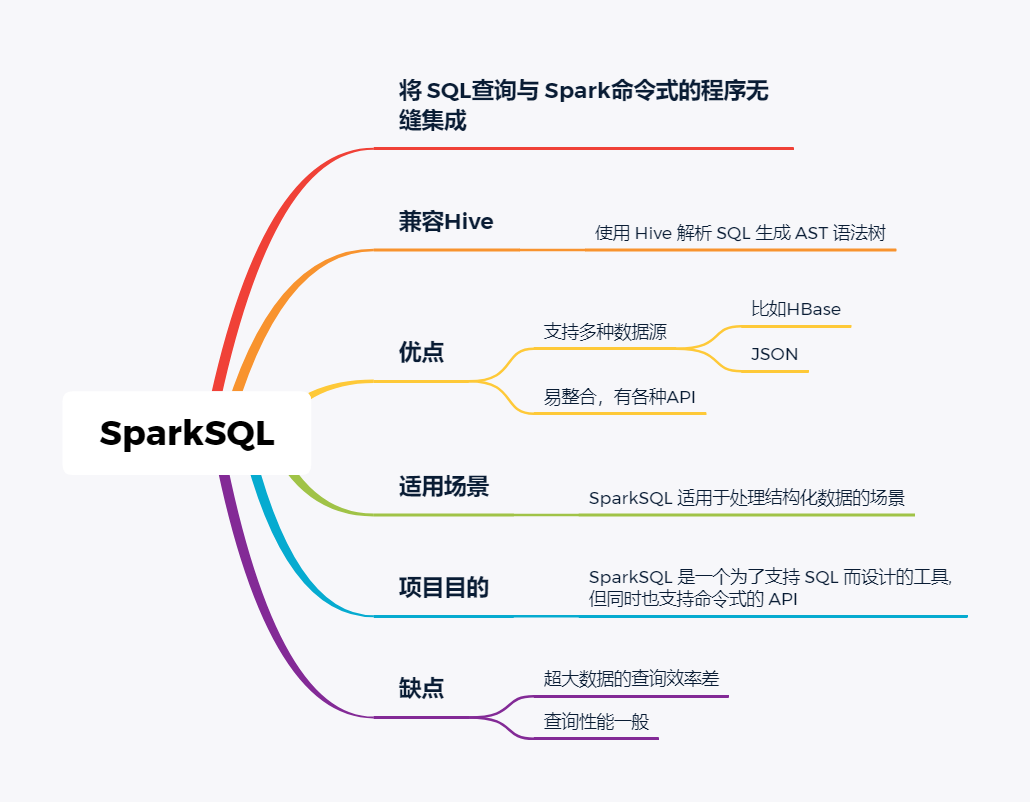
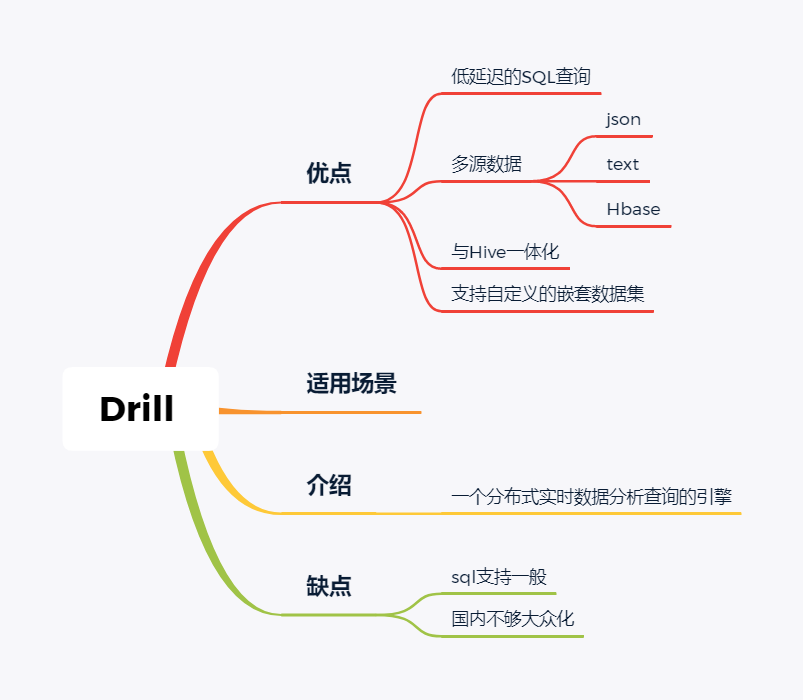
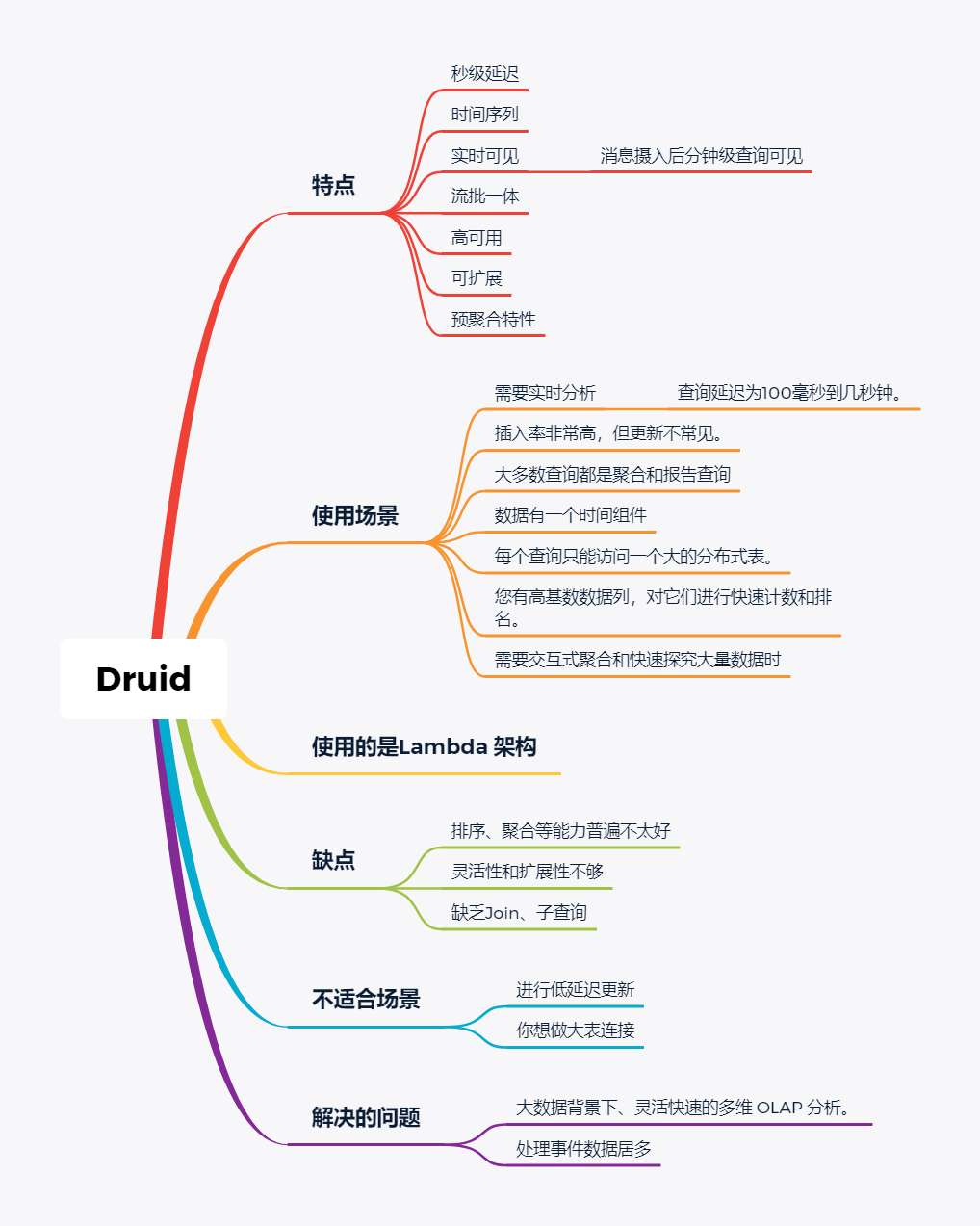
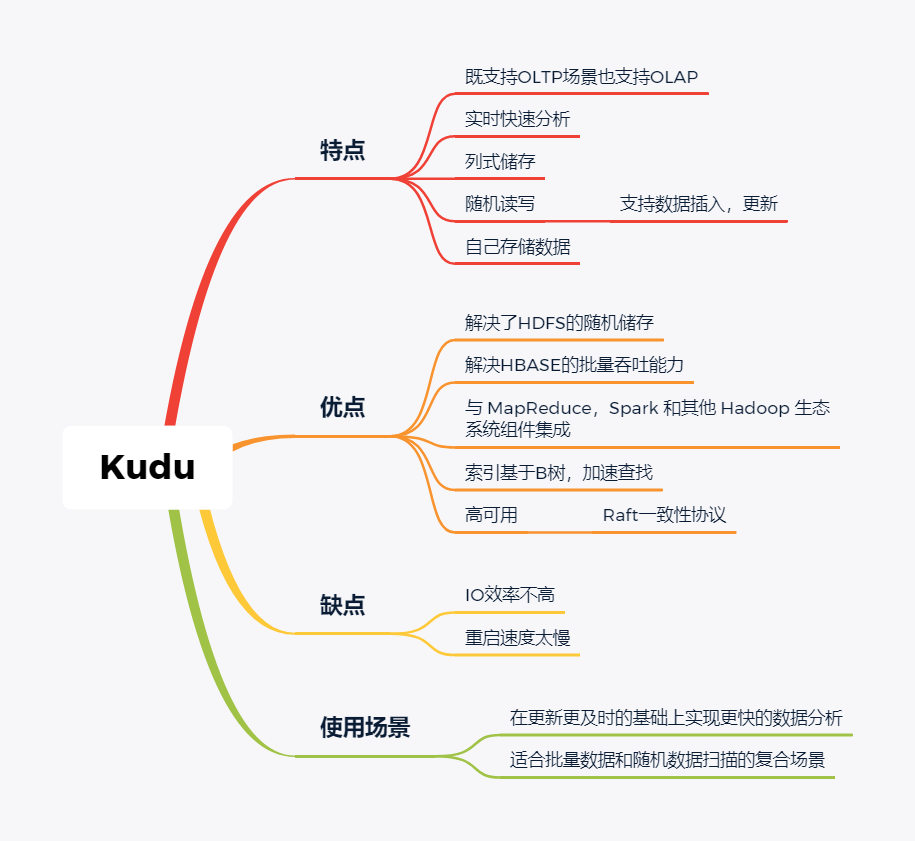
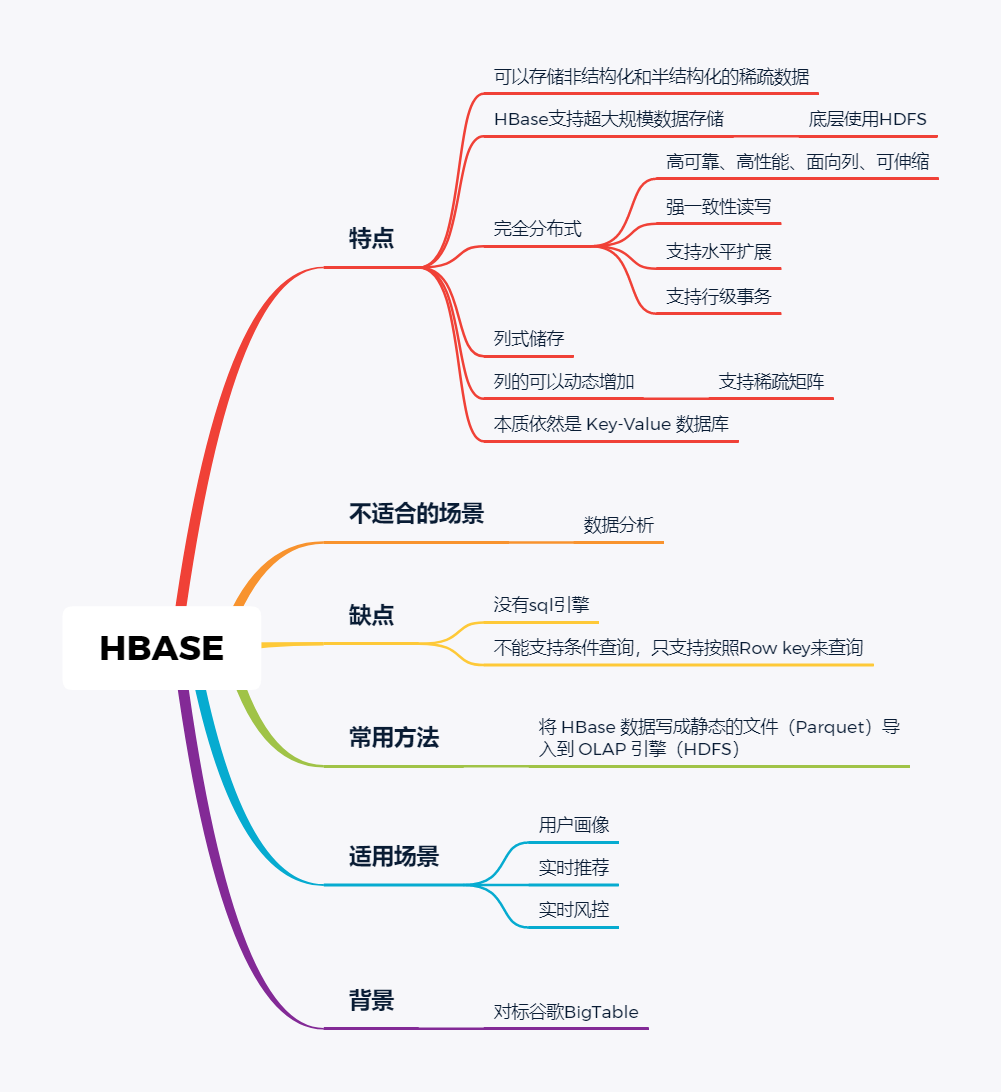
随着大数据组件越来越多,很多组件都是为OLAP数据服务的,什么组件或者组件组合最合适可能是我们关注的问题。本文大体分析业内常见的组件特点,给大家挑选组件提供借鉴。
评论

共 3157字,需浏览 7分钟
·
2021-02-15 13:38
随着大数据组件越来越多,很多组件都是为OLAP数据服务的,什么组件或者组件组合最合适可能是我们关注的问题。本文大体分析业内常见的组件特点,给大家挑选组件提供借鉴。