
视觉SLAM怎么去提高定位精度?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|计算机视觉life

EpsAvlc:
这个事情的回答需要基于你的动机。
如果你想改进已有的算法以获得在数据集上的视觉里程计定位精度上的提升,那么我的判断是比较难。
如果你是在实际场景中发现已有的框架(例如ORB-SLAM)的定位精度不能达到论文中,或者你预想的精度,那么这个事情是可以根据实际场景讨论的。
2020-6-27 KITTI榜单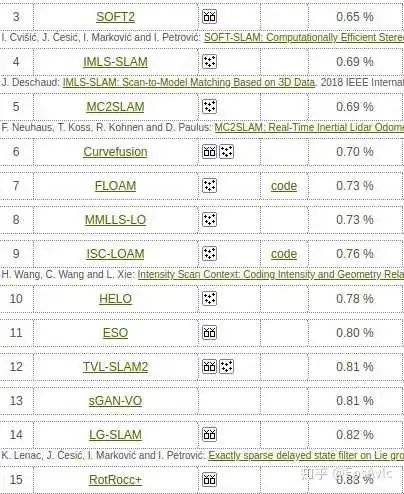 Kitti
Kitti
排名6, 11, 12, 14, 15的方案是基于视觉的,或者至少融合了视觉。其漂移误差大都低于1%。这是什么概念?我本科时参加的机器人竞赛里,经过仔细标定的轮式里程计,精度也不过1%。当然,视觉里程计的最终漂移误差一般都是回环后再算的,直接使用的话根据前端的调教程度,大概可以看做1%左右。不过无论怎样,对于增量式的定位方案,1%的误差应该都可以算是差强人意了。想要再有提升还是挺困难的,要么就加入许多Trick(过拟合数据集),但是感觉意义不大。
如果是在一些复杂场景下需要提升定位精度,那么还是有许多事情可以做的。像之前答主提到的,用语义分割,将动态物体上的特征点滤去,以提升BA精度。我认为有一些场景,是目前已有的框架力所不能逮的:
1.Long-term场景。如何保证夏天建的室外地图,在冬天也能用?这涉及到季节不变的路标的设计与提取。语义分割天然就有long-term特性,将语义分割考虑进去是一个较好的方法。
2.高度动态的场景。比如走在去菜市场的路上,来往人群很多。人是可以精确定位的,但是SLAM可能就要抓瞎了。
3.纹理缺失的场景。这算是室内SLAM时经常需要面对的事情了。
这三个问题,其实都有许多工作已经在做了。谷歌学术上搜索相关关键字就有。
就像综述《Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age》标题所述,目前鲁棒才是SLAM的关键命题。发布于 06-27
郑纯然:
可以做一些深度学习辅助提取路标的工作,比如:如果已经知道图像中某个物体属于一个既定的类别,然后再提角点,就会比针对全图提角点鲁棒性高很多。
刘宴诚:
具体细节太多了,ORBSLAM2这个框架基本上所有的代码都在围绕如何提高特征点的质量。其实想想特征点法提高定位精度无非就是如何保证特征点匹配的准确以及特征点选取的准确,可问题就出在无法保证百分百绝对精确,所以通过很多骚操作把这个事情做到极致,就可以提高定位精度了。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~