两个案例搞定数据指标口径的一致性
数据管道共
1883字,需浏览
4分钟
·
2020-09-05 22:27
在数据仓库中,常常使用一些中间表来做数据的过度,这些中间表的产生,都是依托于基础的埋点表/业务明细表/用户明细表等,旨在提高数据提取与输出的效率。客户端上报的埋点数据,或者某个功能的明细表,需要与用户明细表做关联可使用。这些数据一天的产生都是以亿级为单位,数据人员如果每次都将这些数据重跑一次,数据复用性低下,势必会造成资源和人员的浪费,有些使用第三方数据库(阿里云)的公司,每次数据提取都是需要钱的,数据量大的话,每次损耗也不少。同时,明细表的数据存储,有时会依托于业务,逻辑比较复杂,对新人不友好(例如,研发同学会将信息以json格式存储)。而随着业务线的增加,跨表引用增多,如果逻辑口径发生变化,势必会成为一个灾难。所以,中间表的作用,就是在dws层,将基础事实层的数据,通过与产品人员既定的规则编写,用”case when”或syscode系统码表来将业务口径标签化,将数据固定在对应主题域中,方便日常的汇报或者用户分析使用。那么如何来构建有价值的中间表呢,下面看两个例子,一个是供给端,一个是消耗端:
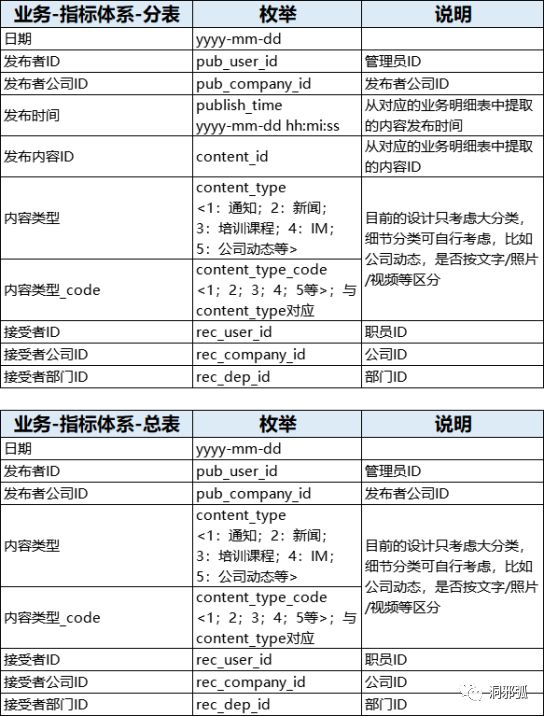
某App为办公协同类产品,内部附有公司动态、通知、新闻、培训课程、留言等功能,管理员或领导层可使用这些功能,下发一些公司内部的信息,分为全公司可见或者指定部门可见。如果该App的运营部,想查看某一功能的使用情况,所需要的数据为:形成了一个从供给到消耗的转化漏斗,来观测某功能带来了多少活跃,判定此项功能的使用情况。该转化漏斗的难点在于供给人数,可能是发给全公司的,也可能是发给个人的,同时涵盖了上述举例的多种功能。业务明细表会记录该功能的发布者ID、内容ID,发送对象ID,发送类型(公司、部门、个人)等。这时取数的麻烦点在于,发送类型如果为全公司,那么业务明细表关联用户明细表时,发送对象ID(公司ID)与公司ID关联;发送类型为部门时,发送对象ID(部门ID)与部门ID关联;发送类型为个人时,发送对象ID即是用户ID。用union all 将数据合并,得出了供给人数。这种数据提取,单次可行,代码也可复用,但是每次提取花费较大,也比较耗时间,数据都是存储在逻辑里,并没有一张表来记录。OK,那我们就创建一张中间表,将所有功能数据存储,对于有关需求可以随取随用。1. 考虑供给用户正常情况下(工作日),数据量较大,所以设计报表时,考虑为每一个业务进行单独建表,后续只考虑总供给的话,可对分表进行处理,去掉内容ID等,进行合并去重。2. 本表记录数据较多,所以内容ID对应的其他信息不做记录,如有需要,与对应业务表连接即可。
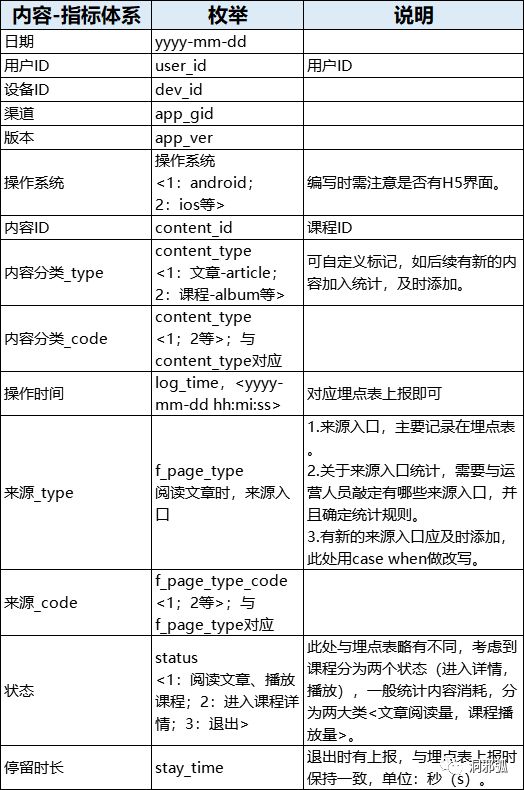
某App为内容资讯类产品,用户可在其查看各种文章和音视频,浏览入口分为推荐feed流,banner焦点图,关注频道,收藏,消息公众号推送等。运营人员除了关注整体的文章阅读外,还会关注各个入口的转化情况,数据如下:以上数据,除日活外,都属于用户的行为数据,用埋点表即可提取,关键在于埋点的数据每天是以亿级产生。以上数据当然可以做成BI报表,但是数据依然只是存在于逻辑中,每次需要,每次重新跑,没有复用性,消耗时效和人效,依然可以用中间表解决这个问题。与产品/运营人员,开会商议,确定每个来源入口的规则,对埋点表进行处理,用case when使不同的来源入口标签化:这样,一张只记录用户关于内容的消耗表就做好了,需要注意以下几点:1.本表旨在记录用户对内容的消耗,方便数据人员快速解决运营人员的需求,也可做RFM等分析。目前只记录观看和播放,是否应记录互动(点赞、评论、分享等),需要商议。2.除课程、文章外,是否有必要添加其他类型内容等。3.由于每天对内容的消耗用户量较多,所以内容的相关信息本表不做存储,如有需要,与内容的事实表进行连接。
通过建立中间表,确实可以提高数据的输出效率,但是光建立是远远不够的,后期的维护也同样重要。由于规则是与产品/运营商定的,必须形成规范的数据字典文档,存储在公共平台上(wiki、SVN等),有改动或者新增,需及时调整。有新增的业务时,也要在发版之后,添加至中间表中,避免数据遗漏或者重跑。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报