
写时复制(Copy-On-Write)在Java中是如何被应用的吗?
前言
写时复制(Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。
其核心思想是,如果有多个调用者同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这个过程对其他的调用者是透明的(transparently)。
此作法的主要优点是如果调用者没有修改该资源,就不会有副本(private copy)被建立,因此多个调用者只是读取操作时可以共享同一份资源。

COW(奶牛)技术的应用场景很多,Linux通过Copy On Write技术极大地减少了Fork的开销。文件系统通过Copy On Write技术一定程度上保证数据的完整性。数据库服务器也一般采用了写时复制策略,为用户提供一份snapshot。
而JDK的CopyOnWriteArrayList/CopyOnWriteArraySet容器也采用了 COW思想,它是如何工作的是本文讨论的重点。
Vector和synchronizedList
我们知道ArrayList是线程不安全的,而Vector是线程安全的容器。查看源码可以知道,Vector之所以线程安全,是因为它几乎在每个方法声明处都加了synchronized关键字来使整体方法原子化。
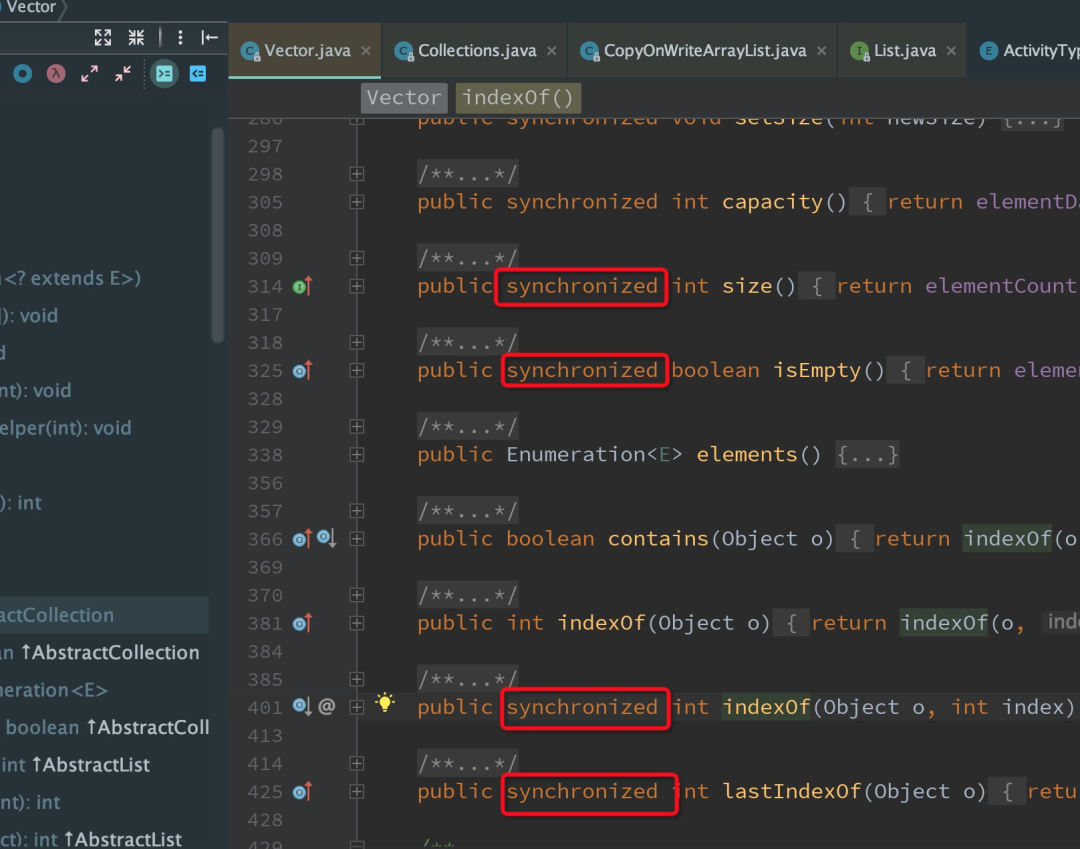
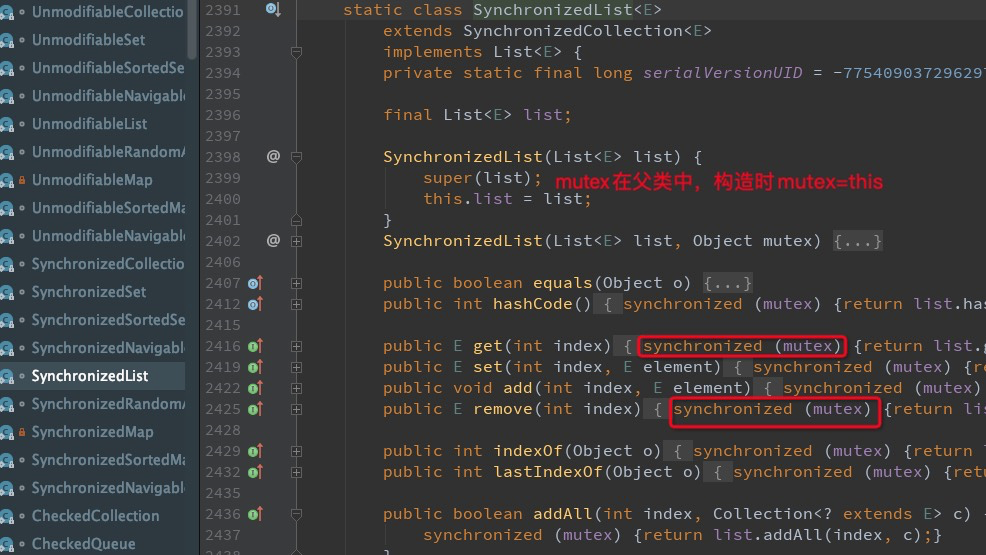
另外,使用Collections.synchronizedList(new ArrayList())修饰后,新建出来的ArrayList也是安全的,它是如何实现的呢?查看源码发现,它也是几乎在每个方法都加上synchronized关键字使方法原子化,只不过它不是把synchronized加在方法的声明处,而是加在方法的内部。
容器是线程安全的,并不意味着就可以在多线程环境下放心大胆地随便用了,来看下面这段使用Vector的代码。
@Test
public void testVectorConcurrentReadWrite() {
Vector<Integer> vector = new Vector<>();
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
vector.add(5);
for (Integer item : vector) {
new Thread(vector::clear).start();
System.out.println(item);
}
}
运行结果如下:
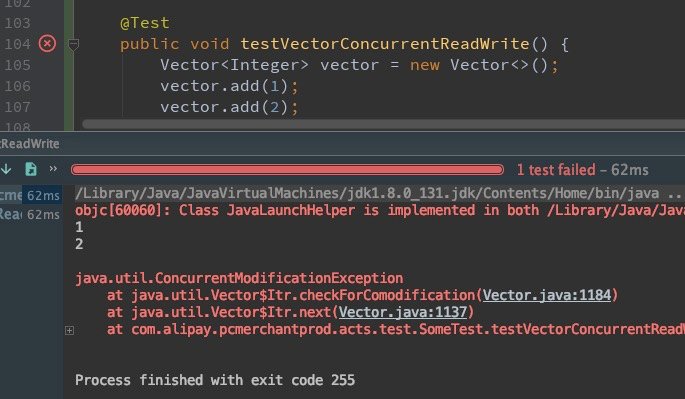
在一个线程中使用Iterator迭代器遍历vector,同时另一个线程对vector作修改时,会抛出java.util.ConcurrentModificationException异常。很多人不理解,因为Vector的所有方法都加了synchronized关键字来修饰,包括迭代器方法,理论上应该是线程安全的呀。
public synchronized Iterator<E> iterator() {
//Itr是AbstractList的私有内部类
return new Itr();
}
看以上错误的堆栈指向java.util.Vector$Itr.checkForComodification(Vector.java:1184),源码如下:
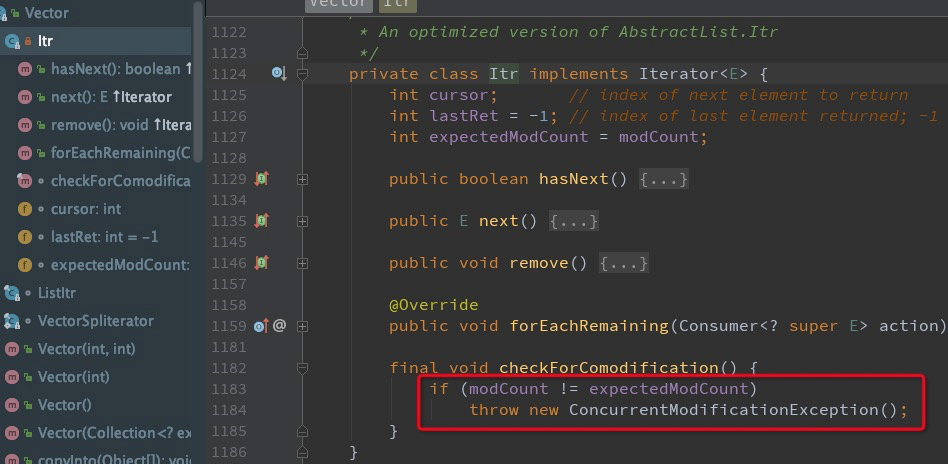
两个关键变量:
expectedModCount:表示对List修改次数的期望值,它的初始值与modCount相等 modCount:表示List集合结构被修改次数,是AbstractList类中的一个成员变量,初始值为0
看过ArrayList的源码就知道,每次调用add()和remove()方法时就会对modCount进行加1操作。而我们上面的测试代码中调用了Vector类的clear()方法,这个方法中对modCount进行了加1,而迭代器中的expectedModCount依然等于0,两者不等,因此抛了异常。这就是集合中的fail-fast机制,fail-fast 机制用来防止在对集合进行遍历过程当中,出现意料之外的修改,会通过Unchecked异常暴力的反应出来。
虽然Vector的方法都采用了synchronized进行了同步,但是实际上通过Iterator访问的情况下,每个线程里面返回的是不同的iterator,也即是说expectedModCount变量是每个线程私有。如果此时有2个线程,线程1在进行遍历,线程2在进行修改,那么很有可能导致线程2修改后导致Vector中的modCount自增了,线程2的expectedModCount也自增了,但是线程1的expectedModCount没有自增,此时线程1遍历时就会出现expectedModCount不等于modCount的情况了。
同样地,SynchronizedList在使用迭代器遍历的时候同样会有问题的,源码中的注释已经提醒我们要手动加锁了。
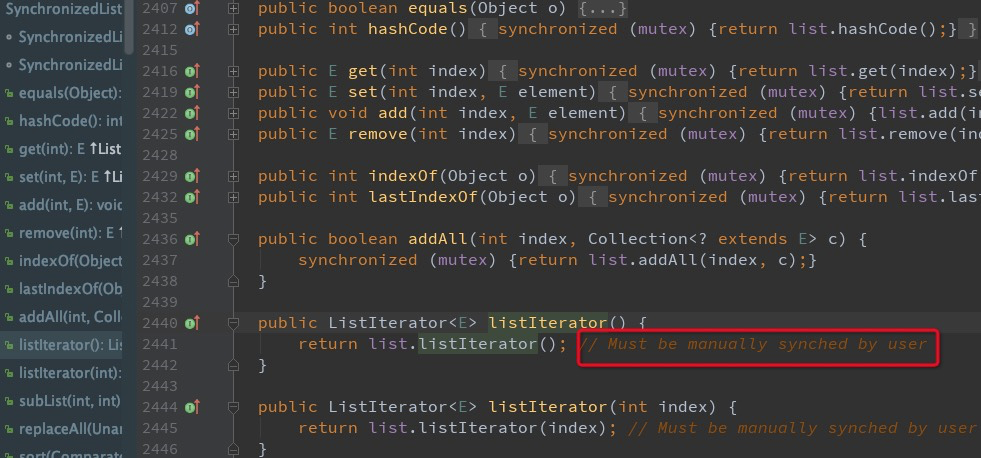
foreach循环里不能调用集合的remove/add/clear方法这一条规约不仅对非线程安全的ArrayList/LinkedList适用,对于线程安全的Vector以及synchronizedList也同样适用。
因此,要想解决以上问题,只能在遍历前(无论用不用iterator)加锁。
synchronized (vector) {
for (int i = 0; i < vector.size(); i++) {
System.out.println(vector.get(i));
}
//或者
synchronized (vector) {
for (Integer item : vector) {
System.out.println(item);
}
仅仅是遍历一下容器都要上锁,性能必然不好。
其实并非只有遍历前加锁这一种解决方法,使用并发容器CopyOnWriteArrayList也能避免以上问题。往期面试题汇总:250期面试资料
CopyOnWriteArrayList介绍
一般来说,我们会认为:CopyOnWriteArrayList是同步List的替代品,CopyOnWriteArraySet是同步Set的替代品。
无论是Hashtable–>ConcurrentHashMap,还是说Vector–>CopyOnWriteArrayList。JUC下支持并发的容器与老一代的线程安全类相比,总结起来就是加锁粒度的问题。
Hashtable与Vector加锁的粒度大,直接在方法声明处使用synchronized ConcurrentHashMap、CopyOnWriteArrayList的加锁粒度小。用各种方式来实现线程安全,比如我们知道的ConcurrentHashMap用了CAS、+ volatile等方式来实现线程安全 JUC下的线程安全容器在遍历的时候不会抛出ConcurrentModificationException异常
所以一般来说,我们都会使用JUC包下给我们提供的线程安全容器,而不是使用老一代的线程安全容器。
下面我们来看看CopyOnWriteArrayList是怎么实现的,为什么使用迭代器遍历的时候就不用额外加锁,也不会抛出ConcurrentModificationException异常。
实现原理
Copy-on-write是解决并发的的一种思路,指的是实行读写分离,如果执行的是写操作,则复制一个新集合,在新集合内添加或者删除元素。待一切修改完成之后,再将原集合的引用指向新的集合。
这样的好处就是,可以高并发地对COW进行读和遍历操作,而不需要加锁,因为当前集合不会添加任何元素。
写时复制(copy-on-write)的这种思想,这种机制,并不是始于Java集合之中,在Linux、Redis、文件系统中都有相应思想的设计,是一种计算机程序设计领域的优化策略。
CopyOnWriteArrayList的核心理念就是读写分离,写操作在一个复制的数组上进行,读操作还是在原始数组上进行,读写分离,互不影响。写操作需要加锁,防止并发写入时导致数据丢失。写操作结束之后需要让数组指针指向新的复制数组。
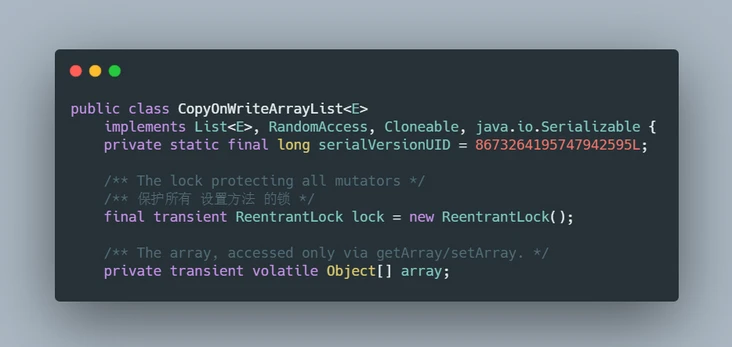
看一下CopyOnWriteArrayList基本的结构。
看一下其读写的源码,写操作加锁,防止并发写入时导致数据丢失,并复制一个新数组,增加操作在新数组上完成,将array指向到新数组中,最后解锁。至于读操作,则是直接读取array数组中的元素。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
遍历 - COWIterator
到现在,还是没有解释为什么CopyOnWriteArrayList在遍历时,对其进行修改而不抛出异常。
不管是foreach循环还是直接写Iterator来遍历,实际上都是使用Iterator遍历。那么就直接来看下CopyOnWriteArrayList的iterator()方法。
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
来看一下迭代器COWIterator的实现源码。
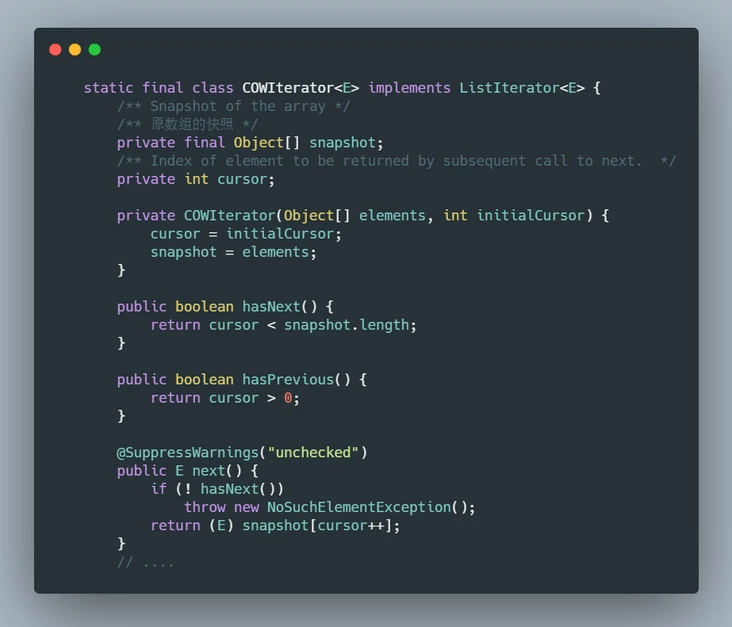
可以发现的是,迭代器所有的操作都基于snapshot数组,而snapshot是传递进来的array数组。
也就是说在使用COWIterator进行遍历的时候,如果修改了集合,集合内部的array就指向了新的一个数组对象,而COWIterator内部的那个snapshot还是指向初始化时传进来的旧数组,所以不会抛异常,因为旧数组永远没变过,旧数组读操作永远可靠且安全。往期面试题汇总:250期面试资料
CopyOnWriteArrayList与synchronizedList性能测试
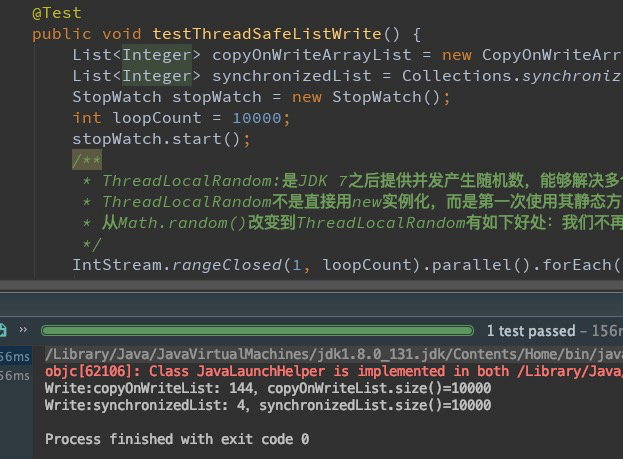
写单元测试来对CopyOnWriteArrayList与synchronizedList的并发写性能作测试,由于CopyOnWriteArrayList写时直接复制新数组,可以预想到其写操作性能不高,会劣于synchronizedList。
@Test
public void testThreadSafeListWrite() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount = 10000;
stopWatch.start();
/**
* ThreadLocalRandom:是JDK 7之后提供并发产生随机数,能够解决多个线程发生的竞争争夺。
* ThreadLocalRandom不是直接用new实例化,而是第一次使用其静态方法current()。
* 从Math.random()改变到ThreadLocalRandom有如下好处:我们不再有从多个线程访问同一个随机数生成器实例的争夺。
*/
IntStream.rangeClosed(1, loopCount).parallel().forEach(
item -> copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
System.out.println(
"Write:copyOnWriteList: " + stopWatch.getTime() + ",copyOnWriteList.size()=" + copyOnWriteArrayList
.size());
stopWatch.reset();
stopWatch.start();
/**
* parallelStream特点:基于服务器内核的限制,如果你是八核
* 每次线程只能起八个,不能自定义线程池
*/
IntStream.rangeClosed(1, loopCount).parallel().forEach(
item -> synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
System.out.println(
"Write:synchronizedList: " + stopWatch.getTime() + ",synchronizedList.size()=" + synchronizedList
.size());
}
运行结果如下,可以看到同样条件下的写耗时,CopyOnWriteArrayList是synchronizedList的30多倍。
同样地,写单元测试来对CopyOnWriteArrayList与synchronizedList的并发读性能作测试,由于CopyOnWriteArrayList读操作不加锁,可以预想到其读操作性能明显会优于synchronizedList。
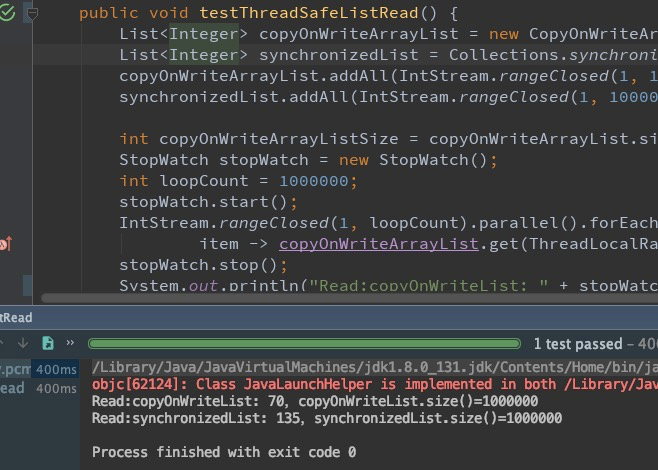
@Test
public void testThreadSafeListRead() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
copyOnWriteArrayList.addAll(IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
synchronizedList.addAll(IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
int copyOnWriteArrayListSize = copyOnWriteArrayList.size();
StopWatch stopWatch = new StopWatch();
int loopCount = 1000000;
stopWatch.start();
/**
* ThreadLocalRandom:是JDK 7之后提供并发产生随机数,能够解决多个线程发生的竞争争夺。
* ThreadLocalRandom不是直接用new实例化,而是第一次使用其静态方法current()。
* 从Math.random()改变到ThreadLocalRandom有如下好处:我们不再有从多个线程访问同一个随机数生成器实例的争夺。
*/
IntStream.rangeClosed(1, loopCount).parallel().forEach(
item -> copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(copyOnWriteArrayListSize)));
stopWatch.stop();
System.out.println("Read:copyOnWriteList: " + stopWatch.getTime());
stopWatch.reset();
stopWatch.start();
int synchronizedListSize = synchronizedList.size();
/**
* parallelStream特点:基于服务器内核的限制,如果你是八核
* 每次线程只能起八个,不能自定义线程池
*/
IntStream.rangeClosed(1, loopCount).parallel().forEach(
item -> synchronizedList.get(ThreadLocalRandom.current().nextInt(synchronizedListSize)));
stopWatch.stop();
System.out.println("Read:synchronizedList: " + stopWatch.getTime());
}
运行结果如下,同等条件下的读耗时,CopyOnWriteArrayList只有synchronizedList的一半。
CopyOnWriteArrayList优缺点总结
优点:
对于一些读多写少的数据,写入时复制的做法就很不错,例如配置、黑名单、物流地址等变化非常少的数据,这是一种无锁的实现。可以帮我们实现程序更高的并发。 CopyOnWriteArrayList并发安全且性能比Vector好。Vector是增删改查方法都加了synchronized 来保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector。
缺点:
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。比如线程A在迭代CopyOnWriteArrayList容器的数据。线程B在线程A迭代的间隙中将CopyOnWriteArrayList部分的数据修改了,但是线程A迭代出来的是旧数据。 内存占用问题。如果CopyOnWriteArrayList经常要增删改里面的数据,并且对象比较大,频繁地写会消耗内存,从而引发Java的GC问题,这个时候,我们应该考虑其他的容器,例如ConcurrentHashMap。
感谢阅读,希望对你有所帮助 :)
来源:blog.csdn.net/fuzhongmin05/article/details/117076906
最近给大家找了 Vue进阶
资源,怎么领取?
扫二维码,加我微信,回复:Vue进阶
注意,不要乱回复 没错,不是机器人 记得一定要等待,等待才有好东西