
如何评价一个开源项目?是它了
本文由X-lab开放实验室博士生赵生宇创作
也希望可以有更多对社区度量感兴趣的朋友参与到讨论之中,本人的联系方式见关于页(http://blog.frankzhao.cn/about)

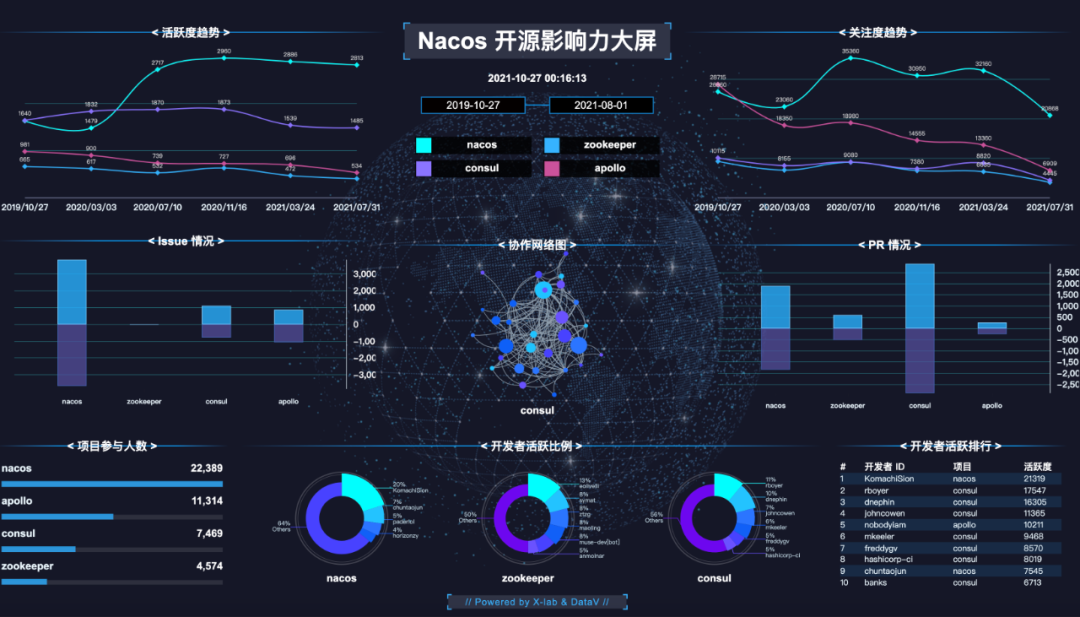
从开源办公室的角度而言,我们必须有一个“北极星”指标。对于一些开源创业公司或具体的开源项目团队而言,可以通过监控或观察多个指标来判断项目的健康与否。但对于有 2000 多个开源项目的企业而言,要同时监控这么多项目的健康度,就需要一个聚合的指标,否则人力成本过高。
由于 star、fork 等行为属于开发者的单向行为,虽然表示了对项目的一种关注,但并不对项目产生具体贡献,所以没有纳入到活跃度的计算之中,即刷 star 等行为在活跃度算法下无效。
即便当时默认的贡献者(contributor)的定义为代码贡献者,但从实际角度出发,参与到社区中的所有开发者,包括提交 bug、参与讨论、参与代码 review 的开发者事实上都对项目是有贡献的,所以在计算中并不是仅计入代码贡献,而是将讨论等也纳入。
对于五种事件对应的权重应该是多少,其实在这里是相当主观的,1 - 5 是一个非常简单粗暴的赋值方式,但事实上这个权重集是在阿里最重要的一些战略级开源项目的负责人共识下产生的,并且对 PR 的 review 给出了非常高的 4 分,也是鼓励大家多进行基于 GitHub 的异步 review。
从开发者活跃度到项目活跃度的计算,我们对每个开发者的活跃度进行了开方,这里所给出的价值观是:那些核心开发者非常活跃,但总体参与人数较少的社区,其活跃度不应高于核心开发者虽然不太活跃,但参与贡献人数更多的社区。本质上是对个体开发者活跃度进行了一个削减。
到底哪些数值需要被纳入,例如 star、fork 是否应该被纳入,是不太确定的。尤其是在活跃度这样一个概念下,那些对项目没有带来实际反馈的行为是否要纳入进来极为微妙。
不同行为的权重是人为指定的,虽然包含了一定的专家经验,但这些数值的大小其实是还是具有相当的主观性,尤其是在项目之间比较时,权重的微小差别就会带来一些总体活跃度的波动。
这种活跃度计算方式缺乏基线。由于这里的活跃度是对一段时间内的行为次数的统计,所以时间段不同,则活跃度不同,时间段越长,活跃度越高。因此在不同时间段上无法进行直观的比较,这种缺乏基线的计算方式对于给出活跃度的参考阈值是不友好的。
这种活跃度计算方式在仓库层面不具有线性可加性。为了引入贡献者数量的因素,在仓库活跃度求和时对开发者活跃度开方,这个非线性操作导致了仓库活跃度在时间区间不能线性可加,这对多时间段的运算造成了比较大的影响,使得一些中间结果无法被复用。
个人活跃度到仓库活跃度的开方操作本身也是一个人为的经验做法,本质上就是想引入一个一阶导数单调递增,二阶导单调递减的函数来进行修正,模拟一种边际效益递减效应。显然不仅是开方,对数函数也满足这种性质,而且对数函数在此类计算中非常常用,而我当时选用开方是考虑了计算效率问题,因为开方运算在很多语言下都比对数运算要更快。
只要是简单的统计指标来进行计算,就一定无法避免刷指标的行为。事实上,当我们在阿里内部开始推行这个指标体系时,有部分开发者的活跃度有了一个跳变。原因其实是原先这个项目的负责人不知道如何在 GitHub 进行 review,在看到这个指标体系之前都是在即时通讯工具中进行同步聊天的 review,但在我们的推广和教育后,对过去的一些代码 review 进行了集中的补充。这也是我们认为好的指标体系可以起到的作用,即便是刷指标,但我们认为该指标是起到了正向的引导作用。而且之后也没有发现有其他项目通过刻意增加回复数量、拆分 PR 等方式恶意刷活跃度的情况,毕竟开方操作本身使得个别账号的这种刷分行为对整体仓库的影响是有限的。因此在这个指标下的刷分行为目前来看是起到了预期的价值导向作用。
逆锋起笔是一个专注于程序员圈子的技术平台,你可以收获最新技术动态、最新内测资格、BAT等大厂的经验、精品学习资料、职业路线、副业思维,微信搜索逆锋起笔关注!
 觉得不错,请点个在看呀
觉得不错,请点个在看呀