
23张图,带你入门推荐系统 ~
近期,我打算系统性地学习下广告中的搜索和推荐算法,当然更多是从工程的视角去弄清楚:算法的基本原理、以及面对线上海量数据时算法是如何解决性能问题的?整个过程,我会将有价值的技术点输出成系列文章。

01 走进推荐系统的世界

1. 推荐系统到底解决的是什么问题?
推荐系统从20世纪90年代就被提出来了,但是真正进入大众视野以及在各大互联网公司中流行起来,还是最近几年的事情。
随着移动互联网的发展,越来越多的信息开始在互联网上传播,产生了严重的信息过载。因此,如何从众多信息中找到用户感兴趣的信息,这个便是推荐系统的价值。精准推荐解决了用户痛点,提升了用户体验,最终便能留住用户。
推荐系统本质上就是一个信息过滤系统,通常分为:召回、排序、重排序这3个环节,每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户。

推荐系统的分阶段过滤流程
哪里有海量信息,哪里就有推荐系统,我们每天最常用的APP都涉及到推荐功能:
资讯类:今日头条、腾讯新闻等 电商类:淘宝、京东、拼多多、亚马逊等 娱乐类:抖音、快手、爱奇艺等 生活服务类:美团、大众点评、携程等 社交类:微信、陌陌、脉脉等
头条、京东、网易云音乐中的推荐功能
推荐系统的应用场景通常分为以下两类:
基于用户维度的推荐:根据用户的历史行为和兴趣进行推荐,比如淘宝首页的猜你喜欢、抖音的首页推荐等。 基于物品维度的推荐:根据用户当前浏览的标的物进行推荐,比如打开京东APP的商品详情页,会推荐和主商品相关的商品给你。
搜索和推荐是AI算法最常见的两个应用场景,在技术上有相通的地方。这里提到广告,主要考虑很多没做过广告业务的同学不清楚为什么广告和搜索、推荐会有关系,所以做下解释。
搜索:有明确的搜索意图,搜索出来的结果和用户的搜索词相关。 推荐:不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐。
广告:借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等。
02 推荐系统的整体架构
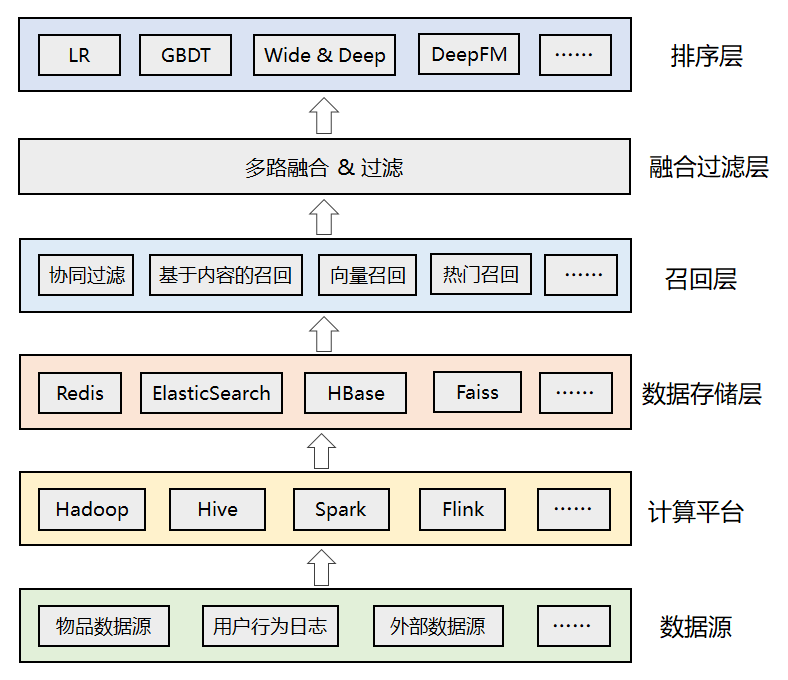
推荐系统的整体架构
数据源:推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据。 计算平台:负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算。
数据存储层:存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的embedding向量等。
召回层:包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中。
融合过滤层:触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤。
排序层:利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。

推荐引擎的核心功能和技术方案
03 图解经典的协同过滤算法
1. 协同过滤是什么?
协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合。它又包括两个分支:
基于用户的协同过滤:User-CF,核心是找相似的人。比如下图中,用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。这样,就可以将用户 A 购买过的物品 d 推荐给用户 C。
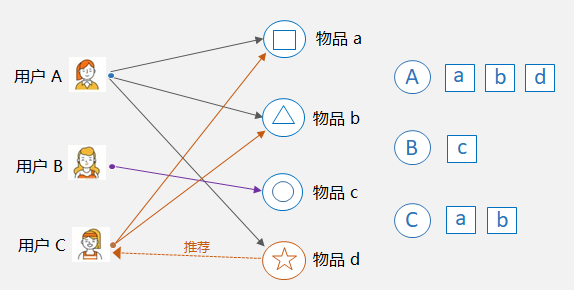
基于用户的协同过滤示例
基于物品的协同过滤:Item-CF,核心是找相似的物品。比如下图中,物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品 a 和 物品 b 被认为是相似的,因为它们的共现次数很高。这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
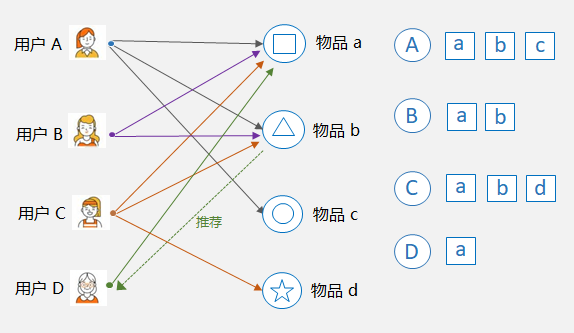
前面讲到,协同过滤的核心就是找相似,User-CF是找用户之间的相似,Item-CF是找物品之间的相似,那到底如何衡量两个用户或者物品之间的相似性呢?
我们都知道,对于坐标中的两个点,如果它们之间的夹角越小,这两个点越相似,这就是初中学过的余弦距离,它的计算公式如下:

举个例子,A坐标是(0,3,1),B坐标是(4,3,0),那么这两个点的余弦距离是0.569,余弦距离越接近1,表示它们越相似。

清楚了相似性的定义后,下面以Item-CF为例,详细说下这个算法到底是如何选出推荐物品的?
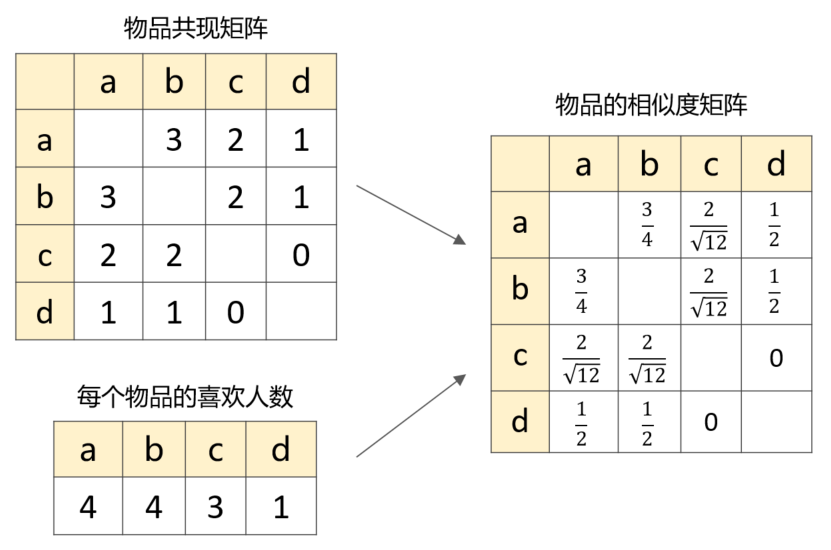
第一步:整理物品的共现矩阵

第二步:计算物品的相似度矩阵
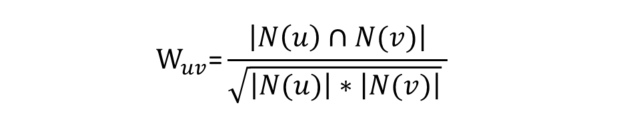
基于第1步计算出来的共现矩阵以及每个物品的喜欢人数,便可以构造出物品的相似度矩阵:

上面的公式有点抽象,直接看例子更容易理解,假设我要给用户 E 推荐物品,前面我们已经知道用户 E 喜欢物品 b 和物品 c,喜欢程度假设分别为 0.6 和 0.4。那么,利用上面的公式计算出来的推荐结果如下:

04 从0到1搭建一个推荐系统
1. 选择数据集
这里采用的是推荐领域非常经典的 MovieLens 数据集,它是一个关于电影评分的数据集,官网上提供了多个不同大小的版本,下面以 ml-1m 数据集(大约100万条用户评分记录)为例。
下载解压后,文件夹中包含:ratings.dat、movies.dat、users.dat 3个文件,共6040个用户,3900部电影,1000209条评分记录。各个文件的格式都是一样的,每行表示一条记录,字段之间采用 :: 进行分割。
程序主要使用数据集中的 ratings.dat 这个文件,通过解析该文件,抽取出 user_id、movie_id、rating 3个字段,最终构造出算法依赖的数据,并保存在变量 dataset 中,它的格式为:dict[user_id][movie_id] = rate

基于第 2 步的 dataset,可以进一步统计出每部电影的评分次数以及电影的共生矩阵,然后再生成相似度矩阵。
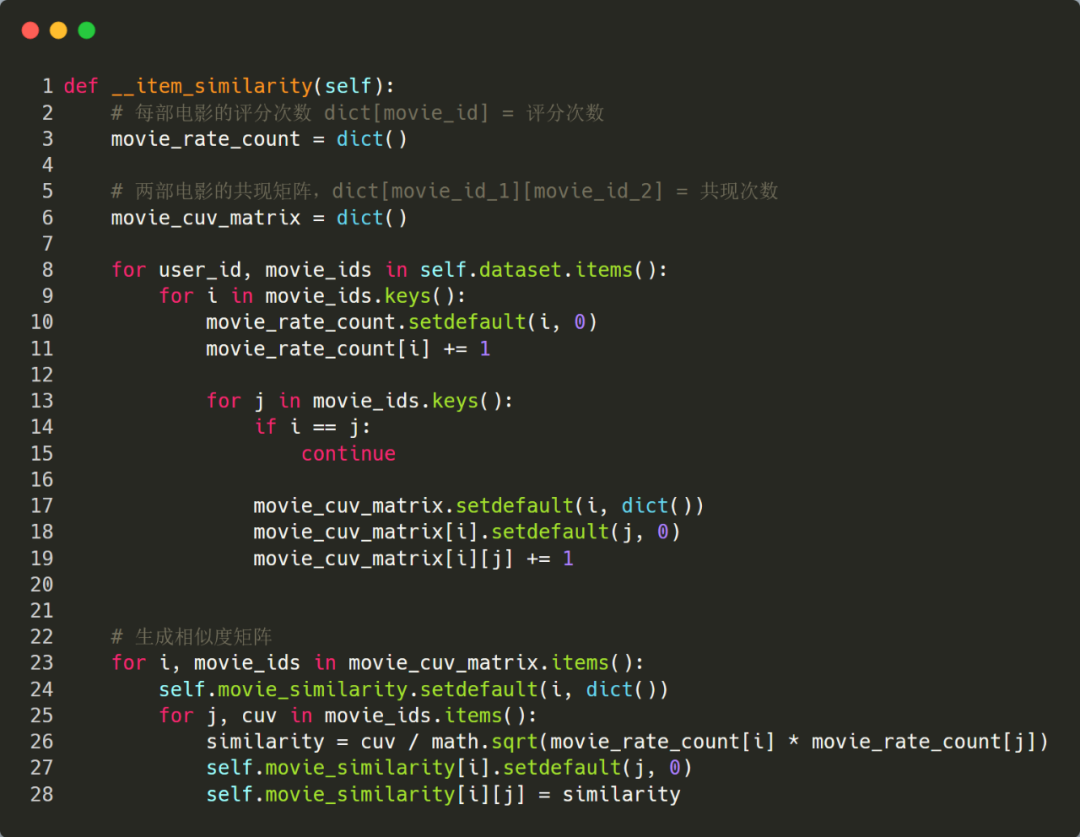
最后,可以基于相似度矩阵进行推荐了,输入一个用户id,先针对该用户评分过的电影,依次选出 top 10 最相似的电影,然后加权求和后计算出每个候选电影的最终评分,最后再选择得分前 5 的电影进行推荐。
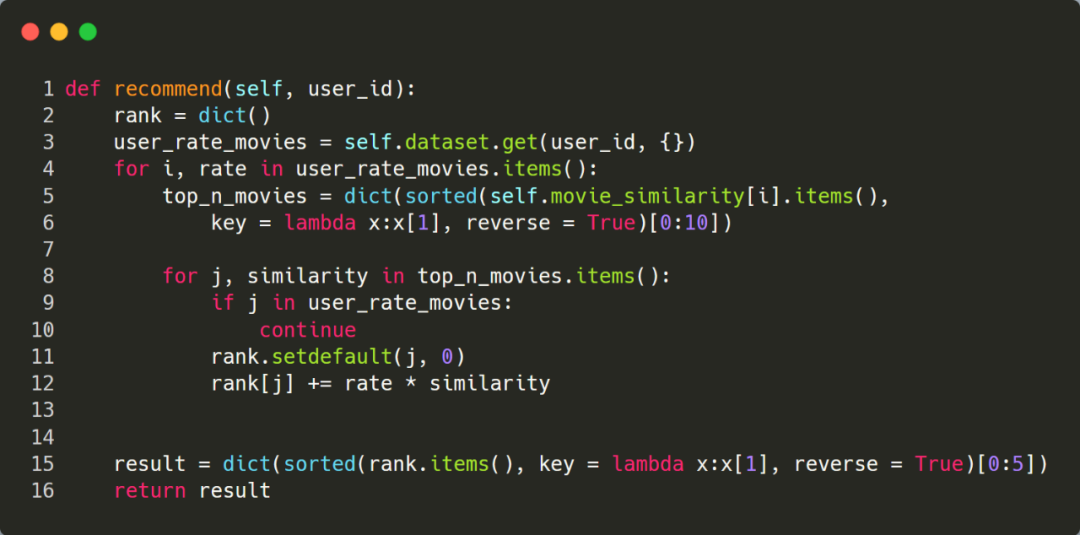
下面选择 UserId=1 这个用户,看下程序的执行结果。由于推荐程序输出的是 movieId 列表,为了更直观的了解推荐结果,这里转换成电影的标题进行输出。
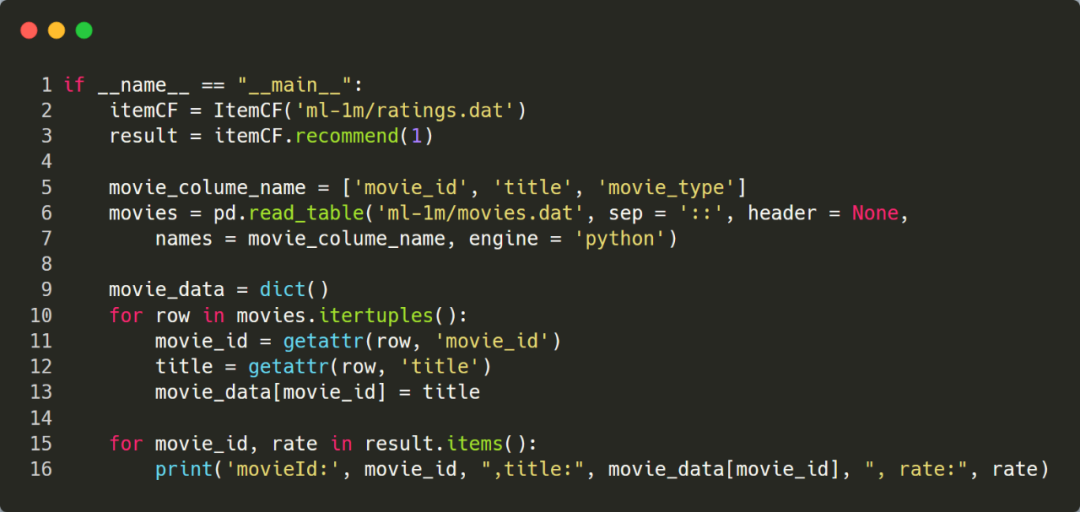
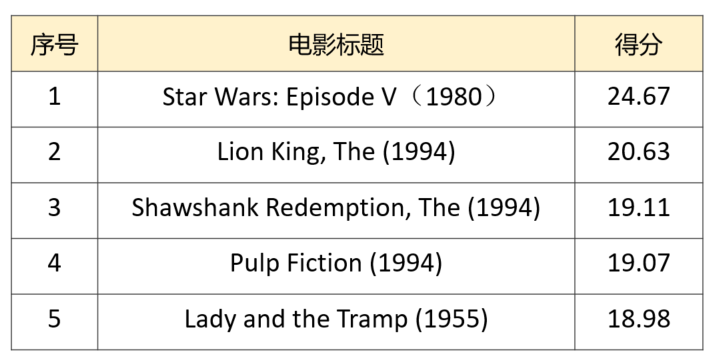
最终推荐的前5个电影为:
05 线上推荐系统的挑战
通过上面的介绍,大家对推荐系统的基本构成应该有了一个初步认识,但是真正运用到线上真实环境时,还会遇到很多算法和工程上的挑战,绝对不是几十行 Python 代码可以搞定的。
1、上面的示例使用了标准化的数据集,而线上环境的数据是非标准化的,因此涉及到海量数据的收集、清洗和加工,最终构造出模型可使用的数据集。
2、复杂且繁琐的特征工程,都说算法模型的上限由数据和特征决定。对于线上环境,需要从业务角度选择出可用的特征,然后对数据进行清洗、标准化、归一化、离散化,并通过实验效果进一步验证特征的有效性。
3、算法复杂度如何降低?比如上面介绍的Item-CF算法,时间和空间复杂度都是O(N×N),而线上环境的数据都是千万甚至上亿级别的,如果不做算法优化,可能几天都跑不出数据,或者内存中根本放不下如此大的矩阵数据。
4、实时性如何满足?因为用户的兴趣随着他们最新的行为在实时变化的,如果模型只是基于历史数据进行推荐,可能结果不够精准。因此,如何满足实时性要求,以及对于新加入的物品或者用户该如何推荐,都是要解决的问题。
5、算法效果和性能的权衡。从算法角度追求多样性和准确性,从工程角度追求性能,这两者之间必须找到一个平衡点。
6、推荐系统的稳定性和效果追踪。需要有一套完善的数据监控和应用监控体系,同时有 ABTest 平台进行灰度实验,进行效果对比。
写在最后
这篇文章是推荐系统的入门篇,目的是让大家对推荐系统先有一个整体的认识,后续我会再连载出一些文章,详细地介绍面对具体业务和线上海量数据时,推荐系统应该如何设计?
END
有热门推荐?
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
