
可视化方式,彻底搞懂LSTM
来自 | 知乎 作者 | master苏
链接 | https://zhuanlan.zhihu.com/p/139617364
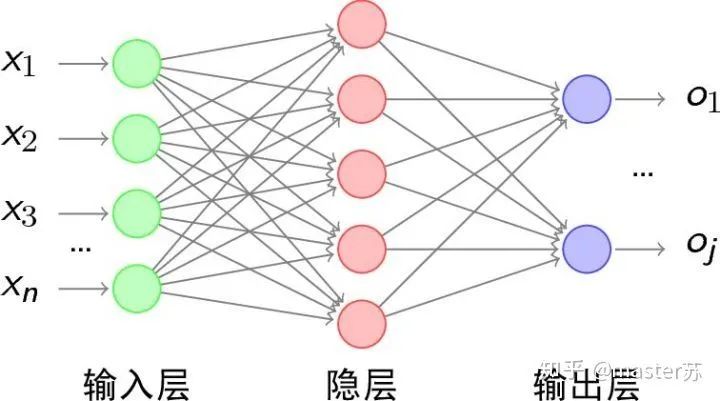
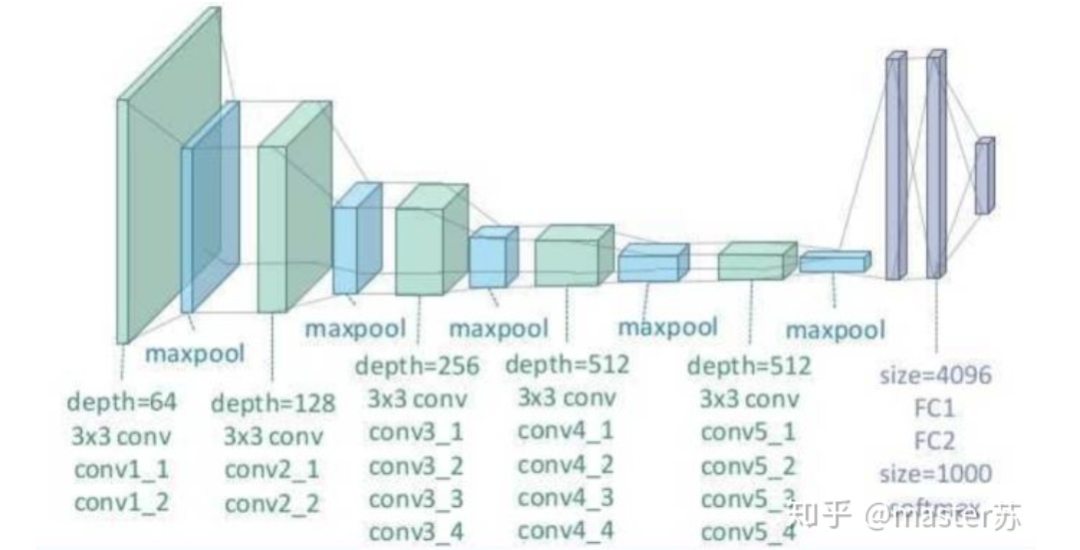
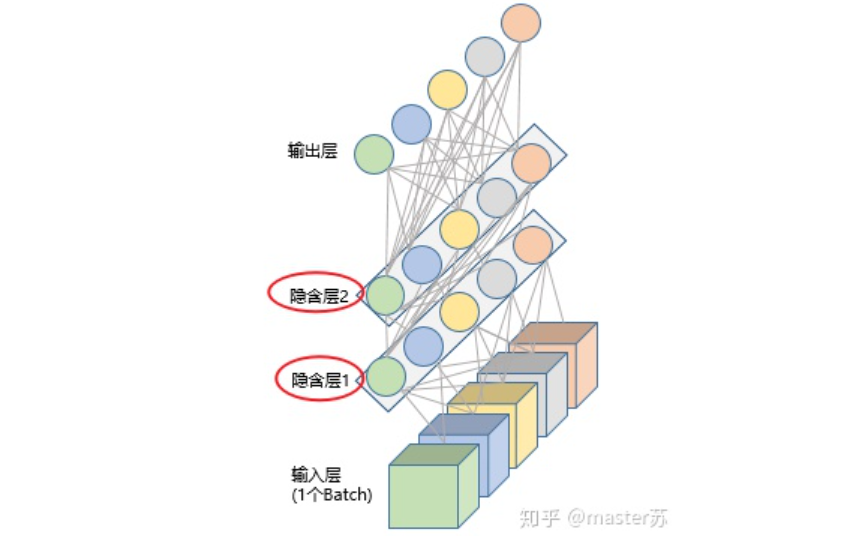
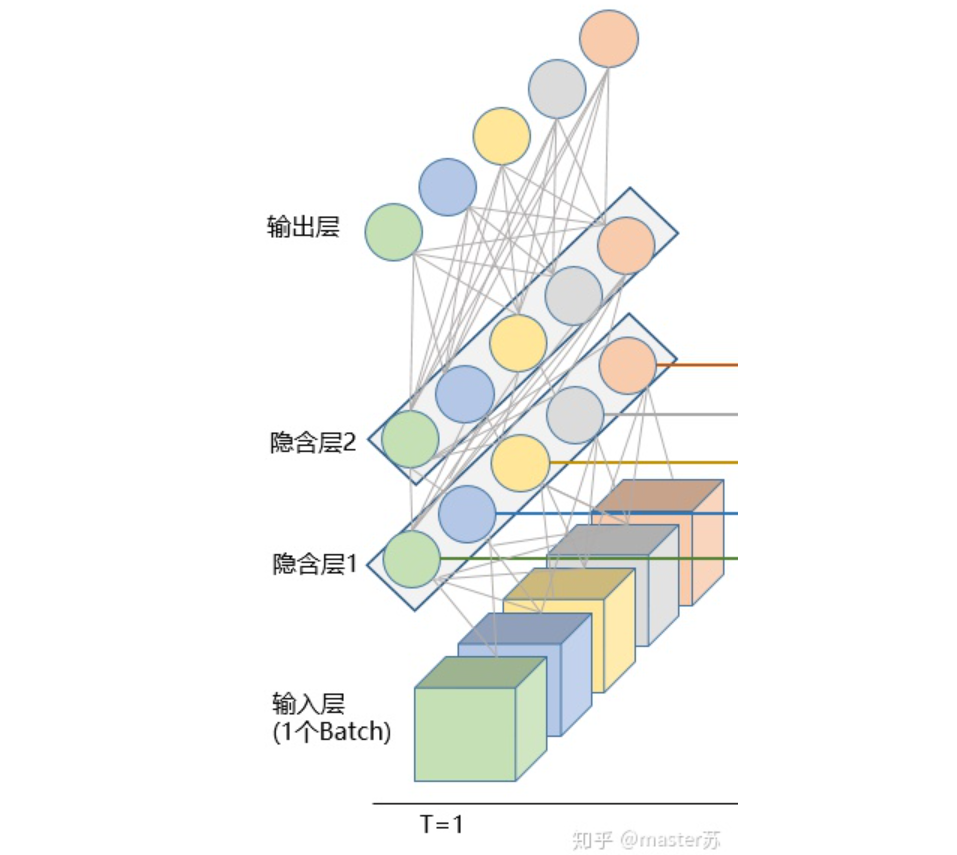
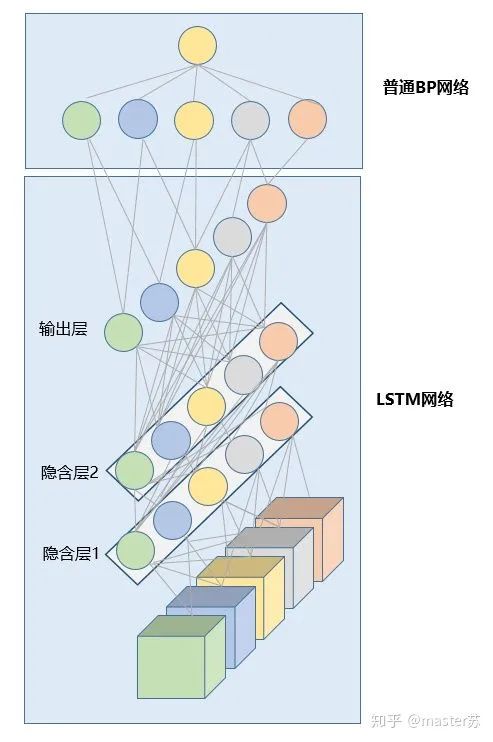
1、传统的BP网络和CNN网络
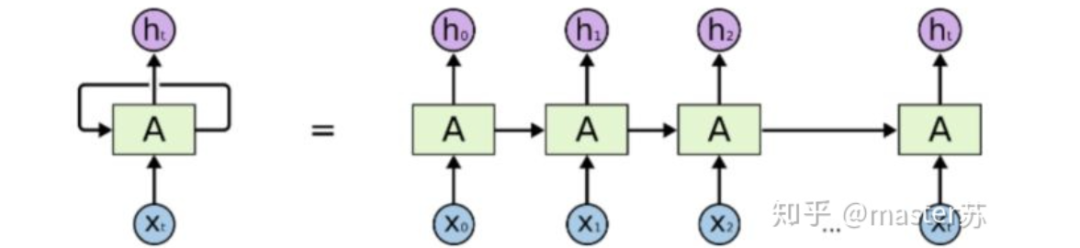
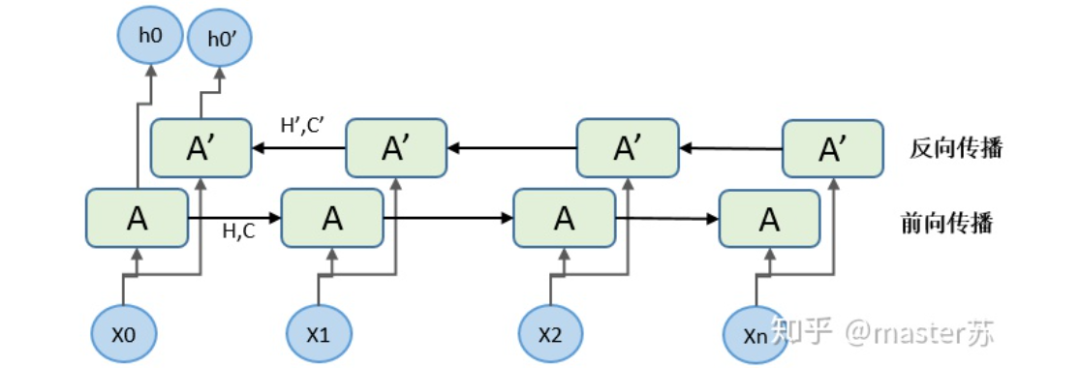
2、LSTM网络
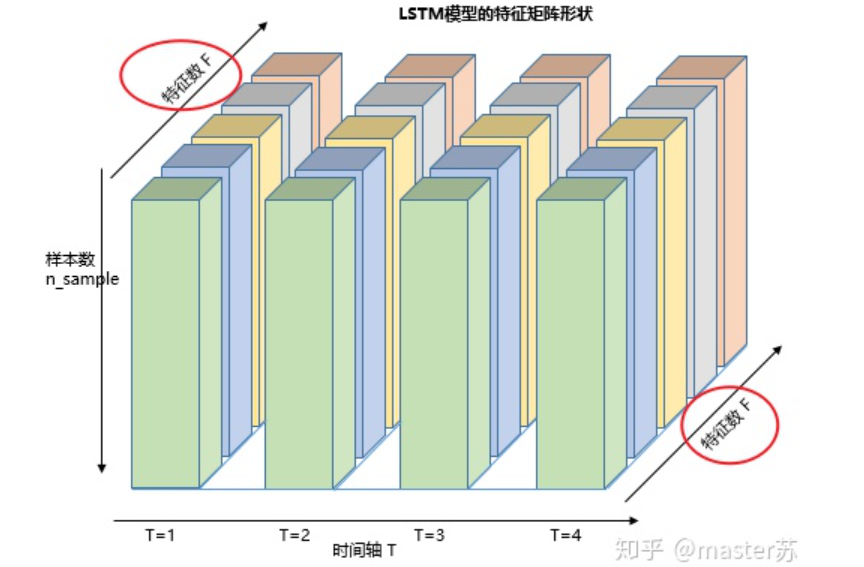
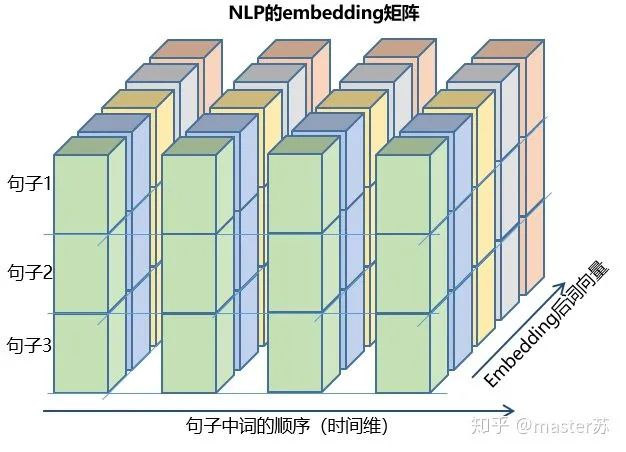
3、LSTM的输入结构
4、pytorch中的LSTM
4.1 pytorch中定义的LSTM模型
4.2 喂给LSTM的数据格式
4.3 LSTM的output格式
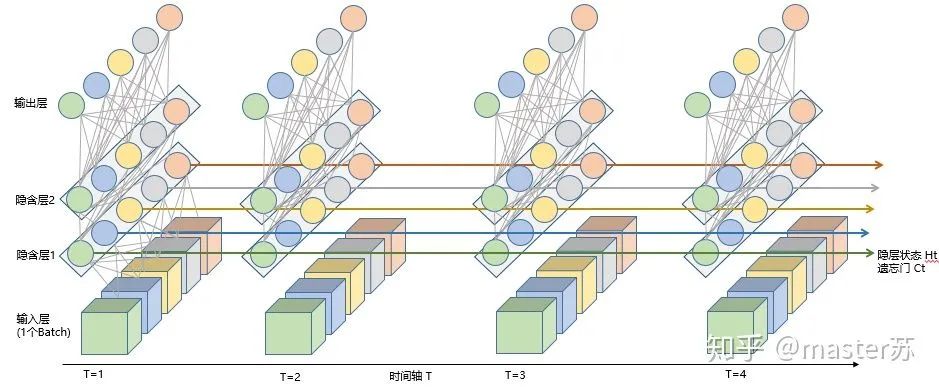
5、LSTM和其他网络组合
# 示例代码,没有实际意义model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷积层model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化层model.add(Dropout(0.25)) # 添加dropout层model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷积层model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化层model.add(Dropout(0.25)) # 添加dropout层.... # 添加其他卷积操作model.add(Flatten()) # 拉平三维数组为2维数组model.add(Dense(256, activation='relu')) 添加普通的全连接层model.add(Dropout(0.5))model.add(Dense(10, activation='softmax')).... # 训练网络
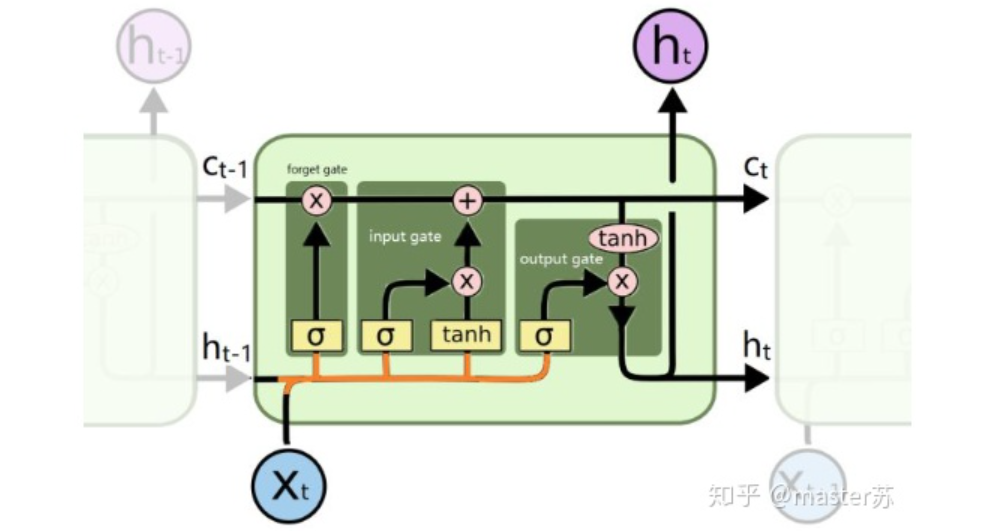
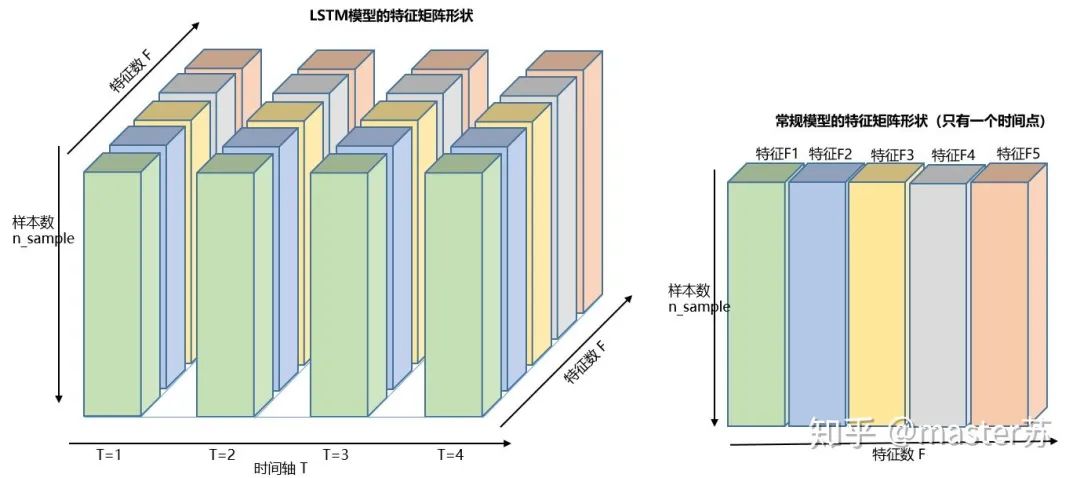
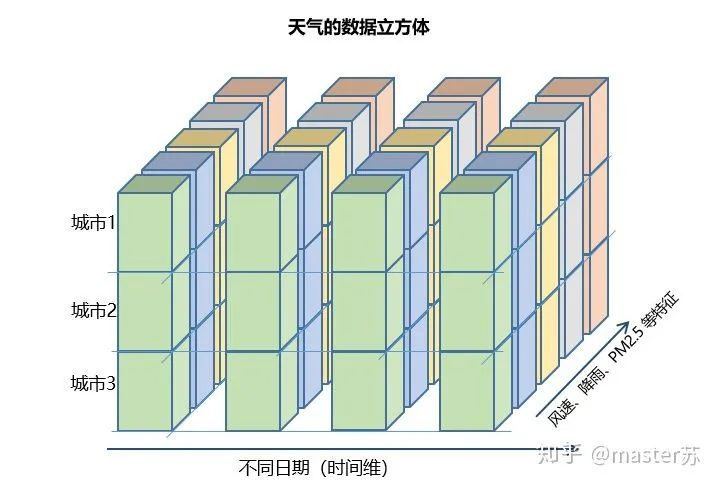
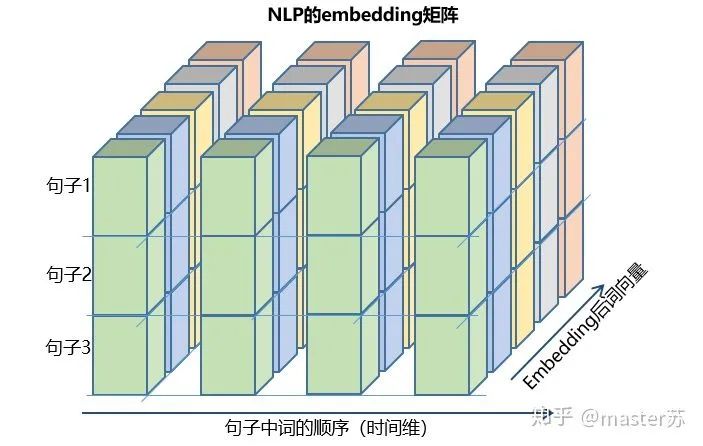
4.1 pytorch中定义的LSTM模型
class torch.nn.LSTM(*args, **kwargs)参数有:input_size:x的特征维度hidden_size:隐藏层的特征维度num_layers:lstm隐层的层数,默认为1bias:False则bihbih=0和bhhbhh=0. 默认为Truebatch_first:True则输入输出的数据格式为 (batch, seq, feature)dropout:除最后一层,每一层的输出都进行dropout,默认为: 0bidirectional:True则为双向lstm默认为False
4.2 喂给LSTM的数据格式
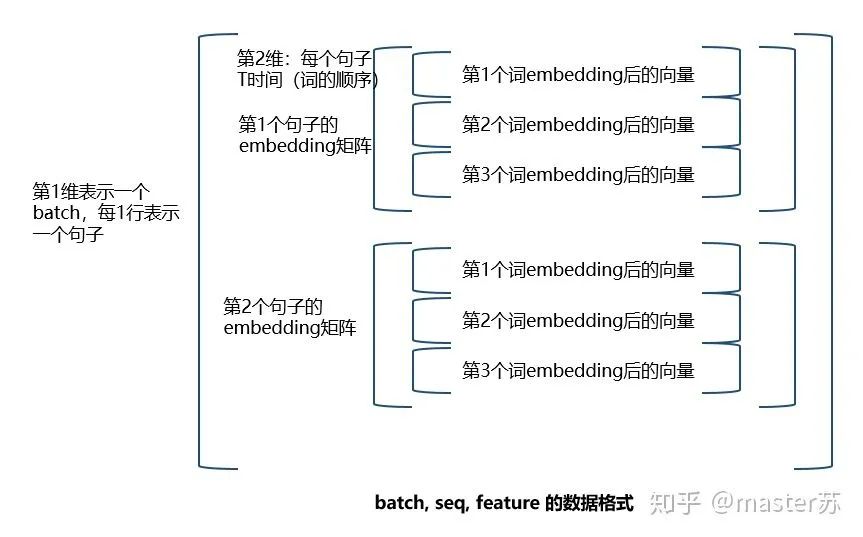
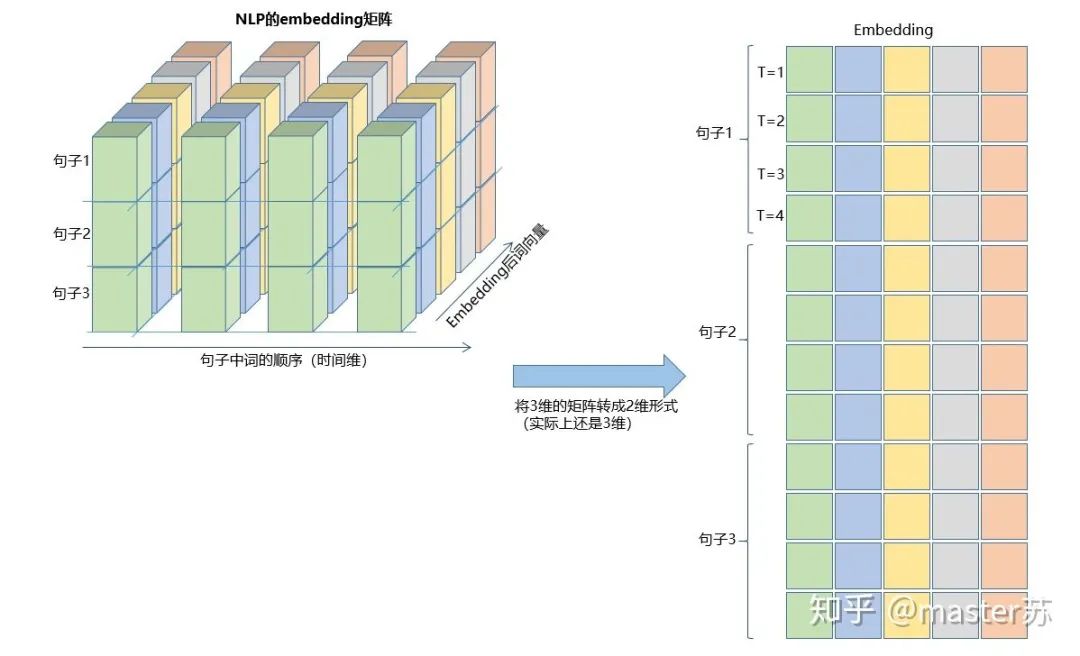
input(seq_len, batch, input_size)参数有:seq_len:序列长度,在NLP中就是句子长度,一般都会用pad_sequence补齐长度batch:每次喂给网络的数据条数,在NLP中就是一次喂给网络多少个句子input_size:特征维度,和前面定义网络结构的input_size一致。
input(batch, seq_len, input_size)
h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)参数:num_layers:隐藏层数num_directions:如果是单向循环网络,则num_directions=1,双向则num_directions=2batch:输入数据的batchhidden_size:隐藏层神经元个数
input(batch, seq_len, input_size)
h0(batc,num_layers * num_directions, h, hidden_size)c0(batc,num_layers * num_directions, h, hidden_size)
4.3 LSTM的output格式
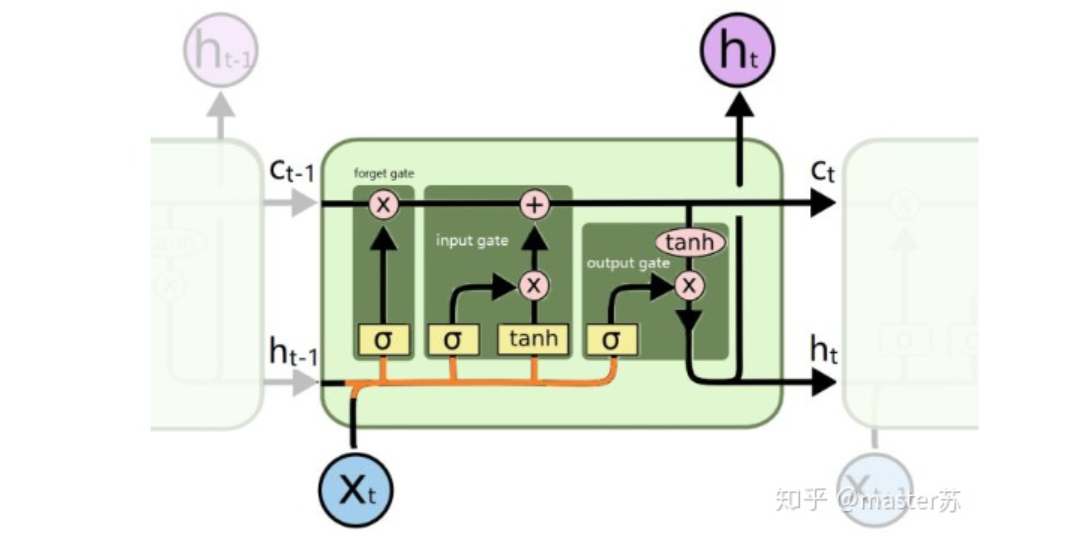
output,(ht, ct) = net(input)output: 最后一个状态的隐藏层的神经元输出ht:最后一个状态的隐含层的状态值ct:最后一个状态的隐含层的遗忘门值
output(seq_len, batch, hidden_size * num_directions)ht(num_layers * num_directions, batch, hidden_size)ct(num_layers * num_directions, batch, hidden_size)
input(batch, seq_len, input_size)
ht(batc,num_layers * num_directions, h, hidden_size)ct(batc,num_layers * num_directions, h, hidden_size)
import torchfrom torch import nnclass RegLSTM(nn.Module):def __init__(self):super(RegLSTM, self).__init__()# 定义LSTMself.rnn = nn.LSTM(input_size, hidden_size, hidden_num_layers)# 定义回归层网络,输入的特征维度等于LSTM的输出,输出维度为1self.reg = nn.Sequential(nn.Linear(hidden_size, 1))def forward(self, x):x, (ht,ct) = self.rnn(x)seq_len, batch_size, hidden_size= x.shapex = y.view(-1, hidden_size)x = self.reg(x)x = x.view(seq_len, batch_size, -1)return x
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论