
看图说话!MDETR:实现真正的端到端多模态推理|ICCV 2021 Oral
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
导读
本文提出了MDETR,一种端到端调制检测器,能够根据原始文本query直接来检测图像中的目标,基于Transformer的结构,通过在模型的早期阶段融合这两种模态的信息,来对文本和图像进行共同的推理。在检测和多个下游任务上都取得了SOTA的性能。
写在前面
目前,多模态推理模型大多都依赖于预先训练好的目标检测器来从图像中提取proposal。然而检测器只能检测出固定类别的目标,这使得模型很难适应自由文本中视觉concept的长尾分布,因此本文提出了MDETR,一种端到端调制检测器,能够根据原始文本query直接来检测图像中的目标,基于Transformer的结构,通过在模型的早期阶段融合这两种模态的信息,来对文本和图像进行共同的推理。最终,MDETR在检测和多个下游任务上都取得了SOTA的性能。
1. 论文和代码地址

论文地址:https://arxiv.org/abs/2104.12763
代码地址:https://github.com/ashkamath/mdetr
2. Motivation
在SOTA的多模态语义理解系统中,通常会采用目标检测网络从图像中提取proposal。
这样的处理方式会导致一些问题,比如不适用于一些下游任务、成为模型性能提升的瓶颈等等。除此之外,由于在模型的训练过程中,目标检测网络的参数通常是被固定的,这就会进一步影响模型的感知能力;另外,使用的检测网络提取的特征,也会导致模型只能访问到检测区域的信息,不能感知整张图片的信息。因此,在视觉-语言的跨模态任务中,这样的方式就会导致语言和视觉信息的交互限制在了语言信息和检测结果之间的交互,极大地影响了模型的性能上限。
因此,本文的作者基于DETR,提出了一个端到端的调制检测器MDETR,结合训练数据中的自然语言理解来执行目标检测任务,真正实现了端到端的多模态推理。在训练过程中,MDETR将文本和检测框的对齐作为一种监督信号。
不同于目前的目标检测网络,MDETR能够检测出自由形式文本中的concept,然后泛化到没见过的类别和属性的组合。(如下图所示,对于 “A pink elephant”,虽然MDETR在训练过程中没有见过粉色和蓝色的大象,但是依旧能够推理检测出正确颜色的大象。)

通过200,000张图片的预训练,MDETR基于Flickr30k数据集,在phrase grounding任务上SOTA;基于RefCOCO/+/g数据集,在REC任务上SOTA;基于Phrase Cut数据集 ,在RES任务上SOTA;基于GQA和CLEVR数据集,在VQA任务上也到了比较好的性能。
3. 方法
3.1. Background
本文提出的MDETR基于DETR[1]模型,DETR是一个由Backbone和Transformer Encoder-Decoder组成的端到端目标检测网络(DETR结构如下图所示)。
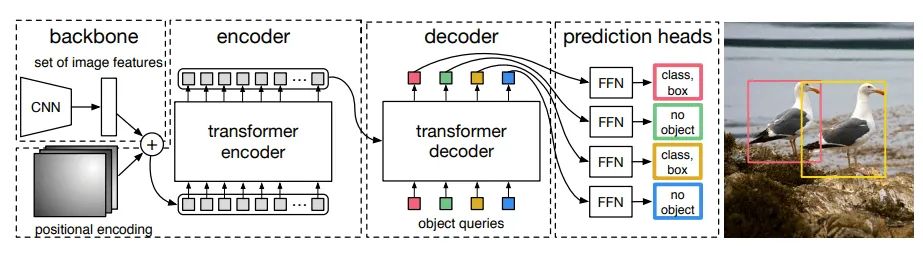
DETR首先将图片经过一个CNN backbone生成视觉特征,然后将这些视觉特征flatten之后,加上position encoding,送入到Transformer的Encoder中。Decoder的输入为N个可学习的embedding,原文中叫做object queries,这些queries可以被视为模型需要填充检测目标的插槽。
这些object queries送入到decoder之后,采用cross-attention层,与encoded的图像特征做信息交互,并预测每个query的输出embedding。
最后每个query的输出embedding通过一个参数共享的FFN来预测框的坐标和类别标签。
因为每个query负责预测一个框,所以预设的query数量是图像中object数量的上界。由于图像中的实际对象数量可能小于的query数量N,作者使用一个与“无对象”对应的额外类标签,由表示。
DETR在训练过程中采用了Hungarian matching loss,用来计算N和queries对应的object和ground-truth的二分匹配。每个匹配的对象都使用相应的目标作为ground truth进行监督,而不匹配的对象则用“无对象”标签进行监督。
分类的head用cross-entropy进行监督,bounding box的head用L1 Loss和广义IoU进行监督。
3.2. MDETR
3.2.1. Architecture
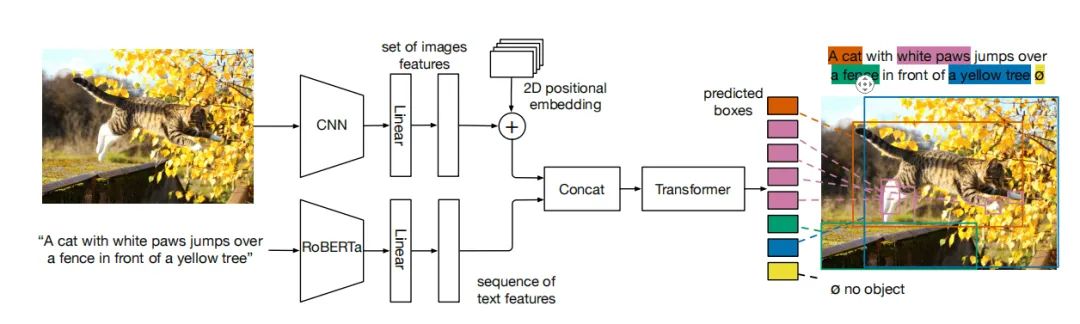
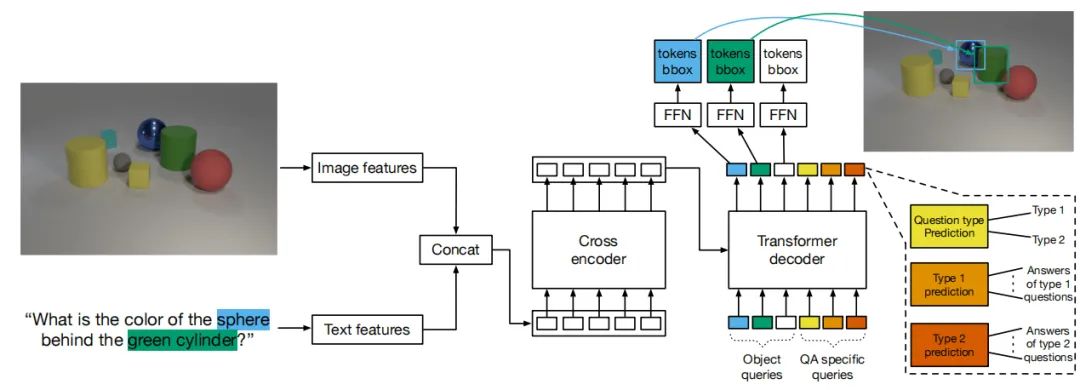
MDETR的结构如上图所示。
对于图像模型,MDETR采用的是一个CNN backbone来提取视觉特征,然后加上二维的位置编码;对于语言模态,作者采用了一个预训练好的Transformer语言模型来生成与输入值相同大小的hidden state。然后作者采用了一个模态相关的Linear Projection将图像和文本特征映射到一个共享的embedding空间。
接着,将图像embedding和语言embedding进行concat,生成一个样本的图像和文本特征序列。这个序列特征首先被送入到一个Cross Encoder进行处理,后面的步骤就和DETR一样,设置Object Query用于预测目标框。
3.2.2. Training
除了DETR的损失函数,作者提出了两个额外的loss用于图像和文本的对齐。第一个是soft token prediction loss,是一个无参数的对齐损失;第二个是text-query contrastive alignment loss,是一个有参数的损失函数,用于拉近对齐的query和token的相似度。
Soft token prediction
不同于传统的目标检测,modulated detection不是对每一个检测到的物体都感兴趣,而是只对原始文本中出现的object感兴趣。
首先,作者把token的最大数量设置为256。对于每一个与GT匹配的预测框,模型被训练用来预测在所有token位置上的分布。上图展示了一个例子,猫的预测框被训练来预测前两个单词的分布,下图展示了该例子soft token prediction loss的可视化结果。
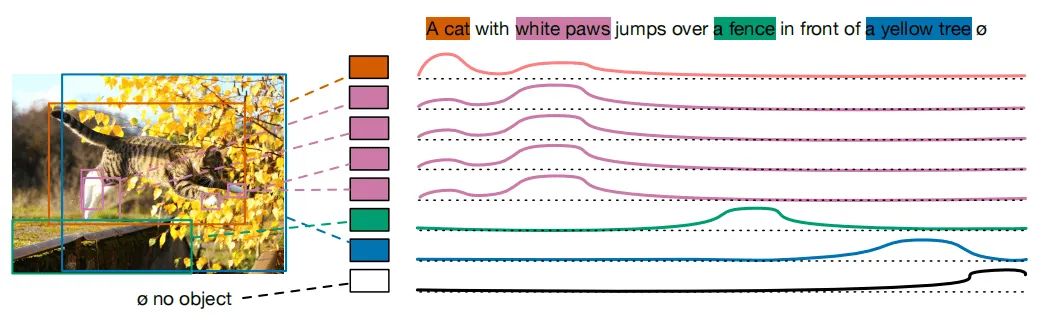
文本与图像是“多对多”的关系,文本中的几个单词可以对应于图像中的同一对象,相反,几个对象可以对应于同一文本。
Contrastive alignment
soft token prediction loss是用于目标和文本位置的对齐,contrastive alignment loss用于加强视觉和文本embedded特征表示的对齐,确保对齐的视觉特征表示和语言特征表示在特征空间上是比较接近的。这个损失函数不是作用于位置,而是直接作用在特征层面,提高对应样本之间的相似度。
这个损失函数采用了参考了对比学习中的InfoNCE,可以表示成下面的公式:
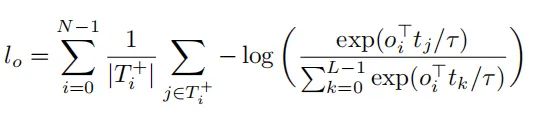
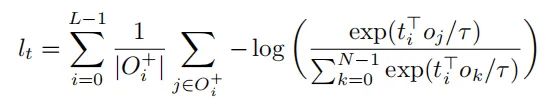
在实验中,作者采用了这两个损失函数的平均值当做contrastive alignment loss。
4.实验
4.1. Synthetic Images
上图为在 CLEVR数据集上训练示意图
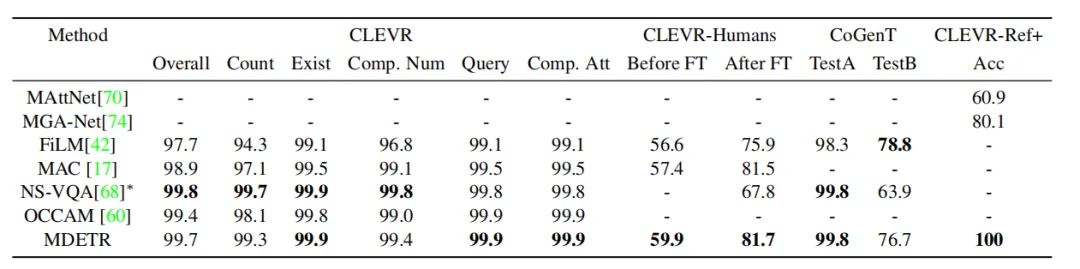
可以看出,本文的方法超过了不使用额外监督信号的方法,和NS-VQA(采用了额外的监督信号)性能相似。
4.2. Natural Images

对于句子“the person in the grey shirt with a watch on their wrist. the other person wearing a blue sweater. the third person in a gray coat and scarf.”,模型能够准确地根据描述,检测出不同属性的三个人。
4.3. Phrase grounding
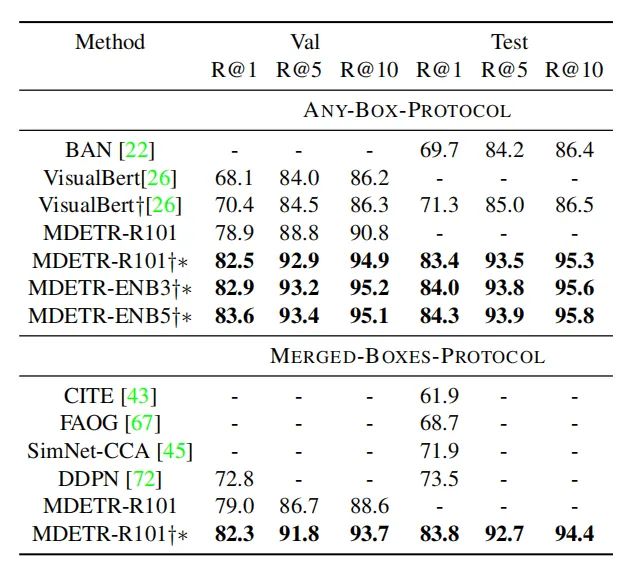
Flickr30k实体数据集上,Phrase grounding任务的结果
4.4. Referring expression comprehension
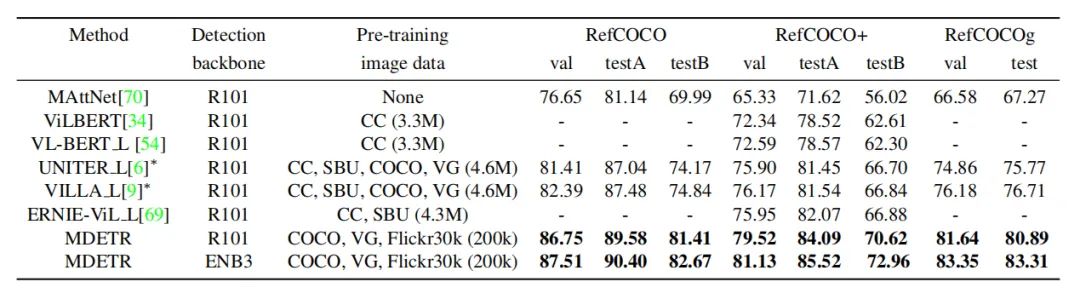
上表为REC的准确性结果,可以看出本文的方法相比于其他预训练方法有较大的性能优势。
4.5. Visual Question Answering
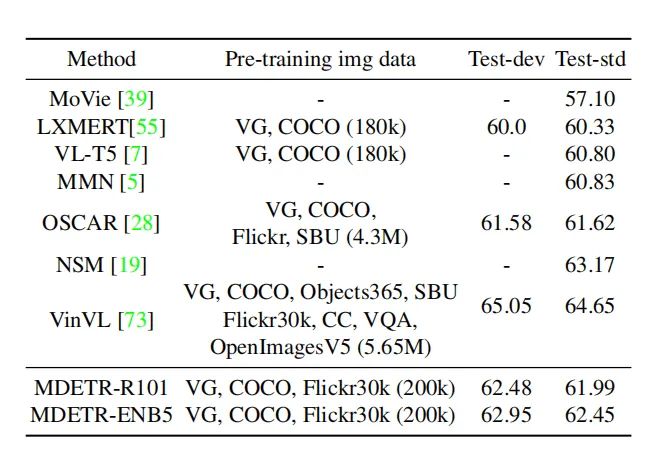
在GQA数据集上VQA结果 ,可以看出MDETR也能取得比较好的结果。
4.6. Few-shot transfer for long-tailed detection
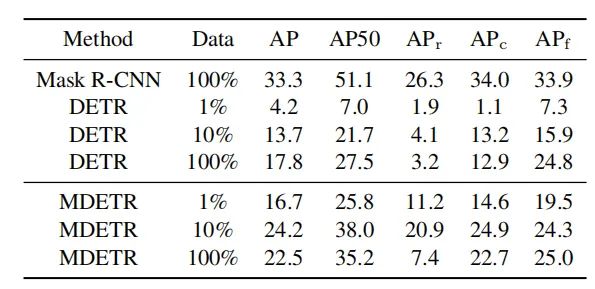
相比于DETR,在少样本的长尾数据集检测任务上,MDETR也能取得比较好的效果。
5. 总结
本文提出了MDETR,一个完全可微的调制检测器。在各种数据集上,MDETR在多模态理解任务上都取得了不错的性能,并且在各种下游任务中也取得了非常好的性能。除此之外,本文的MDETR还去掉了用目标检测器来提取特征,使得各种任务的性能上限得到了提升,因为目标检测器一定程度上可能成为影响性能提升的瓶颈。
参考文献
[1]. Carion, Nicolas, et al. "End-to-end object detection with transformers." European Conference on Computer Vision . Springer, Cham, 2020.
本文亮点总结
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看