
菜鸟福利!Github 近1万 star,专门针对爬虫新手的开源项目,包含淘宝、微博等网站
菜鸟学Python
共 1791字,需浏览 4分钟
·
2020-12-25 01:38
点上方蓝色“菜鸟学Python”,选“星标”公众号
重磅干货,第一时间送到

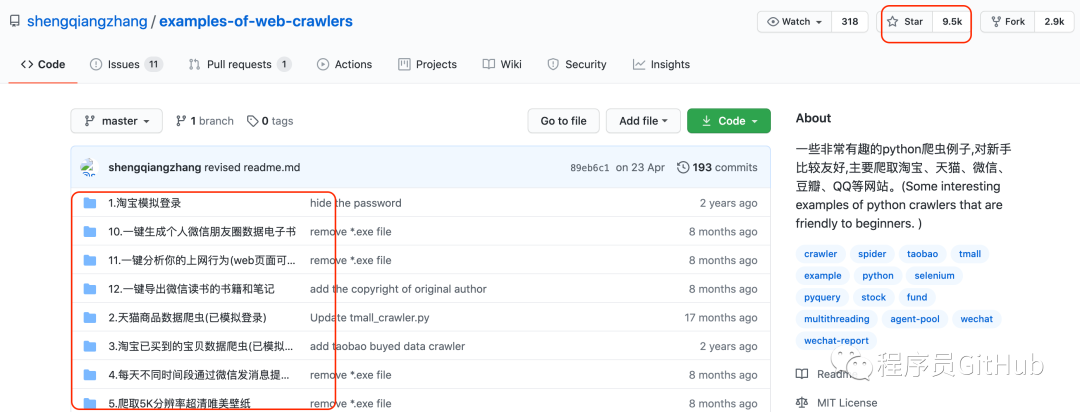
01.项目简介
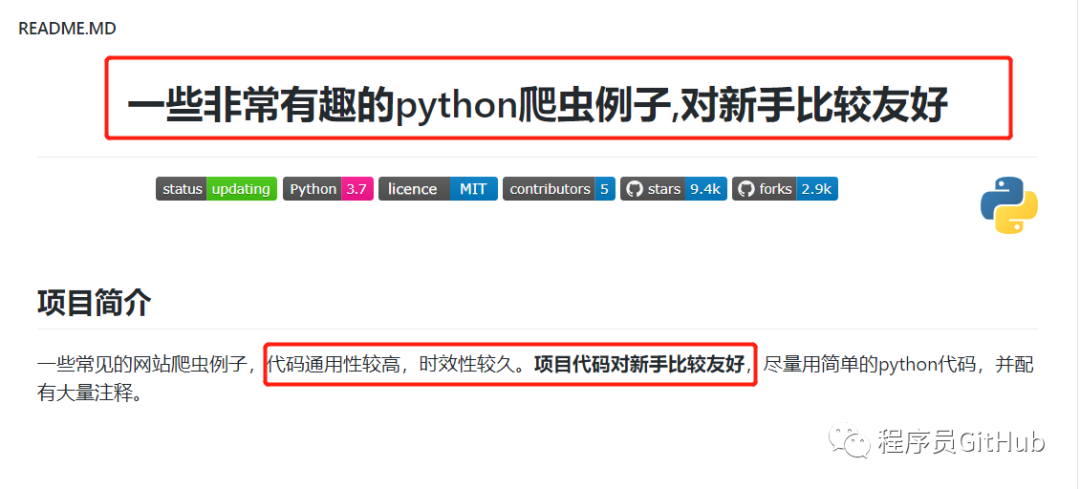
这位大神开源了很多爬虫的项目,几乎覆盖很多主流的网站,让人眼花缭乱,不信的话,我们来看一下,如下图所示:
可以看到,作者为大家提供了非常丰富的内容介绍,作者不仅仅告诉大家程序是如何编写的,而且还配上了GIF的动图展示。为了更好的展现作者的项目用途,接下来,小编将利用作者提供的程序,来实际运行一下,看一下程序的效果如何。
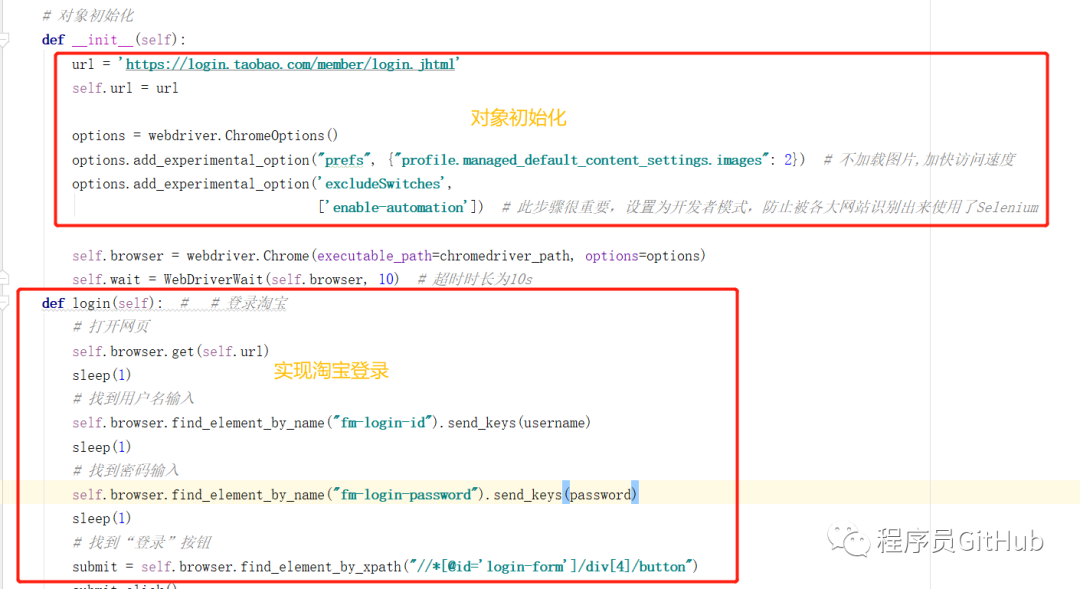
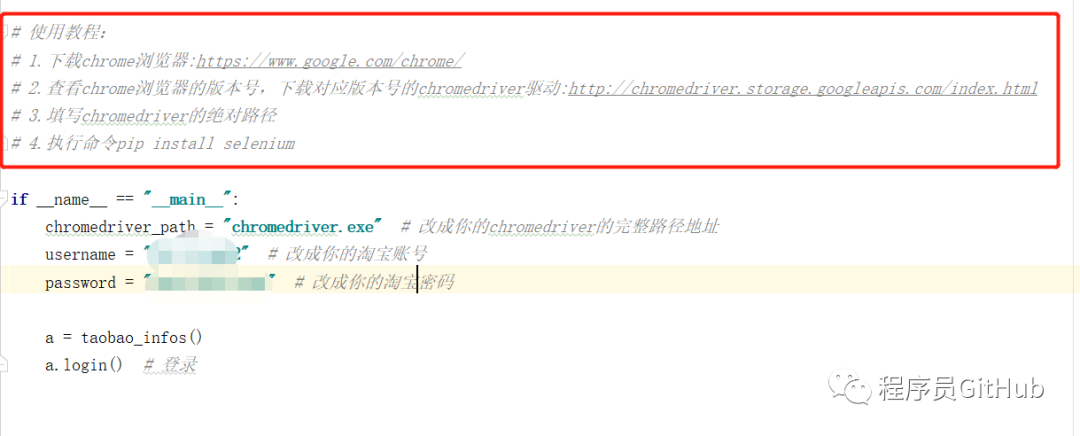
03.爬取豆瓣排行榜电影数据(含GUI界面版)
该项目中还提供了包含GUI界面的程序,同时作者也给出了具体的操作流程。
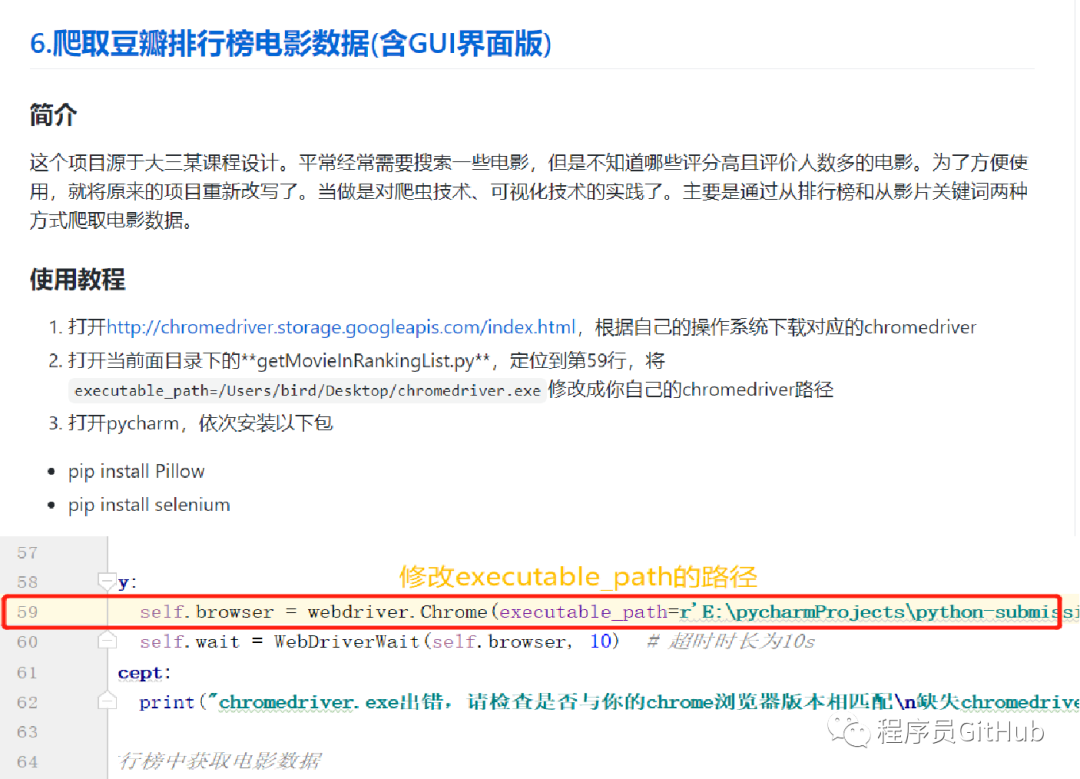
大家只需要按照指示,将getMovieInRankingList.py文件中的第59行中的executable_path改成自己的chromedriver路径即可。然后点击运行main.py程序即可,其运行效果如下图所示。
04.总结
以上就是今天小编同大家分享的关于examples-of-web-crawlers项目的内容,大家可以下载该项目,然后进行学习,来提升自己的爬虫能力。当然,由于网页变化速度极快,程序可能有存在报错的可能,需要大家耐心的调试,在调试中提升自己的能力。
推荐阅读:
这个GitHub 1400星的Git魔法书火了,斯坦福校友出品丨有中文版 贼 TM 好用的 Java 工具类库 超全Python IDE武器库大总结,优缺点一目了然! 秋招来袭!GitHub28.5颗星!这个汇聚阿里,腾讯,百度,美团,头条的面试题库必须安利! 收获10400颗星!这个Python库有点黑科技,竟然可以伪造很多'假'的数据! 牛掰了!这个Python库有点逆天了,竟然能把图片,视频无损清晰放大!
点这里,获取一大波福利


评论