
创建自己的人脸识别系统
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
专业提示:如果你想快速完成任务,请跳过理论部分,直接进入第2部分。
Facenet i. Facenet是什么? ii. Facenet是如何工作的? iii. 三重损失 我们开始构建吧! i. 先决条件 ii. 下载数据 iii. 下载Facenet iv. 对齐 v. 获得预先训练的模型 vi. 用我们的数据训练模型 vii. 在视频源上测试我们的模型 缺点 结论 参考文献
Facenet
Facenet是什么?
Facenet是如何工作的?
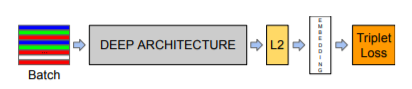
三重损失
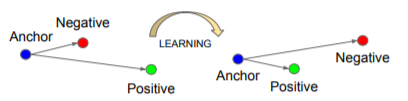
锚:一个随机的人的人脸。 正图:同一个人的另一张人脸。 负图:另一个人的人脸。
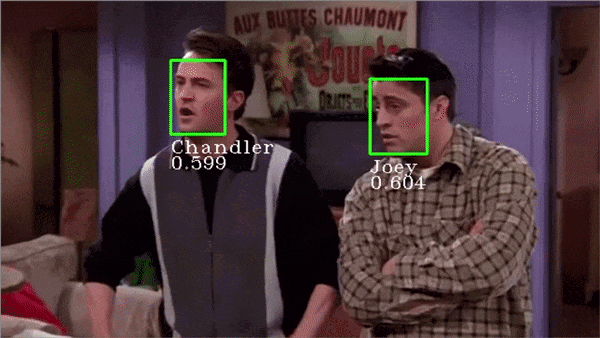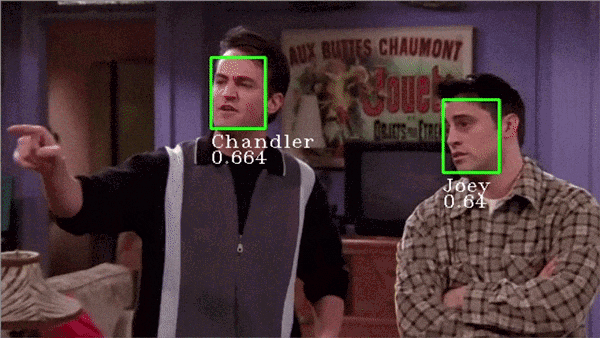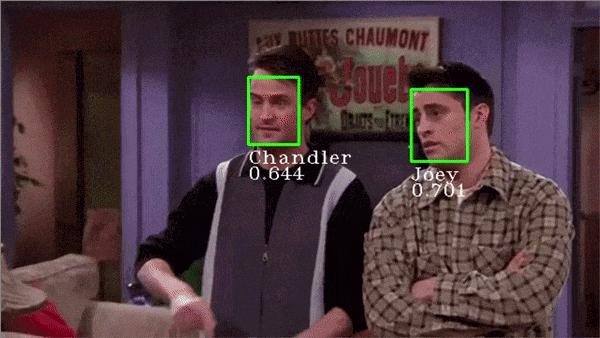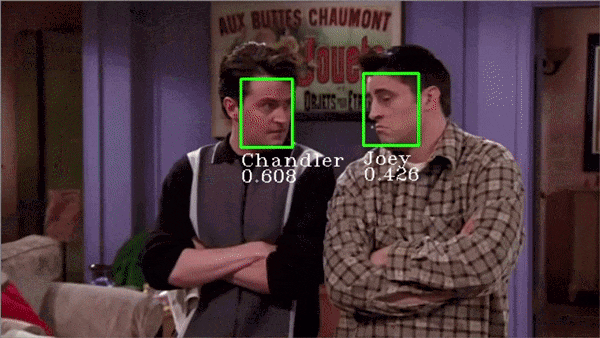
最精彩的部分开始了!我们可以使用Facenet为我们自己选择的人脸创建嵌入,然后训练支持向量机(Support Vector Machine)对这些嵌入进行分类,让我们开始建立一个自定义的人脸识别程序吧!
Github存储库 https://github.com/AssiduousArchitect/face-recognition
先决条件
tensorflow==1.7 scipy scikit-learn opencv-python h5py matplotlib Pillow requests psutil
下载数据

下载Facenet
Facenet repo下载地址 https://github.com/davidsandberg/facenet
对齐
python src/align_dataset_mtcnn.py \./Dataset/Friends/raw \./Dataset/Friends/processed \--image_size 160 \--margin 32 \--random_order \--gpu_memory_fraction 0.25

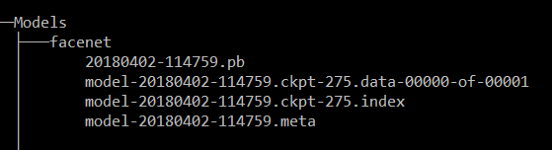
获得预先训练的模型
https://drive.google.com/file/d/1EXPBSXwTaqrSC0OhUdXNmKSh9qJUQ55-/view
用我们的数据训练模型
python src/classifier.py TRAIN \./Dataset/Friends/processed \./Models/facenet/20180402-114759.pb \./Models/Friends/Friends.pkl \--batch_size 1000
在视频源上测试我们的模型
except: pass
python src/faceRec.py --path ./Dataset/Friends/friends.mp

系统总是试图将每个人脸都匹配到一个给定的身份中。如果屏幕上出现新人脸,系统将为其分配一个或另一个身份,这个问题可以通过仔细选择一个阈值来解决。 身份的混淆。在上面的gif中,你可以观察到Joey和Chandler之间的预测有时是波动的,而且置信度得分也很低。需要使用更多图像训练模型来解决此问题。 无法在一定距离识别人脸(如果距离很远使得人脸看起来很小)。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论